Diagnóstico de incidencias mediante la revisión de configuraciones y métricas
Es posible que al supervisar el rendimiento de Azure Load Balancer se tenga un conocimiento temprano de los posibles errores. Azure Monitor proporciona muchas métricas importantes que se usan para examinar las tendencias del rendimiento de Load Balancer. También puede desencadenar alertas si una o varias máquinas virtuales no superan las solicitudes de sondeo de estado.
En el escenario de ejemplo, se va a supervisar el rendimiento del sistema de carga equilibrada para garantizar que el rendimiento cumple los requisitos. Si el rendimiento disminuye y empiezan a producirse errores en las conexiones a las máquinas virtuales, deberá solucionar los problemas del sistema para determinar las causas y corregir el problema. Al final de esta unidad, podrá hacer lo siguiente:
- Describir las métricas disponibles para medir el rendimiento de un sistema de carga equilibrada.
- Usar la página estado de los recursos en Azure Portal para supervisar el mantenimiento del sistema.
- Explicar cómo resolver problemas comunes en un sistema de carga equilibrada.
Uso de Azure Monitor para solucionar problemas de Load Balancer
Con Azure Monitor, puede capturar y examinar los registros de diagnóstico y los datos de rendimiento de Load Balancer.
Supervisión de la conectividad
Puede consultar las métricas de Load Balancer en el panel Métricas de Azure Portal. Desde la perspectiva de solucionar los problemas de conectividad, las métricas más importantes son Disponibilidad de la ruta de acceso a datos y Situación de sondeo de estado.

Load Balancer prueba continuamente la disponibilidad de la ruta de acceso a la dirección IP de front-end, a través de las reglas de equilibrio de carga y el grupo de back-end, para las aplicaciones que se ejecutan en las máquinas virtuales. Esta información se registra como la métrica Disponibilidad de la ruta de acceso a datos. Al aplicar la métrica Promedio se muestra la disponibilidad media de un intervalo de tiempo determinado. Esta agregación es un valor entre 0 (sin disponibilidad) y 100, en que hay por lo menos una ruta de acceso correcta disponible desde la dirección IP de front-end a una máquina virtual del grupo de back-end.
