Comprobación local del código
Siempre que cambie cualquier código del proyecto de aprendizaje automático, conviene que compruebe la calidad del código y del modelo.
Durante la integración continua, creará y comprobará los recursos de la aplicación. Como científico de datos, probablemente se centrará en la creación de scripts usados para la preparación de datos y para el entrenamiento del modelo. El ingeniero de aprendizaje automático usa los scripts más adelante en las canalizaciones para automatizar estos procesos.
Hay dos tareas comunes para comprobar los scripts:
- Linting:comprobar si hay errores de programación o estilísticos en los scripts de Python o R.
- Pruebas unitarias: comprobar el rendimiento del contenido de los scripts.
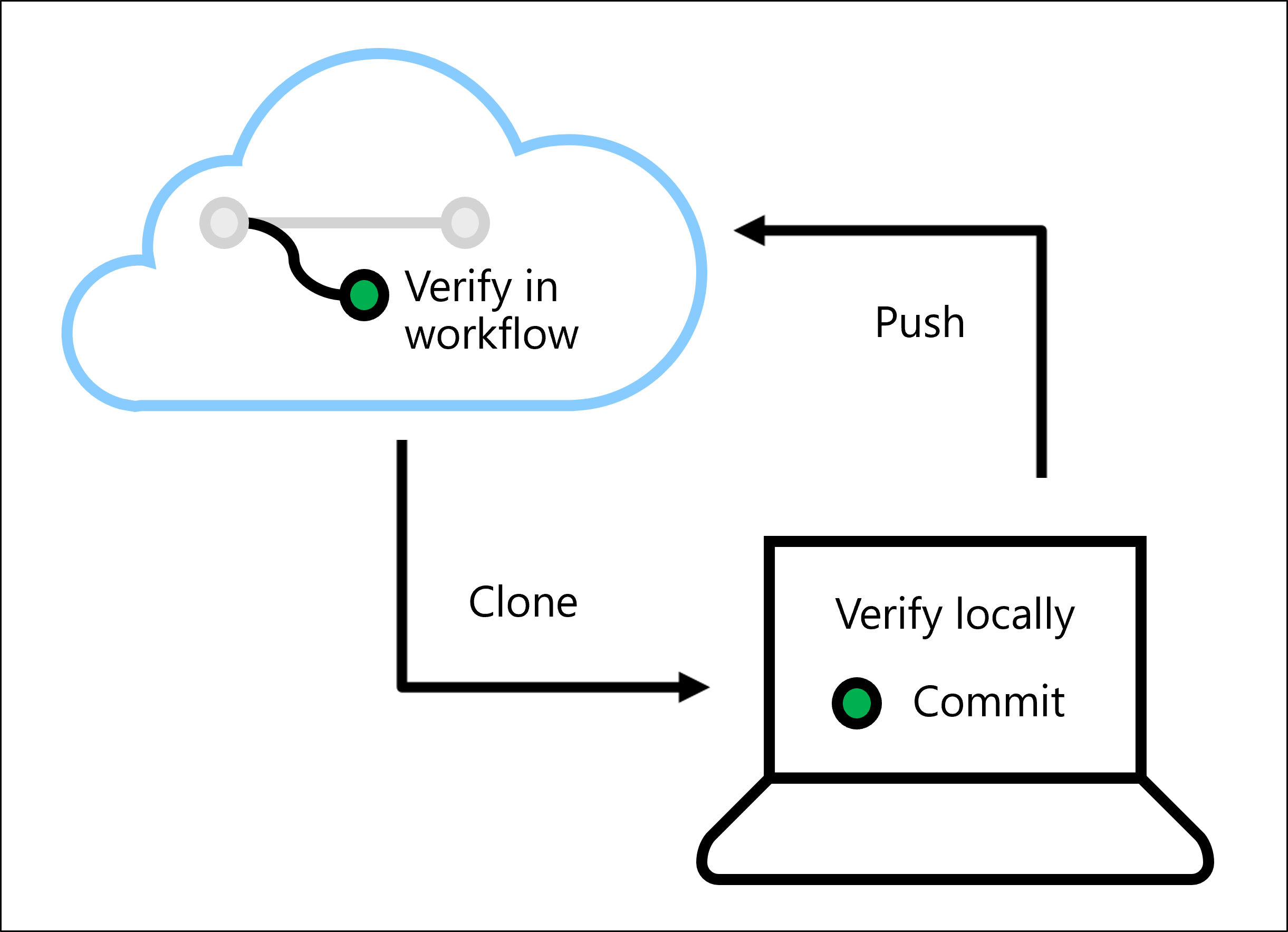
Al comprobar el código, se evitan errores o problemas cuando se implementa el modelo. Puede comprobar el código localmente mediante la ejecución de linters y pruebas unitarias de forma local en un IDE como Visual Studio Code.
También puede ejecutar linters y pruebas unitarias en un flujo de trabajo automatizado con Azure Pipelines o Acciones de GitHub.
Aprenderá a ejecutar pruebas unitarias y linting en Visual Studio Code.
