Introducción
La agrupación en clústeres es el proceso de agrupar objetos con objetos similares. Por ejemplo, en la imagen siguiente tenemos una colección de coordenadas 2D que se han agrupado en tres categorías: superior izquierda (amarillo), inferior (rojo) y superior derecha (azul).
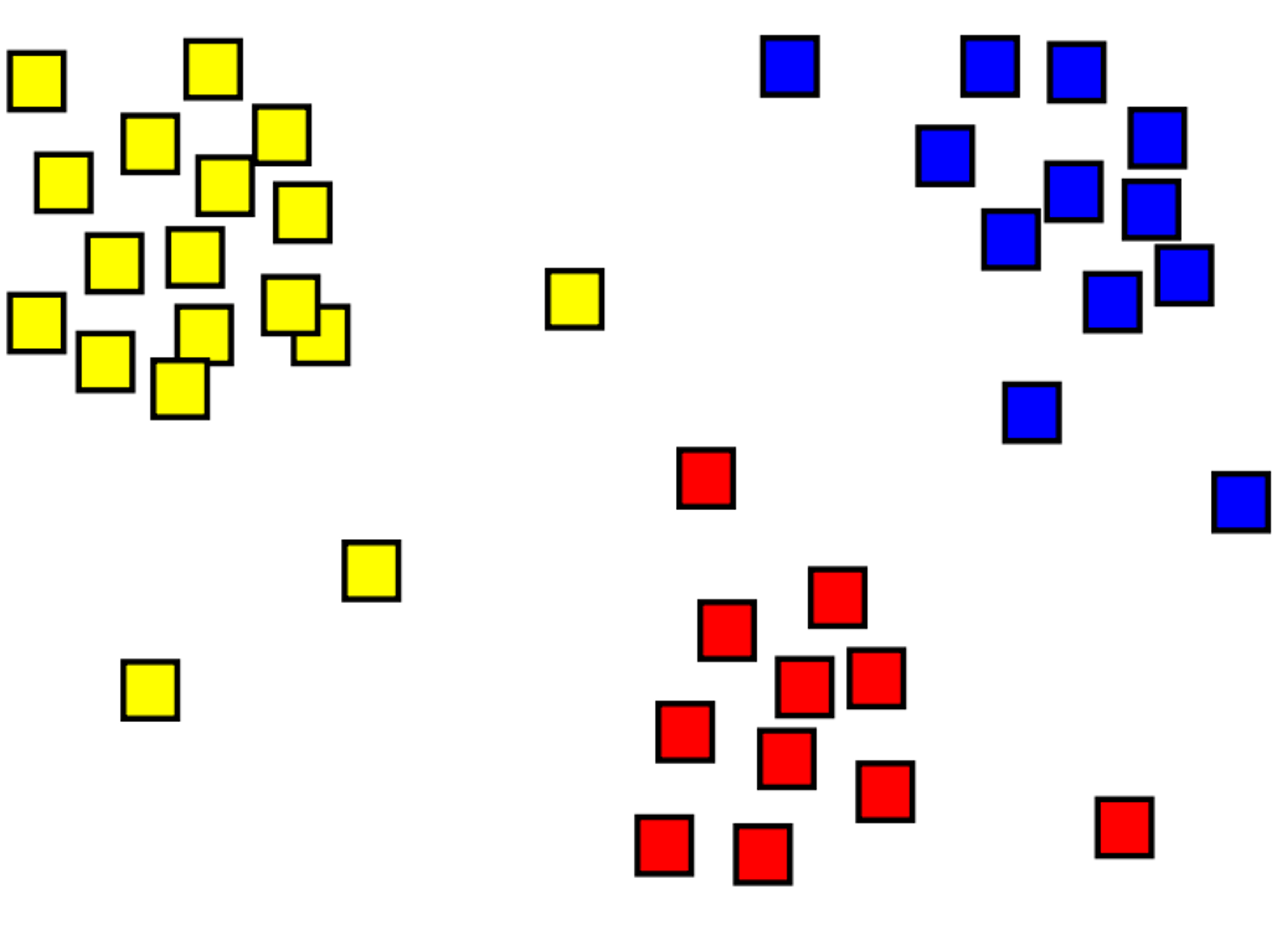
Una diferencia importante entre los modelos de agrupación en clústeres y clasificación es que la agrupación en clústeres es un método no supervisado, donde el entrenamiento se realiza sin etiquetas. Los modelos de agrupación en clústeres identifican ejemplos que tienen una colección similar de características. En la imagen anterior, los ejemplos que se encuentran en una ubicación similar se agrupan.
La agrupación en clústeres es común y útil para explorar nuevos datos en los que aún no se conocen patrones entre puntos de datos, como categorías de alto nivel. Se usa en muchos campos que necesitan etiquetar automáticamente datos complejos, incluido el análisis de redes sociales, la conectividad cerebral o el filtrado de correo no deseado, entre otros.