La métrica Situación de sondeo de estado es similar, pero solo se aplica al sondeo de estado de las máquinas virtuales, en lugar de a la ruta de acceso completa a través de Load Balancer. De nuevo, la agregación Promedio para esta métrica genera un valor entre 0 (todas las máquinas virtuales tienen un estado incorrecto y no responden) y 100 (todas las máquinas virtuales responden al sondeo de estado).
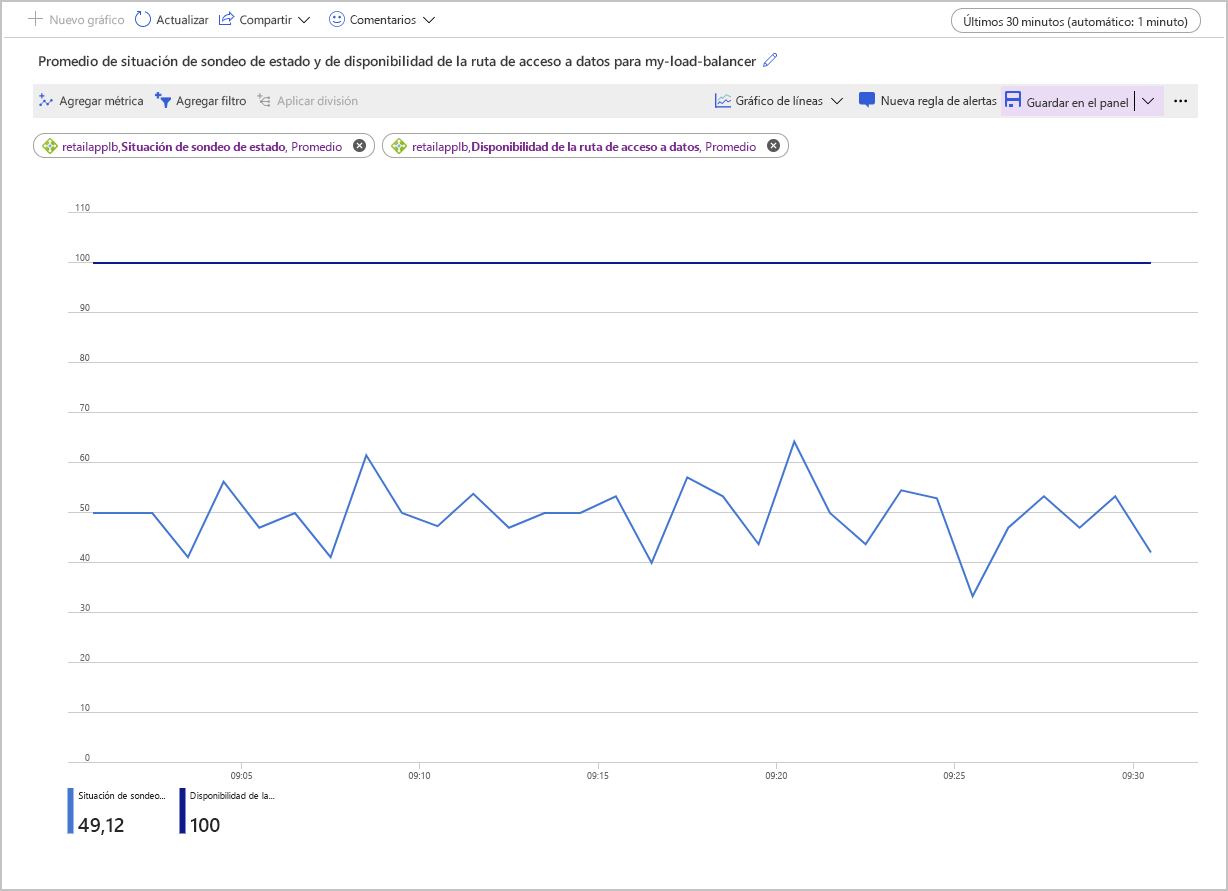
En la captura de pantalla siguiente se muestra el gráfico de la media de Disponibilidad de la ruta de acceso a datos y de Situación de sondeo de estado para un equilibrador de carga con dos máquinas virtuales en el grupo de back-end. Una de las máquinas no responde al sondeo de estado. La media de la Situación de sondeo de estado se muestra al mantener el puntero sobre la marca del 50 por ciento.
Otra manera de examinar estas métricas es usar la agregación Recuento. Este enfoque puede generar información adicional sobre posibles problemas con la configuración. En el ejemplo siguiente se muestran los gráficos para el recuento de las métricas Situación de sondeo de estado y Disponibilidad de la ruta de acceso a datos. En el gráfico se muestra el número de sondeos correctos que se han realizado a lo largo del tiempo.
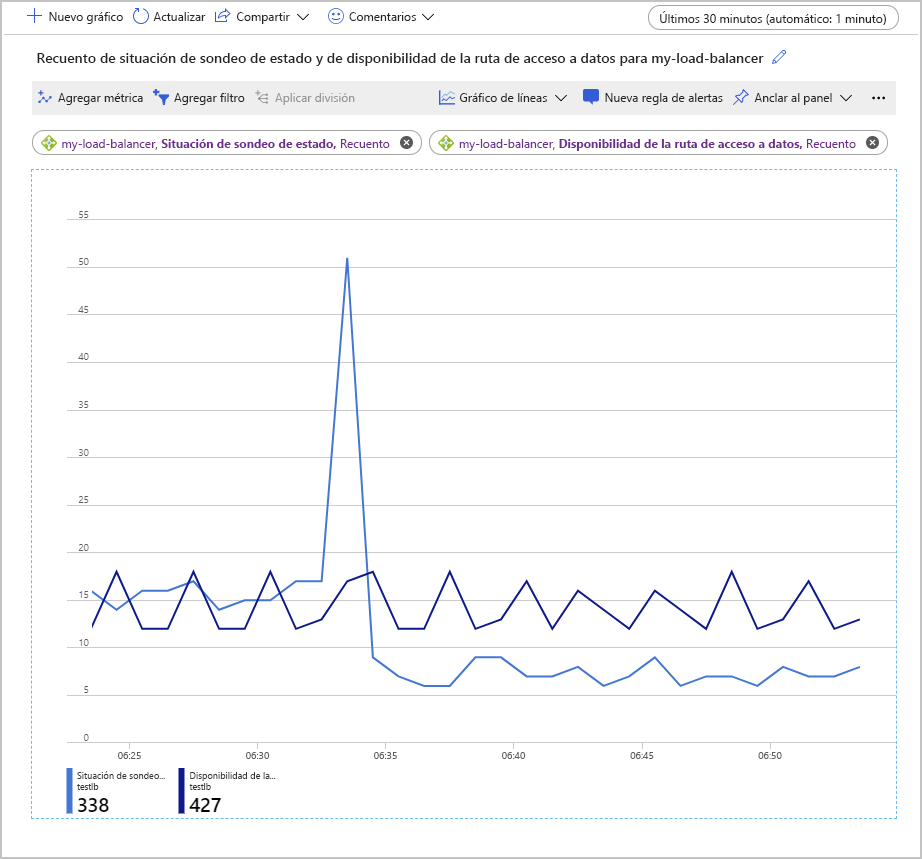
Un aspecto interesante de este gráfico es que el número de sondeos correctos de Disponibilidad de la ruta de acceso a datos se ha mantenido dentro de un rango uniforme. Sin embargo, el número de comprobaciones correctas de Situación de sondeo de estado ha alcanzado momentáneamente un máximo y, luego, se ha reducido a cerca de la mitad del valor que había antes de que se produjera el pico.
