Creación de particiones de archivos de datos
La creación de particiones es una técnica de optimización que permite a Spark maximizar el rendimiento en los nodos de trabajo. Se pueden lograr más mejoras de rendimiento al filtrar datos en consultas mediante la eliminación de E/S de disco innecesarias.
Creación de particiones del archivo de salida
Para guardar un objeto DataFrame como un conjunto de archivos con particiones, use el método partitionBy al escribir los datos.
En el ejemplo siguiente se crea un campo Year derivado. A continuación, lo usa para crear particiones de los datos.
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
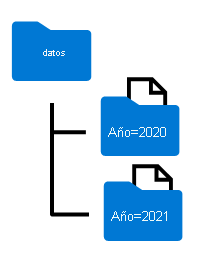
Los nombres de carpeta generados al crear particiones de un objeto DataFrame incluyen el nombre y el valor de la columna de partición en un formato column=value, como se muestra aquí:
Nota:
Puede crear particiones de los datos mediante varias columnas, lo que da como resultado una jerarquía de carpetas para cada clave de partición. Por ejemplo, podría crear particiones del orden del ejemplo por año y mes, de modo que la jerarquía de carpetas incluya una carpeta para cada valor de año, que a su vez contenga una subcarpeta para cada valor de mes.
Filtrado de archivos Parquet en una consulta
Al leer datos de archivos Parquet en un objeto DataFrame, tiene la posibilidad de extraer datos de cualquier carpeta dentro de las carpetas jerárquicas. Este proceso de filtrado se realiza con el uso de valores explícitos y caracteres comodín en los campos con particiones.
En el ejemplo siguiente, el código siguiente extraerá los pedidos de ventas, que se realizaron en 2020.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
Nota
Las columnas de partición especificadas en la ruta de acceso del archivo se omiten en el objeto DataFrame resultante. Los resultados generados por la consulta de ejemplo no incluyen una columna Year, ya que todas las filas son de 2020.