Indexación de datos mediante la API de inserción de Búsqueda de Azure AI
La API de REST es la manera más flexible de insertar datos en un índice de Búsqueda de Azure AI. Puede usar cualquier lenguaje de programación o hacerlo de forma interactiva con cualquier aplicación que pueda publicar solicitudes JSON en un punto de conexión.
Aquí, verá cómo usar la API de REST de forma eficaz y explorar las operaciones disponibles. A continuación, verá el código de .NET Core y verá cómo optimizar la adición de grandes cantidades de datos a través de la API.
Operaciones de la API de REST admitidas
Hay dos API de REST compatibles proporcionadas por Búsqueda de AI. API de búsqueda y de administración. Este módulo se centra en las API de REST de búsqueda que proporcionan operaciones en cinco características de búsqueda:
| Característica | Operations |
|---|---|
| Índice | Crear, eliminar, actualizar y configurar. |
| Documento | Obtener, agregar, actualizar y eliminar. |
| indizador | Configuración de orígenes de datos y programación en orígenes de datos limitados. |
| Conjunto de aptitudes | Obtener, crear, eliminar, enumerar y actualizar. |
| Mapa de sinónimos | Obtener, crear, eliminar, enumerar y actualizar. |
Cómo llamar a la API de REST de búsqueda
Si desea llamar a cualquiera de las API de búsqueda, debe:
- Usar el punto de conexión HTTPS (en el puerto predeterminado 443) proporcionado por el servicio de búsqueda; debe incluir una versión de API en el URI.
- El encabezado de solicitud debe incluir un atributo api-key.
Para buscar el punto de conexión, la versión de api y la clave de API, vaya a Azure Portal.

En el portal, vaya al servicio de búsqueda y seleccione Explorador de búsqueda. El punto de conexión de la API de REST se encuentra en el campo URL de solicitud. La primera parte de la dirección URL es el punto de conexión (por ejemplo, https://azsearchtest.search.windows.net), y la cadena de consulta muestra api-version (por ejemplo, api-version=2023-07-01-Preview).

Para buscar api-key a la izquierda, seleccione Claves. La clave de administrador principal o secundaria se puede usar si usa la API de REST para hacer más acciones además de consultar el índice. Si solo necesita buscar en un índice, puede crear y usar claves de consulta.
Para agregar, actualizar o eliminar datos de un índice, debe usar una clave de administrador.
Adición de datos a un índice
Use una solicitud HTTP POST con la característica de índices en este formato:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
El cuerpo de la solicitud debe informar al punto de conexión de REST de la acción que se debe realizar en el documento, en qué documento se debe aplicar la acción y qué datos se deben usar.
El JSON debe tener este formato:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Acción | Descripción |
|---|---|
| upload | De manera parecida a un upsert en SQL, el documento se creará o se reemplazará. |
| merge | La combinación actualiza un documento existente con los campos especificados. Si no se encuentra ningún documento, se producirá un error en la combinación. |
| mergeOrUpload | La combinación actualiza un documento existente con los campos especificados y lo carga si el documento no existe. |
| delete | Elimina todo el documento, solo tiene que especificar key_field_name. |
Si la solicitud se realiza correctamente, la API devolverá un código de estado 200.
Nota:
Para obtener una lista completa de todos los códigos de respuesta y los mensajes de error, consulte Adición, actualización o eliminación de documentos (API de REST de Búsqueda de Azure AI).
En este ejemplo, JSON carga el registro del cliente en la unidad anterior:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
Puede agregar tantos documentos en la matriz de valores como desee. Sin embargo, para un rendimiento óptimo, considere la posibilidad de procesar por lotes los documentos de las solicitudes hasta un máximo de 1000 documentos o un tamaño total de 16 MB.
Uso de .NET Core para indexar los datos
Para obtener el mejor rendimiento, use la biblioteca cliente de Azure.Search.Document más reciente, que actualmente es la versión 11. Puede instalar la biblioteca cliente con NuGet:
dotnet add package Azure.Search.Documents --version 11.4.0
El rendimiento del índice se basa en seis factores clave:
- El nivel de servicio de la búsqueda y cuántas réplicas y particiones ha habilitado.
- La complejidad del esquema del índice. Reduzca el número de propiedades (buscables, clasificables y ordenables) que tiene cada campo.
- El número de documentos de cada lote; el mejor tamaño dependerá del esquema del índice y del tamaño de los documentos.
- En qué grado es multiproceso el enfoque.
- Control de los errores y la limitación. Use una estrategia de reintento de retroceso exponencial.
- Donde residen los datos, intente indexar los datos de la forma más similar posible al índice de búsqueda. Por ejemplo, ejecute cargas desde dentro del entorno de Azure.
Determinación del tamaño de lote óptimo
Dado que determinar el mejor tamaño de lote es un factor clave para mejorar el rendimiento, echemos un vistazo a un enfoque en el código.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
El enfoque consiste en aumentar el tamaño del lote y supervisar el tiempo necesario para recibir una respuesta válida. El código recorre de 100 a 1000, en 100 pasos del documento. Para cada tamaño de lote, genera el tamaño del documento, el tiempo para obtener una respuesta y el tiempo medio por MB. La ejecución de este código proporciona resultados como los siguientes:
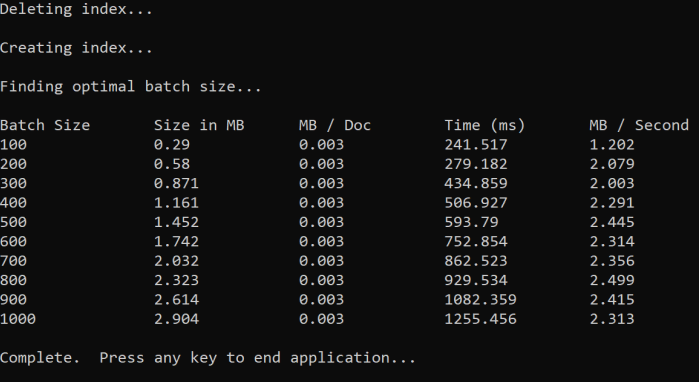
En el ejemplo anterior, el mejor tamaño de lote para el rendimiento es de 2,499 MB por segundo y 800 documentos por lote.
Implementación de una estrategia de reintento de retroceso exponencial
Si el índice comienza a limitar las solicitudes debido a sobrecargas, responde con un estado 503 (solicitud rechazada debido a una carga pesada) o 207 (algunos documentos del lote generaron errores). Tiene que controlar estas respuestas y una buena estrategia es el retroceso. El retroceso consiste en detenerse durante algún tiempo antes de volver a intentar la solicitud. Si aumenta este tiempo para cada error, realizará un retroceso exponencial.
Examine este código:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
El código realiza un seguimiento de los documentos con errores de un lote. Si se produce un error, espera un retraso y, a continuación, duplica el retraso para el siguiente error.
Por último, hay un número máximo de reintentos y, si se alcanza este número máximo, el programa existe.
Uso de subprocesos para mejorar el rendimiento
Puede completar la aplicación de carga de documentos mediante la combinación de la estrategia de retroceso anterior con un enfoque de subprocesos. A continuación, se ponen ejemplos de código:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Este código usa llamadas asincrónicas a una función ExponentialBackoffAsync que implementa la estrategia de retroceso. La función se llama mediante subprocesos; por ejemplo, el número de núcleos que tiene el procesador. Cuando se ha usado el número máximo de subprocesos, el código espera a que finalice cualquier subproceso. A continuación, crea un nuevo subproceso hasta que se cargan todos los documentos.