En el programa de instalación que se usa para generar este gráfico, el grupo de back-end solo lo formaban dos máquinas virtuales. A fin de simular un error, se ha detenido una de estas máquinas. La métrica Disponibilidad de la ruta de acceso a datos muestra que todavía es posible que una aplicación cliente se conecte a la aplicación que se ejecuta en la VM en funcionamiento restante. Sin embargo, Situación de sondeo de estado indica que el estado general del grupo de back-end está a solo la mitad de lo que estaba.
Vista del estado del servicio
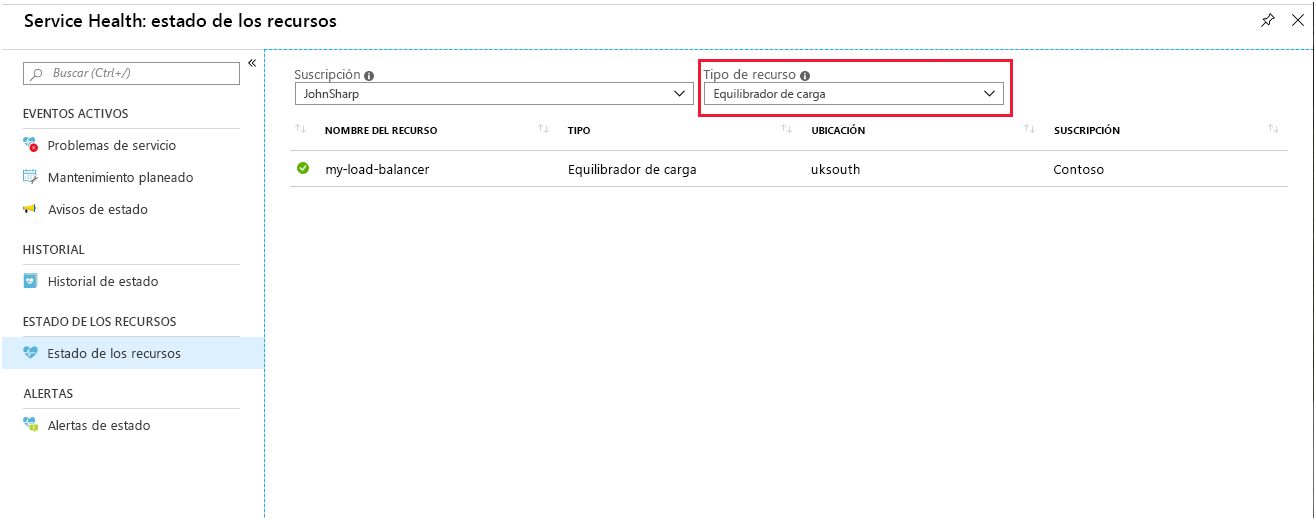
La página Estado de los recursos de Load Balancer informa del estado general del sistema. Se puede acceder a esta página en el portal desde Azure Monitor. Seleccione Service Health, Estado de los recursos y, luego, Equilibrador de carga como tipo de recurso.
