Normalización y estandarización
El escalado de características es una técnica que cambia el intervalo de valores que tiene una característica. Esto permite a los modelos aprender de forma más rápida y sólida.
Normalización frente a estandarización
Normalización significa modificar la escala de los valores para que todos se ajusten a un intervalo determinado (normalmente de 0 a 1). Por ejemplo, si tuviera una lista de edades de personas de 0, 50 y 100 años, podría normalizarlas dividiendo las edades entre 100, de modo que los valores fueran 0, 0,5 y 1.
La estandarización es similar, pero, en su lugar, se resta la media de los valores y, después, se divide por la desviación estándar. Si no está familiarizado con la desviación estándar, no se preocupe. Significa que, después de la estandarización, el valor medio es 0 y aproximadamente el 95 % de los valores se encuentra entre -2 y 2.
Hay otras maneras de escalar los datos, pero sus matices van más allá de lo que necesitamos saber en este momento. Vamos a ver por qué aplicamos normalización o estandarización.
¿Por qué es necesario modificar la escala?
Hay muchas razones por las que normalizamos o estandarizamos los datos antes del entrenamiento. Estos conceptos se pueden comprender más fácilmente con un ejemplo. Supongamos que queremos entrenar un modelo para predecir si un perro trabajará bien en la nieve. Los datos se muestran en el siguiente grafo con puntos, y la línea de tendencia que intentamos encontrar se muestran con una línea continua:
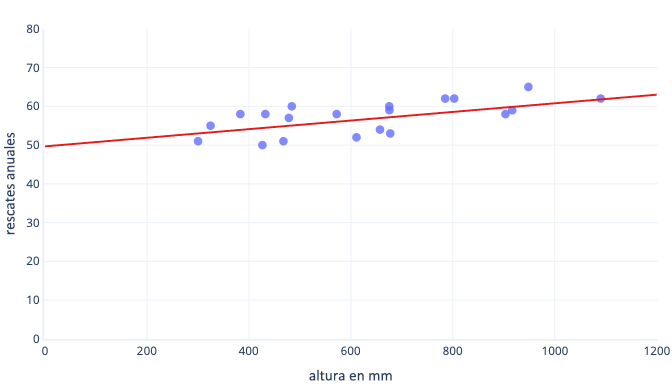
El escalado proporciona un mejor punto de partida para el aprendizaje
La línea óptima del grafo anterior tiene dos parámetros: la intersección, que es 50, la línea en x=0 y la pendiente, que es 0,01; cada 1000 milímetros aumentan los rescates en 10. Supongamos que comenzamos el entrenamiento con estimaciones iniciales de 0 para ambos parámetros.
Si nuestras iteraciones de entrenamiento modifican los parámetros en torno a 0,01 por iteración de media, se necesitarán al menos 5000 iteraciones antes de encontrar la intersección: 50 / 0,01 = 5000 iteraciones. La estandarización puede acercar esta intersección óptima a cero, lo que significa que se puede identificar mucho más rápido. Por ejemplo, si restamos la media de nuestra etiqueta (rescates anuales) y nuestra característica (altura), la intersección es -0,5, en lugar de 50, de modo que podremos encontrarla unas 100 veces más rápido.
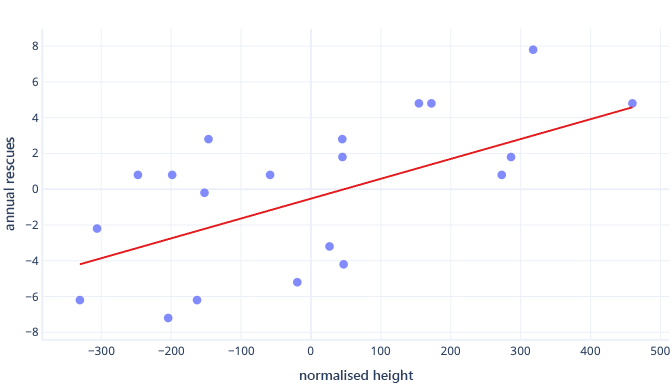
Hay otras razones por las que los modelos complejos pueden ser muy lentos de entrenar cuando la suposición inicial está lejos de la marca, pero la solución sigue siendo la misma: desplazar las características a algo más cercano a la suposición inicial.
La estandarización permite que los parámetros se entrenen a la misma velocidad
En los datos recién desplazados, tenemos un desplazamiento ideal de -0,5 y una pendiente ideal de 0,01. Aunque el desplazamiento ayuda a acelerar las cosas, sigue siendo mucho más lento entrenar el desplazamiento que entrenar la pendiente. Esto puede ralentizar las cosas y hacer que el entrenamiento sea inestable.
Por ejemplo, nuestras suposiciones iniciales de desplazamiento y pendiente son cero. Si cambiamos los parámetros en aproximadamente 0,1 en cada iteración, encontraremos el desplazamiento rápidamente, pero será muy difícil encontrar la pendiente correcta, ya que los aumentos de pendiente serán demasiado grandes (0 + 0,1 > 0,01) y pueden sobrepasar el valor ideal. Podemos reducir los ajustes, pero esto ralentizará el tiempo que se tarda en encontrar la intersección.
¿Qué ocurre si escalamos nuestra característica de altura?
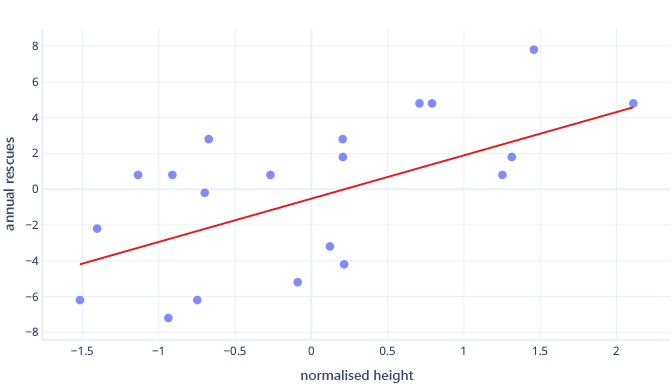
La pendiente de la línea ahora es 0,5. Preste atención al eje x. Nuestra intersección óptima de -0,5 y la pendiente de 0,5 son de la misma escala. Ahora es fácil elegir un tamaño de paso razonable, que es la rapidez con la que el descenso de gradiente actualiza los parámetros.
El escalado ayuda con varias características
Cuando se trabaja con varias características, tener estas en una escala diferente puede provocar problemas de ajuste, de forma similar a como lo acabamos de ver con los ejemplos de interceptación y pendiente. Por ejemplo, si estamos entrenando un modelo que acepta tanto la altura en mm como el peso en toneladas métricas, muchos tipos de modelos tendrán dificultades para apreciar la importancia de la característica del peso, simplemente porque es muy pequeña en relación con las características de la altura.
¿Siempre es necesario escalar?
No siempre es necesario escalar. Algunos tipos de modelos, como los modelos anteriores con líneas rectas, pueden ajustarse sin ningún procedimiento iterativo, como el descenso de gradiente, y, por tanto, no les importa que las características tengan un tamaño incorrecto. Otros modelos sí necesitan el escalado para que el entrenamiento sea correcto, pero sus bibliotecas suelen realizar el escalado automático de características.
Por lo general, las únicas desventajas reales de la normalización o la estandarización son que puede dificultar la interpretación de los modelos y que es necesario escribir algo más de código. Por esta razón, el escalado de características es un elemento estándar de la creación de modelos de Machine Learning.