Descripción de los trabajos de flujo de trabajo
Los flujos de trabajo permiten automatizar los pasos del proceso de implementación. El proceso puede incluir varios grupos lógicos de trabajos que quiera ejecutar. En esta unidad, obtendrá información sobre los trabajos de flujo de trabajo y cómo usarlos para agregar procesos de control de calidad a las implementaciones de Bicep.
¿Qué son los trabajos de flujo de trabajo?
Los trabajos le ayudan a dividir el flujo de trabajo en varios bloques lógicos. Cada trabajo puede incluir uno o varios pasos.
Los trabajos se pueden usar en el flujo de trabajo para marcar una separación de intereses. Por ejemplo, cuando se trabaja con código de Bicep, la validación del código es un interés independiente de la implementación del archivo de Bicep. Cuando se usa un flujo de trabajo automatizado, la compilación y prueba del código se conoce a menudo como integración continua (CI). La implementación de código en un flujo de trabajo automatizado a menudo se denomina implementación continua (CD).
En los trabajos de CI, se comprueba la validez de los cambios realizados en el código. Los trabajos de CI proporcionan control de calidad. Se pueden ejecutar sin afectar al entorno de producción en directo.
En muchos lenguajes de programación, el código se debe compilar antes de que se pueda ejecutar. Cuando se implementa un archivo de Bicep, se convierte o transpila de Bicep a JSON. Las herramientas realizan este proceso automáticamente. En la mayoría de las situaciones, no es necesario compilar manualmente el código de Bicep en plantillas JSON dentro del flujo de trabajo. Pero se sigue usando el término integración continua cuando se habla de código de Bicep, porque todavía se aplican las demás partes de CI, como la validación del código.
Después de que los trabajos de CI se ejecuten correctamente, debe aumentar la confianza de que los cambios realizados también se implementarán correctamente. En los trabajos de CD, el código se implementa en cada uno de los entornos. Normalmente, empieza con entornos de prueba y otros entornos que no son de producción y, después, pasa a entornos de producción. En este módulo, la implementación se realizará en un único entorno. En un módulo posterior, descubrirá cómo ampliar el flujo de trabajo de implementación para implementarla en varios entornos, como los de producción y los que no son de producción.
Los trabajos se ejecutan en paralelo de manera predeterminada. Puede controlar cómo y cuándo se ejecuta cada trabajo. Por ejemplo, puede configurar los trabajos de CD para que se ejecuten solo después de que los trabajos de CI se ejecuten correctamente. O bien podría tener varios trabajos de CI que deben ejecutarse en secuencia, como la compilación del código y, después, probarlo. También podría incluir un trabajo Rollback (Reversión) que solo se ejecute si se ha producido un error en los trabajos de implementación anteriores.
Desplazamiento a la izquierda
Mediante el uso de trabajos, puede comprobar la calidad del código antes de implementarlo. En ocasiones, este proceso se denomina desplazamiento a la izquierda.
Al escribir código, plantéese una escala de tiempo de las actividades que se llevan a cabo. La escala de tiempo comienza a partir de las fases de planificación y diseño. Después, pasa a las fases de compilación y pruebas. Por último, realice la implementación y, después, tendrá que admitir la solución.
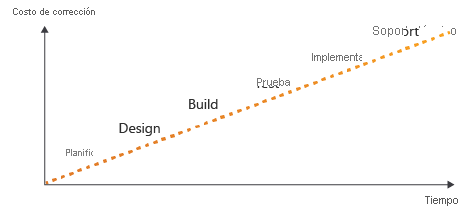
Una regla conocida en el desarrollo de software es que cuanto antes se encuentren los errores (cuanto más cerca estén a la izquierda de la escala de tiempo), más fácil, rápido y barato será corregirlos. Cuanto más tarde se detecte un error en el proceso, más difícil y complicado será corregirlo.
Por tanto, el objetivo es desplazar la detección de problemas hacia la izquierda del diagrama anterior. A lo largo de este módulo, verá cómo puede agregar más validación y pruebas al flujo de trabajo a medida que avanza.