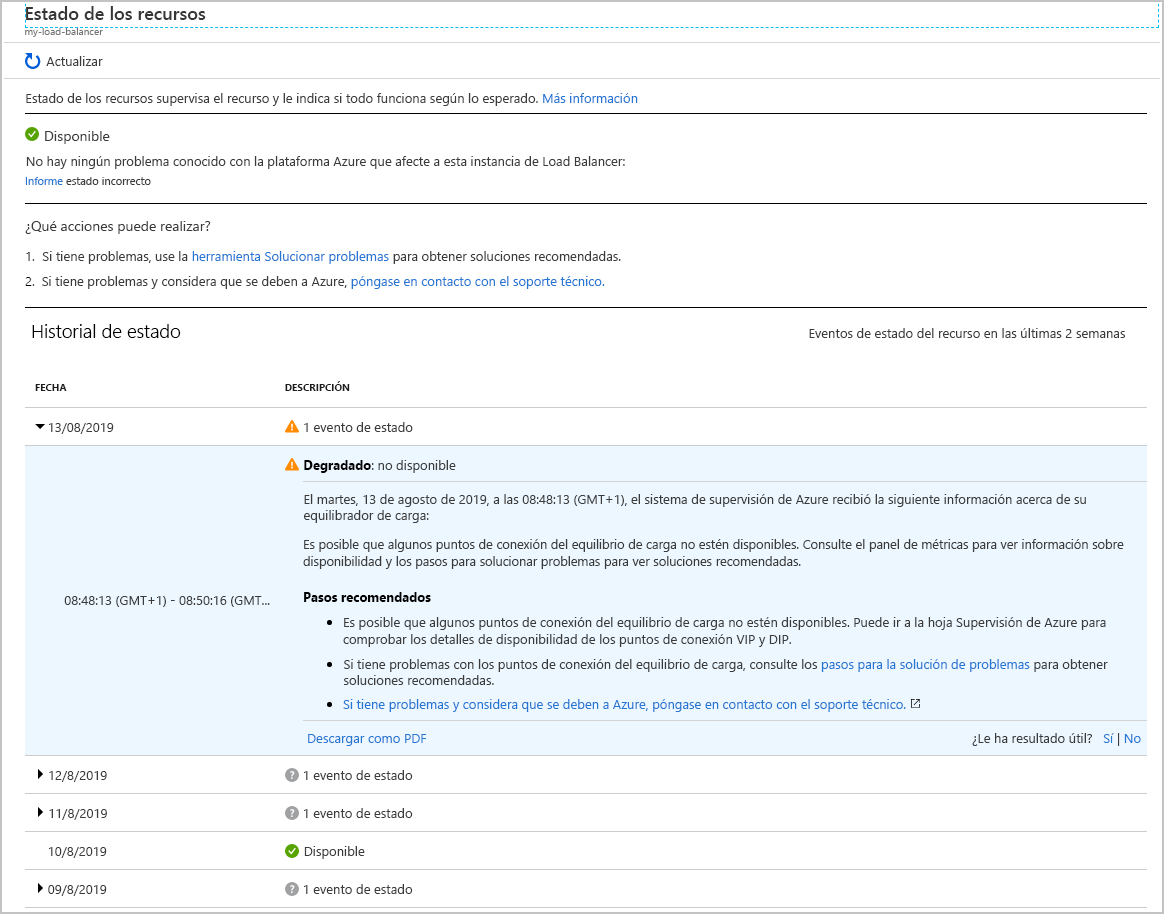
Seleccione el equilibrador de carga. Se mostrará un informe en que se detalla el historial de estado del servicio. Se puede expandir cualquier elemento del informe para ver los detalles. En la imagen siguiente se muestra el resumen que se genera al desconectarse una de las máquinas virtuales del grupo de back-end.
Supervisión de la carga de trabajo por máquina virtual
El resto de métricas disponibles para Load Balancer permiten realizar un seguimiento del número de bytes y paquetes de red que pasan a través de Load Balancer por front-end. Un front-end se define como una combinación de la dirección IP de Load Balancer, el protocolo que se usa para aceptar las solicitudes entrantes y el número de puerto que usa la regla de equilibrio de carga para conectarse a las máquinas virtuales. Estas métricas pueden servir para evaluar el rendimiento del sistema por máquina virtual activa.
En el gráfico siguiente se muestra la media del recuento de paquetes que fluyen a través de Load Balancer mientras se ejecuta una carga de trabajo de prueba de 500 usuarios simultáneos durante dos minutos. La carga de trabajo se ha ejecutado dos veces. En la primera, el grupo de back-end contenía dos instancias de máquina virtual. En la segunda ejecución, una de las máquinas virtuales se ha apagado (simulando un error).
