Uso de Apache Phoenix en HBase de HDInsight
Los clústeres de HBase en HDInsight tienen Apache Phoenix. Apache Phoenix es una capa de base de datos relacional de código abierto y masivamente paralela que se basa en Apache HBase. Apache Phoenix permite usar consultas de tipo SQL a través de HBase. Usa controladores JDBC debajo para permitir a los usuarios crear, eliminar y modificar tablas SQL. También puede indexar, crear vistas y secuencias, y upsert filas de forma individual y masiva. Phoenix usa la compilación nativa de NoSQL en lugar de usar MapReduce para compilar consultas, lo que permite crear aplicaciones de baja latencia a partir de HBase. Phoenix agrega coprocesadores para admitir la ejecución de código proporcionado por clientes en el espacio de direcciones del servidor, ejecutando el código colocado con los datos. Este enfoque minimiza la transferencia de datos entre cliente y servidor. Para más información, vea la documentación de Apache Phoenix.
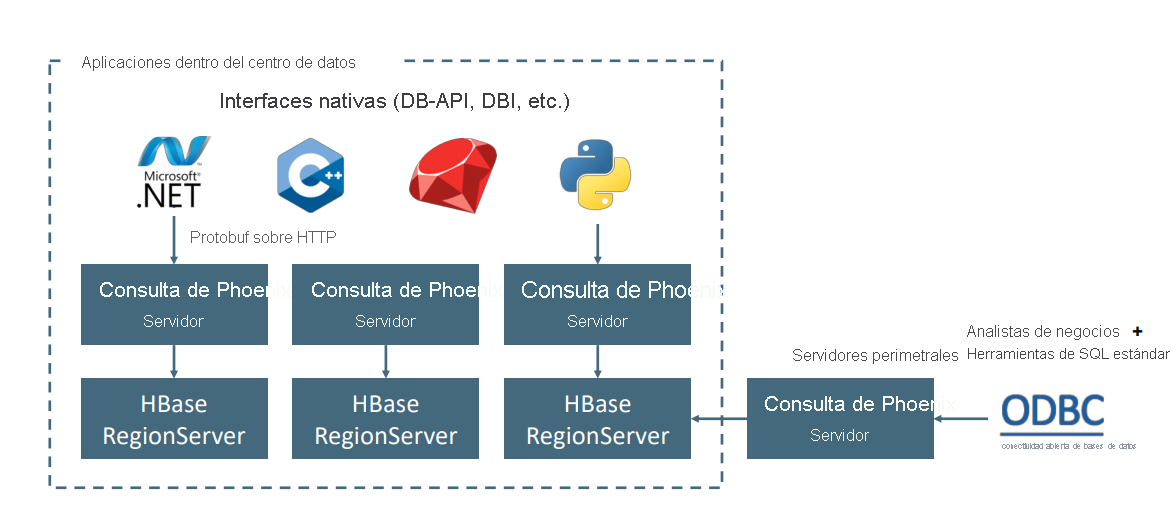
Apache Phoenix en HDInsight HBase se usa normalmente para habilitar el análisis de autoservicio y extraer información, como se muestra a continuación. Phoenix puede conectarse a cualquier herramienta de BI compatible con ODBC y habilitar análisis SQL ad hoc en HBase.
