Redes neuronal convolucionales
Si bien puede usar modelos de aprendizaje profundo para cualquier tipo de aprendizaje automático, resultan especialmente útiles para trabajar con datos que constan de grandes matrices de valores numéricos, como imágenes. Los modelos de aprendizaje automático que funcionan con imágenes son la base de una inteligencia artificial de área denominada Computer Vision. Además, las técnicas de aprendizaje profundo han impulsado avances asombrosos en esta área durante los últimos años.
El motivo del éxito del aprendizaje profundo en esta área es un tipo de modelo denominado red neuronal convolucional, CNN. Por lo general, una CNN funciona extrayendo características de las imágenes y enviándolas a una red neuronal completamente conectada para generar una predicción. Las capas de extracción de características de la red reducen la cantidad de características en la matriz potencialmente enorme de valores de píxeles individuales a un conjunto más pequeño de características que ayuda a la predicción de etiquetas.
Capas de una CNN
Las CNN constan de varias capas, cada una de las cuales realiza una tarea específica en la extracción de características o la predicción de etiquetas.
Capas convolucionales
Uno de los tipos principales de capas es la capa convolucional, que extrae características importantes de las imágenes. Una capa convolucional funciona aplicando un filtro a las imágenes. El filtro está definido por un kernel que consta de una matriz de valores de ponderación.
Por ejemplo, un filtro de 3x3 podría definirse de la manera siguiente:
1 -1 1
-1 0 -1
1 -1 1
Una imagen también es simplemente una matriz de valores de píxeles. Para aplicar el filtro, debe "superponerlo" en una imagen y calcular una suma ponderada de los valores de píxeles de la imagen correspondientes bajo el kernel del filtro. Luego, el resultado se asigna a la celda central de una sección correspondiente de 3×3 en una matriz de valores nueva que tiene el mismo tamaño que la imagen. Por ejemplo, supongamos que una imagen de 6x6 tiene los valores de píxeles siguientes:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Aplicar el filtro a la sección de 3x3 superior izquierda de la imagen funcionaría de la manera siguiente:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
El resultado se asigna al valor de píxel correspondiente en la matriz nueva como se indica a continuación:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Ahora el filtro se mueve (se convoluciona). Por lo general, se utiliza un tamaño de paso de 1 (es decir, se desplaza un píxel a la derecha) y se calcula el valor para el píxel siguiente.
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Ahora podemos rellenar este valor de la matriz nueva.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
El proceso se repite hasta que se aplica el filtro en todas las secciones de 3x3 de la imagen a fin de generar una matriz de valores nueva como la siguiente:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Debido al tamaño del kernel de filtro, no se pueden calcular los valores de los píxeles del borde; por tanto, solo se suele aplicar un valor de relleno (a menudo, 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
La salida de la convolución generalmente se pasa a una función de activación. A menudo, esta es una función de Unidad lineal rectificada (ReLU) que garantiza que los valores negativos se establezcan en 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
La matriz resultante es una asignación de características de valores de características que se puede usar para entrenar un modelo de Machine Learning.
Nota: Los valores en la asignación de características pueden ser mayores que el valor máximo de un píxel (255). Por lo tanto, si desea visualizar la asignación de características, debería normalizar los valores de característica entre 0 y 255.
En la animación siguiente, se muestra el proceso de convolución.

- Se pasa una imagen a la capa convolucional. En este caso, la imagen es una forma geométrica simple.
- La imagen consta de una matriz de píxeles con valores entre 0 y 255 (para imágenes de color, habitualmente es una matriz tridimensional con valores para los canales rojo, verde y azul).
- En general, un kernel de filtro se inicializa con ponderaciones aleatorias. En este ejemplo, se eligieron valores que resaltan los posibles efectos de un filtro en los valores de los píxeles. Sin embargo, en una CNN real, las ponderaciones iniciales normalmente se generarían en función de una distribución gaussiana aleatoria. Este filtro se usará para extraer una asignación de características de los datos de la imagen.
- El filtro se convoluciona en la imagen, calculando los valores de las características al aplicar una suma de las ponderaciones multiplicada por sus valores correspondientes de píxeles en cada posición. Se aplica una función de activación ReLU para asegurarse de que los valores negativos estén establecidos en 0.
- Después de la convolución, la asignación de características contiene los valores extraídos de las características, los que a menudo enfatizan los atributos visuales clave de la imagen. En este caso, la asignación de características resalta los bordes y las esquinas del triángulo de la imagen.
Por lo general, una capa convolucional aplica varios kernels de filtro. Cada filtro genera una asignación de características diferente y todas estas asignaciones se pasan a la capa siguiente de la red.