Incluso puede agregar la validación mucho antes de que comience la implementación. Cuando se trabaja con herramientas como GitHub, las solicitudes de incorporación de cambios suelen representar los cambios que alguien del equipo quiere realizar en el código de la rama principal. Resulta útil crear otro flujo de trabajo que ejecute automáticamente los pasos de CI durante el proceso de revisión de la solicitud de incorporación de cambios. Esta técnica permite validar que el código todavía funciona, incluso con los cambios propuestos. Si la validación se realiza correctamente, tiene cierta confianza en que el cambio no causará problemas cuando se combine con la rama principal. Si se produce un error en la comprobación, sabe que hay más trabajo que hacer antes de que la solicitud de incorporación de cambios esté lista para combinarse. En un módulo posterior, obtendrá información sobre cómo configurar un proceso de versión adecuado mediante solicitudes de incorporación de cambios y estrategias de bifurcación.
Importante
La eficacia de la validación automatizada y las pruebas es directamente proporcional a la de las pruebas que escriba. Es importante tener en cuenta los aspectos que necesita probar y los pasos que debe realizar para estar seguro de que la implementación es correcta.
Definición de un trabajo de flujo de trabajo
Cada flujo de trabajo contiene al menos un trabajo, y se pueden definir más trabajos para adaptarse a sus requisitos. Los trabajos se ejecutan en paralelo de manera predeterminada. El tipo de cuenta de GitHub que tiene determina el número de trabajos que se pueden ejecutar simultáneamente cuando se usan ejecutores hospedados en GitHub.
Imagine que ha compilado un archivo de Bicep que tiene que implementar dos veces: en la infraestructura de Estados Unidos y en la de Europa. También quiere validar el código de Bicep en el flujo de trabajo. Esta es una ilustración de un flujo de trabajo de varios trabajos en la que se define un proceso similar:
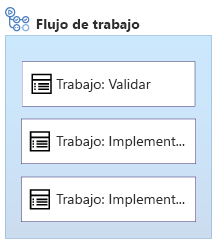
Observe que este ejemplo tiene tres trabajos. El trabajo Validate (Validación) es similar a un trabajo de CI. Después, se ejecutan los trabajos Deploy US (Implementación de EE. UU.) y Deploy Europe (Implementación de Europa). Cada uno implementa el código en uno de los entornos. De manera predeterminada, los trabajos se ejecutan en paralelo.
Aquí le mostramos cómo se definen los trabajos en un archivo YAML de flujo de trabajo:
name: learn-github-actions
on: [push]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the validation steps."
deployUS:
runs-on: windows-latest
steps:
- run: echo "Here is where you'd perform the steps to deploy to the US region."
deployEurope:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the steps to deploy to the European region."
Control de la secuencia de trabajos
Puede agregar dependencias entre los trabajos para cambiar el orden. Siguiendo con el ejemplo anterior, es probable que quiera validar el código antes de ejecutar los trabajos de implementación, de la siguiente forma:
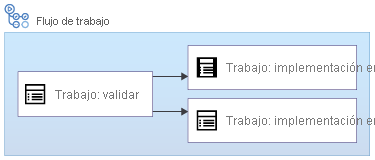
Puede especificar las dependencias entre trabajos mediante la palabra clave needs:
name: learn-github-actions
on: [push]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the validation steps."
deployUS:
runs-on: windows-latest
needs: validate
steps:
- run: echo "Here is where you'd perform the steps to deploy to the US region."
deployEurope:
runs-on: ubuntu-latest
needs: validate
steps:
- run: echo "Here is where you'd perform the steps to deploy to the European region."
Al usar la palabra clave needs, el flujo de trabajo espera a que el trabajo dependiente finalice correctamente antes de iniciar el trabajo siguiente. Si el flujo de trabajo detecta que se han cumplido todas las dependencias de varios trabajos, puede ejecutar esos trabajos en paralelo.
