Información general sobre Azure Site Recovery
Azure Site Recovery no se reduce a una herramienta que sirve para recuperarse de las interrupciones del sistema, sino que también replica las cargas de trabajo entre un sitio principal y una ubicación secundaria. Site Recovery también se puede usar para migrar máquinas virtuales desde una infraestructura local a Azure.
La primera tarea para proteger las cargas de trabajo de un terremoto, por ejemplo, es revisar el plan actual de continuidad empresarial y recuperación ante desastres (BCDR) de la empresa. Se deben identificar los diferentes objetivos y ámbitos de recuperación de los sistemas que necesitan protección.
En esta unidad, se investiga de qué manera puede ayudar Azure Site Recovery a alcanzar estos objetivos y hacer que la conmutación por error y la recuperación de recursos sean posibles en caso de desastre.
Continuidad empresarial y recuperación ante desastres
La pérdida del servicio puede provocar interrupciones para el personal y los usuarios. Cada segundo que los sistemas no estén disponibles puede derivar en pérdidas de ingresos para la empresa. La empresa también podría tener que afrontar sanciones financieras por incumplir acuerdos que rigen la disponibilidad de los servicios que preste.
Los planes de BCDR son documentos formales que las empresas redactan para tratar el ámbito y las acciones que se deben llevar a cabo cuando se produce un desastre o una interrupción a gran escala. Cada interrupción se evalúa según sus propias características. Por ejemplo, un plan de BCDR entra en acción cuando se corta el suministro eléctrico en un centro de datos entero.
En este escenario de ejemplo se ha producido un terremoto y los daños en las líneas de comunicaciones han inutilizado el centro de datos, de modo que debe repararse. Un desastre de ese tamaño podría dejar los servicios inactivos durante días, no horas, por lo que se deberá invocar un plan de BCDR completo para volver a poner el servicio en línea.
Como parte del plan de BCDR, identifique los objetivos de tiempo de recuperación (RTO) y los objetivos de punto de recuperación (RPO) de sus aplicaciones. Conjuntamente, estos dos objetivos ayudan a identificar el número máximo de horas que puede estar su empresa sin los servicios especificados y cómo debería ser el proceso de recuperación de datos. Veamos con más detalle cada uno de ellos.
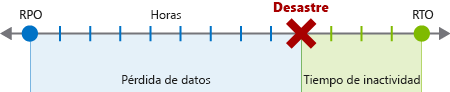
Objetivo de tiempo de recuperación
Un RTO es una medida de la cantidad máxima de tiempo que la empresa puede sobrevivir después de un desastre hasta que deba restaurarse el servicio normal para evitar consecuencias inaceptables asociadas a una interrupción en la continuidad. Supongamos que su RTO es de 12 horas, lo que significa que las operaciones pueden continuar durante 12 horas sin que los servicios comerciales principales funcionen. Si el tiempo de inactividad es mayor, su empresa se verá seriamente perjudicada.
Objetivo de punto de recuperación
Un RPO es una medida de la cantidad máxima de pérdida de datos que es aceptable después de un desastre. Por lo general, una empresa puede decidir hacer una copia de seguridad cada 24 horas, cada 12 horas o incluso en tiempo real. Si se produce un desastre, siempre habrá pérdida de datos.
Por ejemplo, si la copia de seguridad se realizara a la medianoche cada 24 horas y se produjera un desastre a las 9:00, se perderían nueve horas de datos. Si el RPO de la empresa fuera de 12 horas, no pasaría nada porque solo habrían pasado nueve horas. Si el RPO fuera de cuatro horas, habría un problema y la empresa se vería perjudicada.
¿Qué es Azure Site Recovery?
Azure Site Recovery puede contribuir al plan de BCDR, ya que es capaz de replicar cargas de trabajo desde un sitio primario en un sitio secundario. Si se produce un problema en el sitio primario, Site Recovery se puede invocar automáticamente para replicar las máquinas virtuales protegidas en otra ubicación. La conmutación por error puede tener lugar desde un entorno local a Azure, o desde una región de Azure a otra.