Linting del código
La calidad del código depende de los estándares que usted y su equipo acuerden. Para asegurarse de que se cumple la calidad acordada, puede ejecutar linters, que comprobarán si el código cumple los estándares del equipo.
Según el lenguaje de código que use, hay varias opciones para usar lint en el código. Por ejemplo, si trabaja con Python, puede usar Flake8 o Pylint.
Use Flake8 para realizar el linting del código
Para usar Flake8 de forma local con Visual Studio Code:
- Instale Flake8 con
pip install flake8. - Cree un archivo
.flake8de configuración y almacénelo en el repositorio. - Configure Visual Studio Code para usar Flake8 como linter; para ello, vaya a la configuración (
Ctrl+,). - Busque
flake8. - Habilite Python > Linting > Flake8 Habilitado.
- Establezca la ruta de acceso de Flake8 en la ubicación del repositorio donde almacenó el archivo
.flake8.
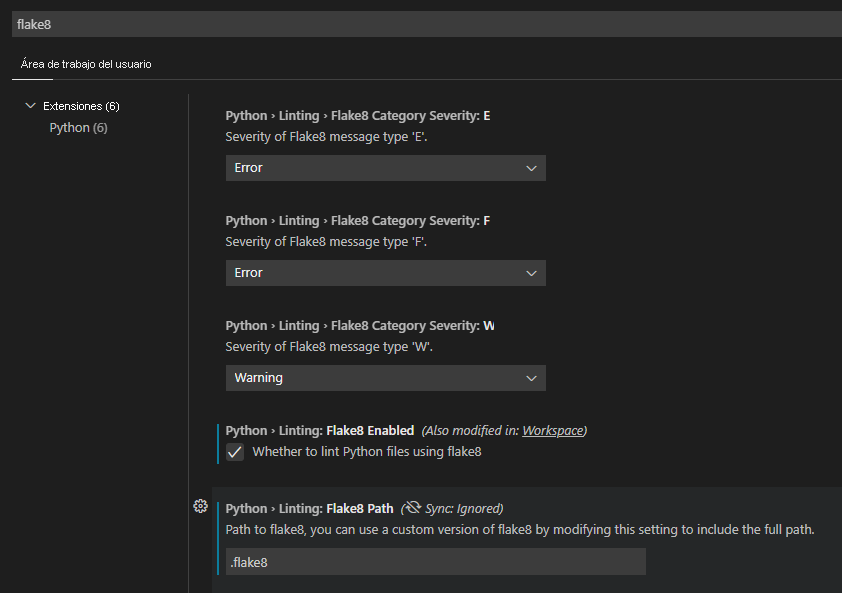
Para especificar cuáles son los estándares del equipo para la calidad del código, puede configurar el linter Flake8. Un método común para definir los estándares consiste en crear un archivo .flake8 que se almacena con el código.
El archivo .flake8 debe comenzar con [flake8], seguido de cualquiera de las configuraciones que desee usar.
Sugerencia
Puede encontrar una lista completa de los posibles parámetros de configuración en la documentación de Flake8.
Por ejemplo, si desea especificar que la longitud máxima de cualquier línea no puede tener más de 80 caracteres, agregará la siguiente línea al archivo .flake8:
[flake8]
max-line-length = 80
Flake8 tiene una lista predefinida de errores que puede devolver. Además, puede usar códigos de error basados en la guía de estilo PEP 8. Por ejemplo, puede incluir códigos de error que hacen referencia al uso adecuado de sangría o espacios en blanco.
Puede elegir seleccionar (select) un conjunto de códigos de error que formarán parte del linter o seleccionar qué códigos de error omitir (ignore) de la lista predeterminada de opciones.
Como resultado, el archivo .flake8 de configuración puede tener un aspecto similar al del ejemplo siguiente:
[flake8]
ignore =
W504,
C901,
E41
max-line-length = 79
exclude =
.git,
.cache,
per-file-ignores =
code/__init__.py:D104
max-complexity = 10
import-order-style = pep8
Sugerencia
Para obtener información general sobre los códigos de error que puede consultar, revise la lista de errores de Flake8
Cuando haya configurado Visual Studio Code para realizar el lint del código, puede abrir cualquier archivo de código para revisar los resultados de linting. Las advertencias o errores aparecen subrayados. Puede seleccionar Ver problema para inspeccionar el problema y comprender el error.

Linting con Azure Pipelines o Acciones de GitHub
También puede ejecutar el linter automáticamente con Azure Pipelines o Acciones de GitHub. El agente proporcionado por cualquiera de las plataformas ejecutará el linter cuando:
- Cree un archivo
.flake8de configuración y almacénelo en el repositorio. - Defina la canalización de integración continua o el flujo de trabajo en YAML.
- Como tarea o paso, instale Flake8 con
python -m pip install flake8. - Como tarea o paso, ejecute el comando
flake8para realizar el lint del código.
Pruebas unitarias
Mientras que el linting comprueba cómo escribió el código, las pruebas unitarias comprueban cómo funciona. Las unidades hacen referencia al código que crea. Por lo tanto, las pruebas unitarias también se conocen como pruebas de código.