Nota:
En realidad, los trabajos se ejecutan en paralelo solo si tiene suficientes ejecutores para ejecutar varios trabajos al mismo tiempo. El número de ejecutores hospedados en GitHub que se pueden usar depende del tipo de cuenta de GitHub que tenga. Si necesita más trabajos paralelos, puede comprar otro plan de cuenta de GitHub.
A veces, se quiere ejecutar un trabajo cuando se produce un error en un trabajo anterior. Por ejemplo, este es otro flujo de trabajo. Si se produce un error en la implementación, inmediatamente después se ejecuta un trabajo denominado Reversión:
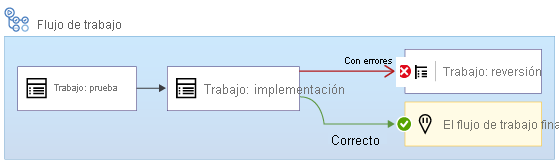
Debe usar la palabra clave if para especificar una condición que se deba cumplir antes de que se ejecute un trabajo:
name: learn-github-actions
on: [push]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- run: echo "Here is where you'd perform the validation steps."
deploy:
runs-on: windows-latest
needs: validate
steps:
- run: echo "Here is where you'd perform the steps to deploy."
rollback:
runs-on: ubuntu-latest
needs: deploy
if: ${{ failure() }}
steps:
- run: echo "Here is where you'd perform the steps to roll back a failure."
En el ejemplo anterior, cuando todo es correcto, el flujo de trabajo ejecuta primero el trabajo Validate (Validación) y después el trabajo Deploy (Implementación). Omite el trabajo Rollback (Reversión). Pero si se produce un error en los trabajos Test (Prueba) o Deploy (Implementación), el flujo de trabajo ejecuta el trabajo Rollback (Reversión). Obtendrá más información sobre la reversión más adelante en este módulo.
Trabajos de implementación de Bicep
Un flujo de trabajo de implementación de Bicep típico incluye varios trabajos. A medida que el flujo de trabajo avanza por los trabajos, el objetivo es estar cada vez más seguro de que los trabajos posteriores sean correctos. Estos son los trabajos comunes para un flujo de trabajo de implementación de Bicep:

- Lint: use el linter de Bicep para comprobar que el archivo de Bicep está bien formado y no contiene errores obvios.
- Validate (Validación): use el proceso de validación preparatoria de Azure Resource Manager para comprobar si hay problemas que podrían producirse al realizar la implementación.
- Versión preliminar: Use el comando hipotético para validar la lista de cambios que se aplican al entorno de Azure. Pida a una persona que revise manualmente los resultados what-if y apruebe el flujo de trabajo para continuar.
- Deploy (Implementación): envíe la implementación a Resource Manager y espere a que se complete.
- Prueba de humo: Ejecute comprobaciones básicas posteriores a la implementación en algunos de los recursos importantes que implementó. Estas revisiones se denominan pruebas de comprobación de la compilación de la infraestructura.
Es posible que la organización tenga otra secuencia de trabajos o que necesite integrar las implementaciones de Bicep en un flujo de trabajo que implemente otros componentes. Después de comprender cómo funcionan los trabajos, puede diseñar un flujo de trabajo que se adapte a sus necesidades.
Cada trabajo se ejecuta en una nueva instancia de ejecutor que se inicia desde un entorno limpio. Por lo tanto, en todos los trabajos normalmente debe extraer el código fuente del repositorio como primer paso. También debe iniciar sesión en el entorno de Azure en cada trabajo que interactúe con Azure.
A lo largo de este módulo, obtendrá más información sobre estos trabajos y creará progresivamente un flujo de trabajo en el que se incluya cada uno de ellos. También descubrirá lo siguiente:
- Cómo detienen los flujos de trabajo el proceso de implementación si ocurre algo inesperado en cualquiera de los trabajos anteriores.
- Cómo configurar el flujo de trabajo para que se pause hasta que compruebe manualmente lo que ha ocurrido en un trabajo anterior.