Algunas de las características destacadas de Azure Site Recovery son:
- Administración centralizada: la replicación se puede configurar y administrar, y la conmutación por error y la conmutación por recuperación se pueden invocar desde Azure Portal.
- Replicación de máquinas virtuales locales: las máquinas virtuales locales se pueden replicar a Azure o a un centro de datos local, si procede.
- Replicación de máquinas virtuales de Azure: las máquinas virtuales de Azure se pueden replicar desde una región a otra.
- Coherencia de las aplicaciones durante la conmutación por error: al usar puntos de recuperación e instantáneas coherentes con las aplicaciones, las máquinas virtuales siempre se mantienen en un estado coherente durante la replicación.
- Conmutación por error flexible: las conmutaciones por error se pueden ejecutar a petición como prueba o desencadenarse durante un desastre real. Se pueden realizar pruebas para simular un escenario de recuperación ante desastres sin interrumpir el servicio en directo.
- Integración de red: Site Recovery puede encargarse de la administración de red durante un escenario de replicación y de recuperación ante desastres. Esto engloba las direcciones IP reservadas y los equilibradores de carga para que las máquinas virtuales funcionen en la nueva ubicación.
Configuración de Azure Site Recovery

Hay varios componentes que deben configurarse para habilitar Azure Site Recovery:
- Redes: se requiere una red virtual de Azure válida para que la usen las máquinas virtuales replicadas.
- Almacén de Recovery Services: almacén en la suscripción de Azure que almacena las VM migradas cuando se ejecuta una conmutación por error. El almacén también contiene la directiva de replicación y las ubicaciones de origen y de destino de la replicación y conmutación por error.
- Credenciales: las credenciales que use en Azure deben tener los roles Colaborador de la máquina virtual y Colaborador de Site Recovery para poder modificar la VM y el almacenamiento a los que Site Recovery está conectado.
- Servidor de configuración: un servidor de VMware local cumple varios roles durante el proceso de conmutación por error y replicación. Se obtiene de Azure Portal como un dispositivo de máquina virtual abierto (OVA) para facilitar la implementación. El servidor de configuración incluye lo siguiente:
- Servidor de procesos: este servidor actúa como puerta de enlace del tráfico de replicación. Almacena en memoria caché, comprime y cifra el tráfico antes de enviarlo a Azure a través de la WAN. El servidor de procesos también instala Mobility Service en todas las máquinas físicas y virtuales destinadas a la conmutación por error y la replicación.
- Servidor de destino maestro: esta máquina controla el proceso de replicación durante una conmutación por recuperación desde Azure.