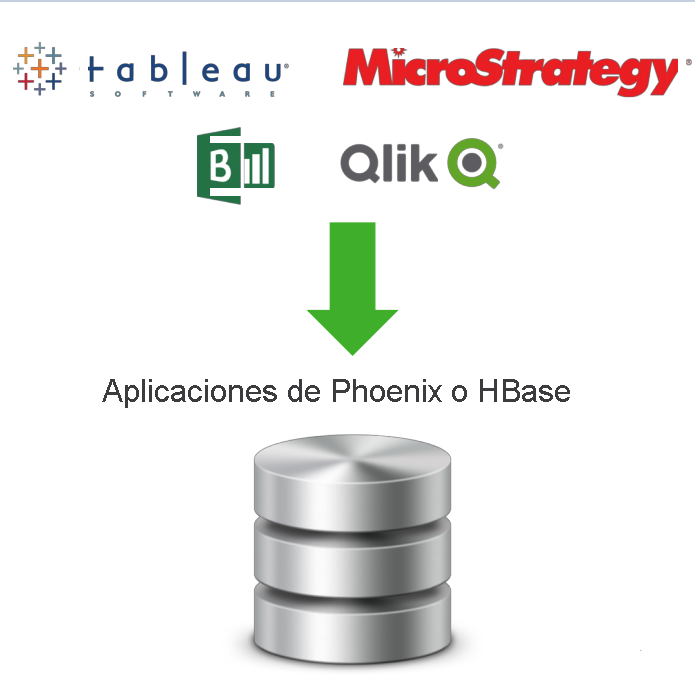
La combinación de Apache HBase y Phoenix se puede usar como almacén de datos para los datos mutables. El motor de consultas de Apache Phoenix en HBase incluye algunas características importantes.
Índices secundarios
Se obtiene acceso a los registros de HBase mediante la clave de fila principal mediante un índice único que lexicográficamente está ordenado por la clave de fila principal. Si intenta obtener acceso a los registros de forma distinta a la fila principal, eso provocaría un análisis ineficaz de todos los datos de la tabla de HBase. Apache Phoenix permite crear índices secundarios en columnas y expresiones para crear claves de fila alternativas para permitir búsquedas de puntos o recorridos de intervalo a lo largo de este nuevo índice. Para más información, vea la documentación de los índices secundarios de Apache Phoenix.
El comando CREATE INDEX se usa para crear índices secundarios en HBase, como se muestra a continuación.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Vistas
Limitar el número de tablas físicas en HBase y, a su vez, limitar el número de regiones es una estrategia recomendada. Las vistas de Phoenix ayudan a esta recomendación al permitir la creación de varias tablas virtuales que comparten la misma tabla física subyacente en HBase. Para más información, vea la documentación de vistas de Apache Phoenix.
Dada la siguiente definición de tabla en HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Puede definir la vista siguiente.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transacciones
Aunque HBase funciona solo con transacciones de nivel de fila, Apache Phoenix habilita las transacciones entre tablas y entre filas con compatibilidad completa con ACID mediante la integración con Apache Tephra.
Para más información, vea la documentación de transacciones de Apache Phoenix
En el ejemplo siguiente se crea una tabla denominada my_table y, a continuación, se modifica la tabla para habilitar las transacciones.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Tablas cifradas con sal
La zona activa del servidor de región en HBase puede ocurrir durante escrituras secuenciales si las claves de fila aumentan monótonamente. Apache Phoenix puede aliviar las zonas activas proporcionando una manera de sal de la clave de fila con un byte de cifrado con sal para una tabla determinada. Para obtener más información, consulte la documentación de tabla de cifrado con sal de Apache Phoenix.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Omitir examen
Para un conjunto determinado de filas, Apache Phoenix usa Skip Scan para el escaneo dentro de la fila sobre un rango de escaneo para mejorar el rendimiento. Skip Scan aprovecha el filtro de HBase SEEK_NEXT_USING_HINT. Almacena información sobre el conjunto de claves o intervalos de claves que se buscan en cada columna. A continuación, toma una clave (que se le pasa durante la evaluación del filtro) y determina si está en una de las combinaciones o rango o no. Si no es así, se averigua a qué clave superior siguiente se va a saltar. Para más información, vea la documentación de Scan Skip de Apache Phoenix.
La optimización del rendimiento en Apache Phoenix es una característica opcional solicitada y depende principalmente de la optimización del rendimiento de HBase. La optimización del rendimiento es un tema complejo y está fuera del ámbito de este curso. Sin embargo, si le interesa, puede consultar la documentación sobre Procedimientos recomendados de rendimiento de Apache Phoenix.