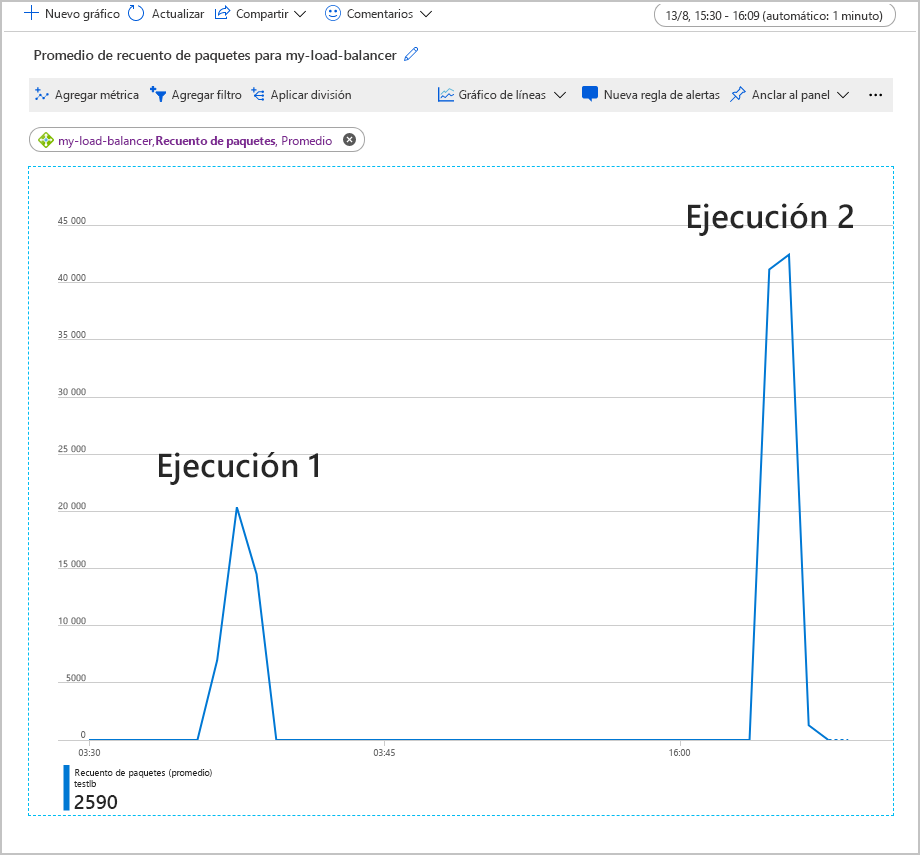
En este gráfico, se duplica la media del recuento de paquetes por front-end cuando se ha apagado la máquina virtual. Este volumen de trabajo puede sobrecargar la máquina virtual restante, lo que podría producir tiempos de respuesta prolongados y posibles tiempos de expiración.
Investigación y corrección de problemas comunes con Load Balancer
En esta sección se tratan algunos escenarios de error comunes con que puede encontrarse al utilizar Load Balancer. En cada escenario se resumen los síntomas de un error y cómo se podría resolver el problema.
Las máquinas virtuales que hay detrás de Load Balancer no responden al tráfico en el puerto de sondeo
Este problema podría ser el resultado de las incidencias siguientes:
Las máquinas virtuales del grupo de back-end no están escuchando en el puerto de sondeo correcto.
Compruebe que el sondeo de estado está configurado correctamente en Load Balancer. Asegúrese de que el código de aplicación que se ejecuta en cada máquina virtual responde adecuadamente a las solicitudes de sondeo. Deben devolver un mensaje de respuesta HTTP 200 (Correcto).
El NSG de la subred de la red virtual que hospeda las máquinas virtuales está bloqueando el puerto de sondeo.
Compruebe la configuración del NSG para la subred de la red virtual que contiene las máquinas virtuales. Asegúrese de que el NSG permite que el tráfico desde Load Balancer pase a través del puerto de sondeo de estado.
Está intentando acceder a Load Balancer desde la misma máquina virtual y la misma tarjeta de red virtual. Este problema no está relacionado con el sondeo, pero es un escenario de ruta de acceso a datos que no se admite.
Está intentando acceder al front-end de Load Balancer desde una máquina virtual del grupo de back-end.