Agrupación de capas
Después de extraer los valores de las características de las imágenes, se usan capas de agrupación (o submuestreo) para disminuir la cantidad de valores de características a la vez que se conservan las características diferenciales clave que se han extraído.
Uno de los tipos de agrupación más comunes es la agrupación máxima en la que se aplica un filtro a la imagen y solo se conserva el valor de píxel máximo dentro del área de filtro. Por ejemplo, si se aplica un kernel de agrupación de 2x2 a sección siguiente de una imagen, se generaría el resultado 155.
0 0
0 155
Tenga en cuenta que el efecto del filtro de agrupación de 2x2 es reducir el número de valores de 4 a 1.
Al igual que con las capas convolucionales, las capas de agrupación funcionan aplicando el filtro a toda la asignación de características. En la animación siguiente se muestra un ejemplo de la agrupación máxima de una asignación de imágenes.

- La asignación de características extraída por un filtro en una capa convolucional contiene una matriz de valores de características.
- Se usa un kernel de agrupación para reducir la cantidad de valores de características. En este caso, el tamaño del kernel es 2x2, por lo que generará una matriz con un cuarto de la cantidad de valores de características.
- El kernel de agrupación se convoluciona en la asignación de características, conservando solo el valor de píxel más alto en cada posición.
Capas de anulación
Uno de los mayores desafíos en una CNN es evitar el sobreajuste. Aquí, el modelo resultante funciona bien con los datos de entrenamiento, pero no se puede generalizar bien a los datos nuevos con los que no se entrenó. Una técnica que puede usar para mitigar el sobreajuste es incluir capas en las que el proceso de entrenamiento elimina (o "anula") asignaciones de características de forma aleatoria. Esto puede parecer un poco contradictorio, pero es una manera eficaz de asegurarse de que el modelo no aprenda a depender demasiado de las imágenes de entrenamiento.
Otras técnicas que puede usar para mitigar el sobreajuste incluyen el volteo aleatorio, la creación de reflejo o la distorsión de las imágenes de entrenamiento a fin de generar datos que varíen entre las épocas de entrenamiento.
Capas de acoplamiento
Después de usar capas convolucionales y de agrupación para extraer las características destacadas de las imágenes, las asignaciones de características resultantes son matrices multidimensionales de valores de píxeles. Una capa de acoplamiento se usa para acoplar las asignaciones de características a un vector de valores que se puede usar como entrada para una capa totalmente conectada.
Capas totalmente conectadas
Por lo general, una CNN termina con una red completamente conectada en la que los valores de las características se transmiten a una capa de entrada, a través de una o más capas ocultas, y generan valores previstos en una capa de salida.
Una arquitectura básica de la CNN podría tener un aspecto similar al siguiente:
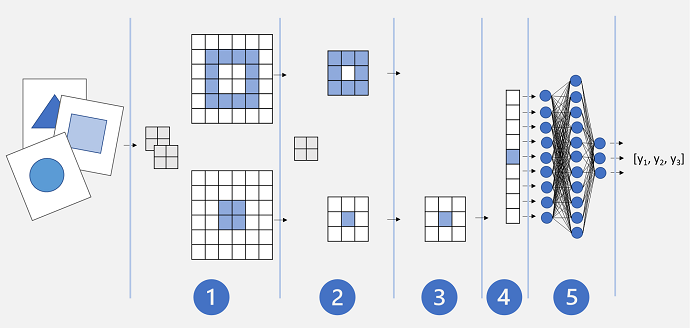
- Las imágenes se introducen en una capa convolucional. En este caso, hay dos filtros, por lo que cada imagen genera dos asignaciones de características.
- Las asignaciones de características se pasan a una capa de agrupación, en la que un kernel de agrupación de 2x2 disminuye el tamaño de las asignaciones de características.
- Una capa de anulación anula algunas de las asignaciones de características de manera aleatoria para ayudar a evitar el sobreajuste.
- Una capa de acoplamiento toma las matrices de asignaciones de características restantes y las acopla a un vector.
- Los elementos del vector se introducen en una red totalmente conectada, lo que genera las predicciones. En este caso, la red es un modelo de clasificación que predice las probabilidades de tres clases de imágenes posibles (triángulo, cuadrado y círculo).
Entrenamiento de un modelo de CNN
Al igual que lo que ocurre con cualquier red neuronal profunda, se entrena una CNN mediante la transferencia de lotes de datos de entrenamiento a través de varias épocas, ajustando los valores de ponderaciones y sesgos en función de la pérdida calculada para cada época. En el caso de una CNN, la retropropagación de ponderaciones ajustadas incluye ponderaciones de kernel de filtro que se usan en capas convolucionales, así como las ponderaciones que se utilizan en capas totalmente conectadas.