Importante
Para realizar una conmutación por recuperación desde Azure al entorno local, debe haber disponible una instancia de VMware vCenter con un servidor de configuración, incluso si solo va a replicar máquinas físicas en Azure. La conmutación por recuperación no se puede realizar a un servidor físico.
Proceso de replicación
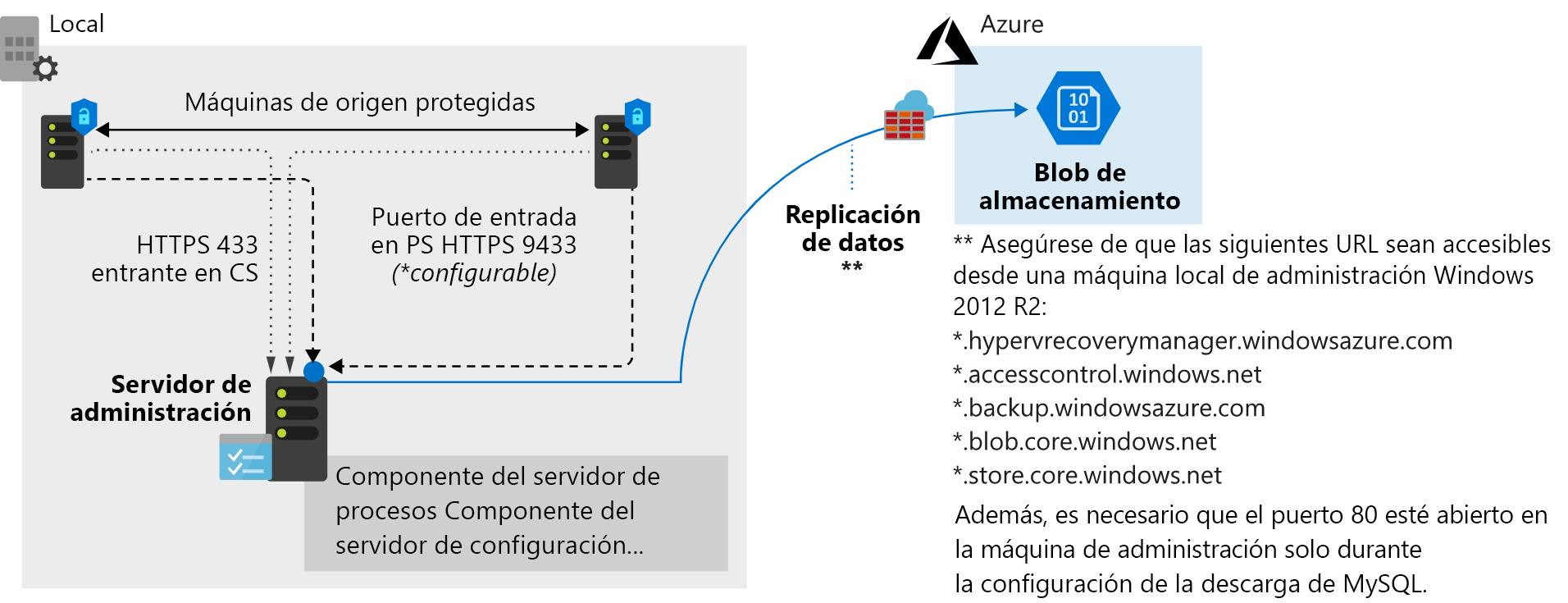
Tras configurar las tareas de requisitos previos, puede comenzar la replicación de las máquinas. Se replican de acuerdo con la directiva de replicación en vigor. Durante las primeras fases de la primera copia, los datos del servidor se replican en Azure Storage. Cuando la replicación inicial finaliza, arranca una segunda replicación. Esta vez, los cambios diferenciales en la máquina virtual se replican en Azure.
Prueba y supervisión de una conmutación por error
Después de haber configurado el entorno para la recuperación ante desastres, pruébelo para asegurarse de que se ha configurado correctamente y de que todo funciona según lo previsto. Para probar la configuración, realice un simulacro de recuperación ante desastres en una máquina virtual aislada. Se recomienda usar una red aislada durante la prueba para que los servicios activos no se interrumpan.
La primera tarea al intentar hacer un simulacro de recuperación es verificar las propiedades de la máquina virtual de prueba en la sección Elementos protegidos de Azure Portal. Los puntos de recuperación más recientes se ven en el panel Elementos replicados. En la sección Proceso y red se ajustan los valores de nombre de la máquina virtual, grupo de recursos, tamaño de destino, conjunto de disponibilidad y disco, si fuera necesario.
Los simulacros de recuperación se pueden iniciar desde la sección Configuración>Elementos replicados de Azure Portal. Seleccione la máquina virtual de destino y, luego, seleccione el elemento de menú Conmutación por error de prueba del punto de recuperación procesado más reciente. Seleccione la red de Azure en el mismo menú. Para iniciar el trabajo de recuperación, seleccione Aceptar en la pantalla de selección de red.
Para acceder al estado del trabajo de recuperación y a la máquina virtual replicada, vaya a la sección Información general del almacén de Recovery Services. Los elementos replicados tendrán uno de los siguientes estados:
- Correcto: la replicación funciona con normalidad.
- Advertencia: indica que hay un problema que podría afectar a la replicación.
- Crítico: se ha detectado un error crítico de replicación.
Si todo va bien, el estado de la máquina virtual replicada se establece en Realizada correctamente. Si no se ha realizado ninguna prueba, el estado se establece en Prueba recomendada. La VM también se establece en Prueba recomendada si han transcurrido más de seis meses desde la última prueba.