Ambos elementos son incidencias de diseño de la aplicación. Evite el envío de solicitudes a la misma instancia de Load Balancer desde una máquina virtual del grupo de back-end.
El estado de una máquina virtual del grupo de back-end es incorrecto.
En este caso, la mayoría de las máquinas virtuales responde con normalidad, pero hay una o dos que no. Dado que algunas máquinas virtuales aceptan tráfico, es probable que el sondeo de estado esté configurado correctamente. El NSG de la subred no está bloqueando el puerto que utiliza el sondeo de estado. La causa de la incidencia son probablemente las máquinas virtuales que tienen un estado incorrecto. Este problema puede deberse a que las máquinas virtuales son inaccesibles o están fuera de servicio, o a que hay una incidencia de aplicación en estas máquinas.
Siga los pasos que hay a continuación para determinar la causa del problema con una máquina virtual que tiene un estado incorrecto:
- Inicie sesión en una máquina virtual que tenga un estado incorrecto para comprobar que está activa. Compruebe que la máquina virtual puede responder a comprobaciones básicas como ping, RDP o solicitudes de ssh de otra máquina virtual del grupo de back-end.
- Si la máquina virtual está activa y es accesible, compruebe que la aplicación se está ejecutando.
- Ejecute el comando
netstat -any compruebe que los puertos que usa el sondeo de estado y la aplicación se muestran como LISTENING.
Errores de configuración en Load Balancer
Load Balancer requiere que configure correctamente las reglas de enrutamiento que dirigen el tráfico entrante del front-end al grupo de back-end. Si falta una regla de enrutamiento o no está configurada correctamente, se quita el tráfico que llega al front-end. Una vez que se quita el tráfico, la aplicación se notifica a los clientes como inaccesibles.
Valide la ruta a través de Load Balancer desde el front-end hasta el grupo de back-end. Se pueden utilizar herramientas como Ping, TCPing y netsh, que están disponibles para Windows y Linux. También puede usar psping en Windows. En las secciones siguientes se explica cómo utilizar estas herramientas.
Uso de ping
El comando ping prueba la conectividad de ping a través de un punto de conexión mediante el protocolo ICMP. Para comprobar que hay disponible una ruta entre el cliente y una máquina virtual a través de Load Balancer, ejecute el comando siguiente. Reemplace la <dirección IP> por la dirección de la instancia de Load Balancer.
ping -n 10 <ip address>
| Switch | Descripción |
|---|---|
| -n | Este modificador especifica el número de solicitudes de ping que se van a enviar. |
Habitualmente, el resultado tiene el aspecto siguiente:
ping -n 10 nn.nn.nn.nn
Pinging nn.nn.nn.nn with 32 bytes of data:
Reply from nn.nn.nn.nn: bytes=32 time=34ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Ping statistics for nn.nn.nn.nn:
Packets: Sent = 10, Received = 10, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 29ms, Maximum = 34ms, Average = 30ms
Uso de PsPing
Con el comando PsPing se comprueba la conectividad de ping a través de un punto de conexión. Este comando también mide la latencia y la disponibilidad de ancho de banda para un servicio. Para comprobar que hay disponible una ruta entre el cliente y una máquina virtual a través de Load Balancer, ejecute el comando siguiente. Reemplace <ip address> y <port> por la dirección IP y el puerto de front-end de la instancia de Load Balancer.
psping -n 100 -i 0 -q -h <ip address>:<port>
| Marca | Descripción |
|---|---|
| -n | Especifica el número de pings que se van a hacer. |
| -i | Indica el intervalo, en segundos, entre las iteraciones. |
| -q | Suprime la salida durante los pings. Solo se muestra un resumen al final. |
| -h | Imprime un histograma que muestra la latencia de las solicitudes. |
Habitualmente, el resultado tiene el aspecto siguiente:
TCP connect to nn.nn.nn.nn:nn:
101 iterations (warmup 1) ping test: 100%
TCP connect statistics for nn.nn.nn.nn:nn:
Sent = 100, Received = 100, Lost = 0 (0% loss),
Minimum = 7.48ms, Maximum = 9.08ms, Average = 8.30ms
Latency Count
7.48 3
7.56 2
7.65 2
7.73 2
7.82 7
7.90 4
7.98 4
8.07 6
8.15 9
8.24 9
8.32 11
8.40 7
8.49 11
8.57 12
8.66 3
8.74 2
8.82 2
8.91 1
8.99 2
9.08 1
Uso de tcping
La utilidad tcping es similar a ping, excepto que funciona a través de una conexión TCP en lugar de ICMP. Use tcping como se indica a continuación:
tcping <ip address> <port>
Habitualmente, el resultado tiene el aspecto siguiente:
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.042ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.810ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.266ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.181ms
Ping statistics for nn.nn.nn.nn:nn
4 probes sent.