Como procedimiento recomendado, el código debe existir principalmente fuera de las funciones. No importa si ha creado funciones para preparar los datos o para entrenar un modelo. Puede aplicar pruebas unitarias para, por ejemplo:
- Comprobar que los nombres de columna son correctos.
- Comprobar el nivel de predicción del modelo en nuevos conjuntos de datos.
- Compruebe la distribución de los niveles de predicción.
Al trabajar con Python, puede usar Pytest y Numpy (que usa el marco Pytest) para probar el código. Para obtener más información sobre cómo trabajar con Pytest, aprenda a escribir pruebas con Pytest.
Sugerencia
Revise un tutorial más detallado de las pruebas de Python en Visual Studio Code.
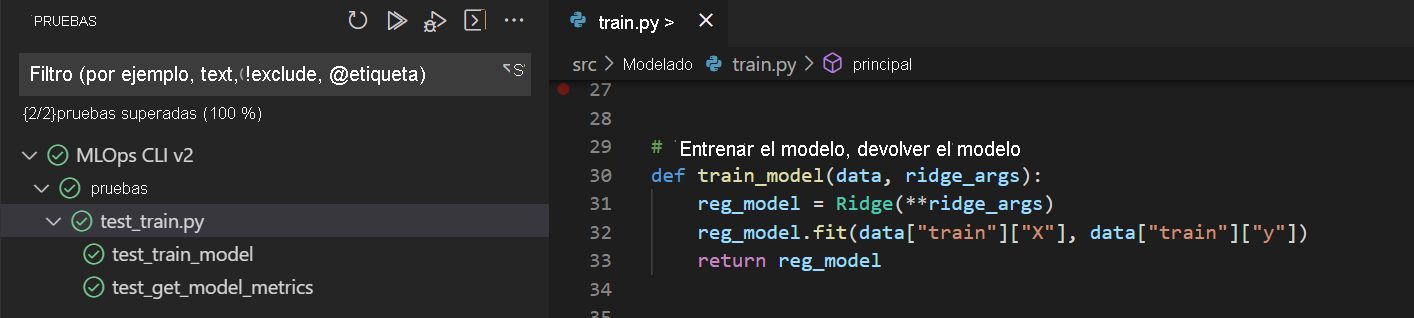
Imagine que ha creado un script de entrenamiento train.py, que contiene la siguiente función:
# Train the model, return the model
def train_model(data, ridge_args):
reg_model = Ridge(**ridge_args)
reg_model.fit(data["train"]["X"], data["train"]["y"])
return reg_model
Supongamos que ha almacenado el script de entrenamiento en el directorio src/model/train.py del repositorio. Para probar la función train_model, debe importar la función desde src.model.train.
El archivo test_train.py se crea en la carpeta tests. Una manera de probar el código de Python es usar numpy. Numpy ofrece varias funciones assert para comparar matrices, cadenas, objetos o elementos.
Sugerencia
Obtenga más información sobre las directrices de prueba al usar las pruebas de Numpy y la compatibilidad con pruebas de Numpy.
Por ejemplo, para probar la función train_model, puede usar un pequeño conjunto de datos de entrenamiento y usar assert para comprobar si las predicciones son casi iguales a las métricas de rendimiento predefinidas.
import numpy as np
from src.model.train import train_model
def test_train_model():
X_train = np.array([1, 2, 3, 4, 5, 6]).reshape(-1, 1)
y_train = np.array([10, 9, 8, 8, 6, 5])
data = {"train": {"X": X_train, "y": y_train}}
reg_model = train_model(data, {"alpha": 1.2})
preds = reg_model.predict([[1], [2]])
np.testing.assert_almost_equal(preds, [9.93939393939394, 9.03030303030303])
Para probar el código en Visual Studio Code mediante la interfaz de usuario:
- Instale todas las bibliotecas necesarias para ejecutar el script de entrenamiento.
- Asegúrese de que
pytestestá instalado y habilitado en Visual Studio Code. - Instalación de la extensión de Python para Visual Studio Code.
- Seleccione el script
train.pyque quiere probar. - Seleccione la pestaña Pruebas en el menú situado a la izquierda.
- Para configurar las pruebas de Python, seleccione pytest y establezca el directorio de prueba en la carpeta
tests/. - Para ejecutar todas las pruebas, seleccione el botón Reproducir y revise los resultados.
Para ejecutar la prueba en una canalización de Azure DevOps o Acción de GitHub:
- Asegúrese de que todas las bibliotecas necesarias están instaladas para ejecutar el script de entrenamiento. Idealmente, use un
requirements.txtcon una lista de todas las bibliotecas conpip install -r requirements.txt - Instalación de
pytestconpip install pytest - Ejecute las pruebas con
pytest tests/
Los resultados de las pruebas se mostrarán en la salida de la canalización o flujo de trabajo que ejecute.
Nota
Si durante el linting o las pruebas unitarias se devuelve un error, es posible que falle la canalización de CI. Por lo tanto, es mejor comprobar el código localmente en primer lugar antes de desencadenar la canalización de CI.