Conjuntos de datos de prueba y entrenamiento
Los datos que usamos para entrenar un modelo suelen denominarse conjunto de datos de entrenamiento. Ya lo hemos visto en acción. Por suerte, cuando usamos el modelo en el mundo real, después del entrenamiento, no sabemos con certeza cómo funcionará. Esta incertidumbre se debe a que es posible que nuestro conjunto de datos de entrenamiento sea diferente a los datos del mundo real.
¿Qué es el sobreajuste?
Un modelo se sobreajusta si funciona mejor en los datos de entrenamiento que en otros datos. El nombre hace referencia al hecho de que el modelo se ha ajustado tan bien que ha memorizado detalles del conjunto de entrenamiento en lugar de buscar reglas generales que se apliquen a otros datos. El sobreajuste es habitual, pero no es lo deseable. Al final y al cabo, solo nos importa lo bien que funciona nuestro modelo en datos del mundo real.
¿Cómo podemos evitar el sobreajuste?
Podemos evitar el sobreajuste de varias maneras. La manera más sencilla es tener un modelo más simple o usar un conjunto de datos que sea una representación mejorada de lo que se ve en el mundo real. Para comprender estos métodos, considere un escenario en el que los datos reales tengan este aspecto:
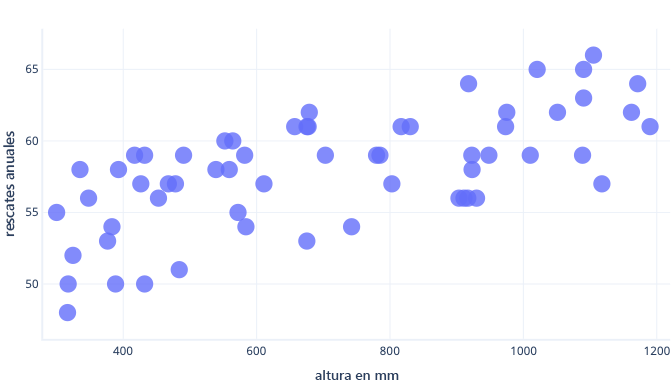
Sin embargo, supongamos que recopilamos información solo sobre cinco perros y la usamos como conjunto de datos de entrenamiento para ajustar una línea compleja. Si podemos hacerlo, podremos ajustarla muy bien:
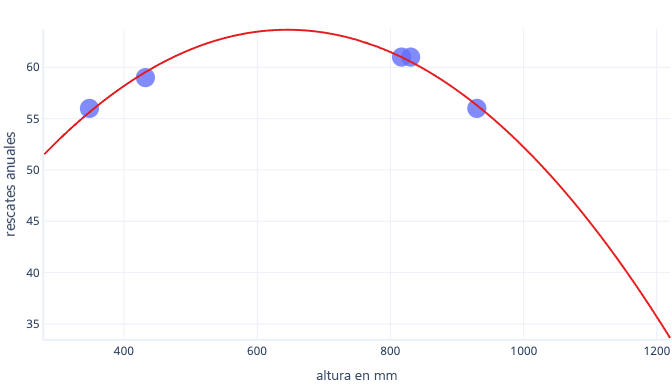
Sin embargo, cuando se use en el mundo real, veremos que realiza predicciones que resultarán incorrectas:
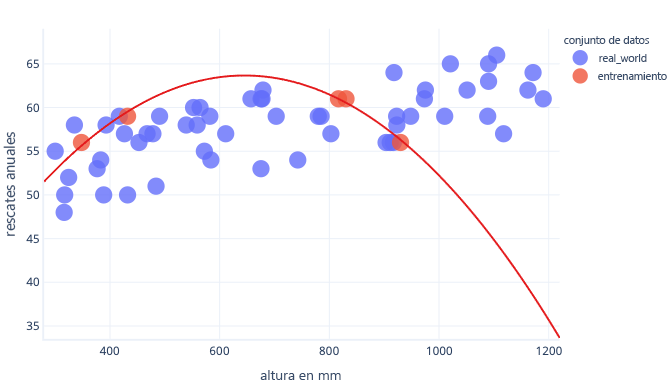
Si tenemos un conjunto de datos más representativo y un modelo más sencillo, la línea que ajustamos acaba haciendo mejores predicciones (aunque no perfectas):
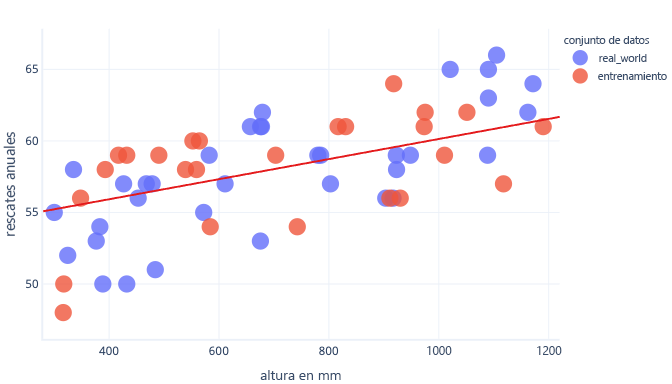
Una forma complementaria de evitar el sobreajuste es detener el entrenamiento después de que el modelo haya aprendido las reglas generales, pero antes de que el modelo esté sobreajustado. Sin embargo, para eso es necesario detectar cuándo estamos empezando a sobreajustar el modelo. Podemos hacerlo mediante un conjunto de datos de prueba.
¿Qué es un conjunto de datos de prueba?
Un conjunto de datos de prueba, también denominado conjunto de datos de validación, es un conjunto de datos similar al conjunto de datos de entrenamiento. De hecho, los conjuntos de datos de prueba normalmente se crean tomando un conjunto de datos grande y dividiéndolo. Una parte se denomina conjunto de datos de entrenamiento y la otra, conjunto de datos de prueba.
El trabajo del conjunto de datos de entrenamiento es entrenar el modelo; ya hemos visto el entrenamiento. El trabajo del conjunto de datos de prueba es comprobar el funcionamiento del modelo; no contribuye al entrenamiento directamente.
De acuerdo, pero ¿de qué sirve esto?
Un conjunto de datos de prueba sirve para dos cosas.
En primer lugar, si el rendimiento de prueba deja de mejorar durante el entrenamiento, podemos parar, ya que no tiene sentido continuar. Si continuamos, podemos terminar animando al modelo a obtener detalles sobre el conjunto de datos de entrenamiento que no están en el conjunto de datos de prueba, lo que da lugar al sobreajuste.
En segundo lugar, podemos usar un conjunto de datos de prueba después del entrenamiento. De esta forma, tendremos una idea de lo bien que funcionará el modelo final cuando vea datos "reales" que no haya visto antes.
¿Qué significa eso para las funciones de costo?
Cuando usamos conjuntos de datos de entrenamiento y de prueba, terminamos calculando dos funciones de costo.
La primera función de costo es usar el conjunto de datos de entrenamiento, como hemos visto antes. Esta función de costo se proporciona al optimizador y se usa para entrenar el modelo.
La segunda función de costo se calcula mediante el conjunto de datos de prueba. Se usa para comprobar cómo funciona el modelo en el mundo real. El resultado de la función de costo no se usa para entrenar el modelo. Para calcularlo, pausamos el entrenamiento, observamos el rendimiento del modelo en un conjunto de datos de prueba y, a continuación, reanudamos el entrenamiento.