4 successful, 0 failed. (0.00% fail)
Approximate trip times in milli-seconds:
Minimum = 9.042ms, Maximum = 9.810ms, Average = 9.325ms
Uso de netsh
La utilidad netsh es una herramienta de configuración de red de uso general. Use el comando trace en netsh para capturar el tráfico. A continuación, analícelo con una herramienta como Wireshark. Use netsh trace para examinar los paquetes de red que psping envía y recibe al probar la conectividad a través de Load Balancer, tal y como se indica a continuación:
Inicie como administrador un seguimiento de red desde un símbolo del sistema. En el ejemplo siguiente se realiza un seguimiento del tráfico de cliente de Internet (solicitudes HTTP) con origen y destino la dirección IP especificada. Reemplace <ip address> por la dirección de la instancia de Load Balancer. Los datos de seguimiento se escriben en un archivo denominado trace.etl.
netsh trace start ipv4.address=<ip address> capture=yes scenario=internetclient tracefile=trace.etlEjecute psping para probar la conectividad a través de Load Balancer.
psping -n 100 -i 0 -q <ip address>:<port>Detenga el seguimiento.
netsh trace stopEste comando tardará unos minutos en completarse, ya que correlaciona y combina información mientras crea el archivo de salida de seguimiento.
Inicie Wireshark y abra el archivo de seguimiento.
Agregue este filtro al seguimiento. Reemplace <nn> por el número de puerto de front-end de Load Balancer.
TCP.Port==80 or TCP.Port==<nn>Agregue el origen y destino de la solicitud HTTP como campos a la salida del seguimiento.
Examine los mensajes de seguimiento:
- Si no hay ningún paquete entrante para Load Balancer, es probable que haya una incidencia de seguridad de red o de enrutamiento definido por el usuario.
- Si no se devuelve ningún paquete saliente al cliente, probablemente haya una incidencia de configuración de la aplicación o de enrutamiento definido por el usuario.
El firewall de la máquina virtual o el NSG están bloqueando el puerto
Si la red y Load Balancer están configurados correctamente, la máquina virtual está activa y la aplicación se está ejecutando, el firewall o la configuración del NSG de las máquinas virtuales podrían bloquear el puerto usado por el sondeo de estado o la aplicación. Siga estos pasos para determinar si este es el caso:
Si hay un firewall en la máquina virtual, podría estar bloqueando las solicitudes en los puertos que usan el sondeo de estado y la aplicación. Valide la configuración del firewall en el host para garantizar que permite el tráfico en los puertos que usan el sondeo de estado y la aplicación.
Compruebe que cualquier NSG del NIC de la máquina virtual permite la entrada y salida en los puertos necesarios. Busque una regla Denegar todo en el NSG del NIC de la máquina virtual que tenga mayor prioridad que la regla predeterminada.
Importante
Puede asociar un NSG con una subred y los NIC individuales de las máquinas virtuales de la subred. Es posible que haya configurado el NSG de una subred para permitir que el tráfico pase a través de un puerto. Sin embargo, si el NSG de una máquina virtual cierra el mismo puerto, las solicitudes no pasarán a esa máquina virtual.
Limitaciones de Load Balancer
Load Balancer funciona en el nivel 4 de la pila de red ISO y no examina ni manipula de otro modo el contenido de los paquetes de red. No se puede usar para implementar enrutamiento basado en contenido.
Todas las solicitudes de clientes las finaliza una máquina virtual en el grupo de back-end. Load Balancer es invisible para los clientes. Si no hay ninguna máquina virtual disponible, se produce un error en la solicitud de cliente. Las aplicaciones cliente no se pueden comunicar con el estado de Load Balancer ni de ninguno de sus componentes, ni interrogarlo de otro modo.
Si tiene que implementar el equilibrio de carga basado en el contenido de los mensajes, considere la posibilidad de usar Azure Application Gateway. También puede configurar un servidor web proxy para controlar las solicitudes entrantes de clientes y dirigirlas hacia máquinas virtuales concretas.