Exploración de los datos
Data Wrangler facilita la exploración de los datos con una interfaz de cuadrícula fácil de usar que presenta dinámicamente estadísticas de resumen de los datos.
A través de la exploración visual de estadísticas de resumen, los científicos de datos pueden seleccionar los modelos estadísticos o de Machine Learning adecuados que mejor se ajusten a los datos. Por ejemplo, algunos modelos asumen que los datos se distribuyen normalmente y que pueden no funcionar bien si se infringe esta suposición.
Sugerencia
Para obtener más información sobre los aspectos básicos de la exploración de datos mediante cuadernos, consulte Explorar datos sobre la ciencia de datos con cuadernos en Microsoft Fabric.
Visualización de estadísticas de resumen
Con fines de demostración, vamos a generar algunos datos aleatorios para simular un escenario hipotético sobre precios de casas en un vecindario determinado.
import pandas as pd
import numpy as np
# Set the seed
np.random.seed(0)
# Define the size of the dataset
size = 500
# Generate random data
data = {
'Size': np.random.randint(1000, 4001, size, dtype=int) // 10 * 10, # any integer value between 1000 and 4000, with multiple of 10
'Bedrooms': np.random.choice([2, 4, 3, 2, 1], size),
'YearBuilt': np.random.randint(1980, 2021, size), # any integer value between 1980 and 2020
'Price': np.random.normal(loc=110000, scale=20000, size=size), # normally distributed prices
'Type': np.random.choice(['Single Family', 'Townhouse', 'Condo', 'Duplex'], size) # type of the house
}
# Create a DataFrame
df = pd.DataFrame(data)
Para ver las estadísticas de resumen del dataframe df, seleccione Datos en la cinta de opciones del cuaderno y, luego, elija Iniciar Data Wrangler para el dataframe df.

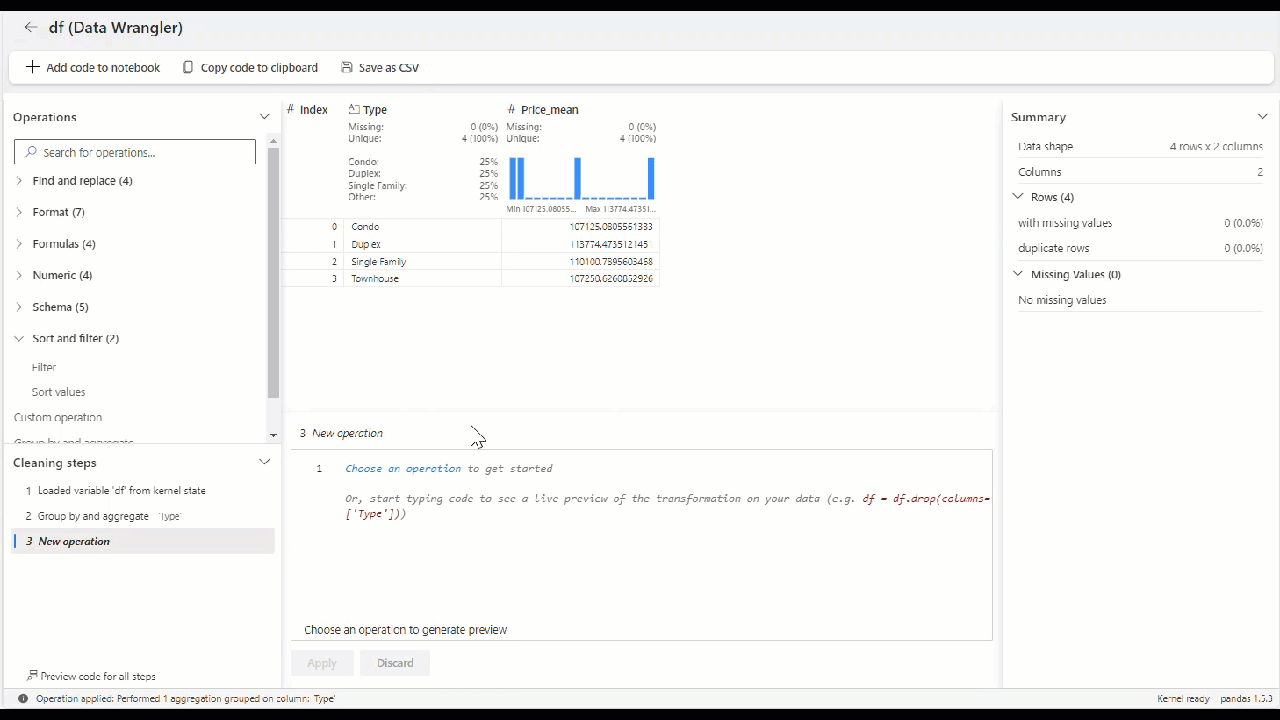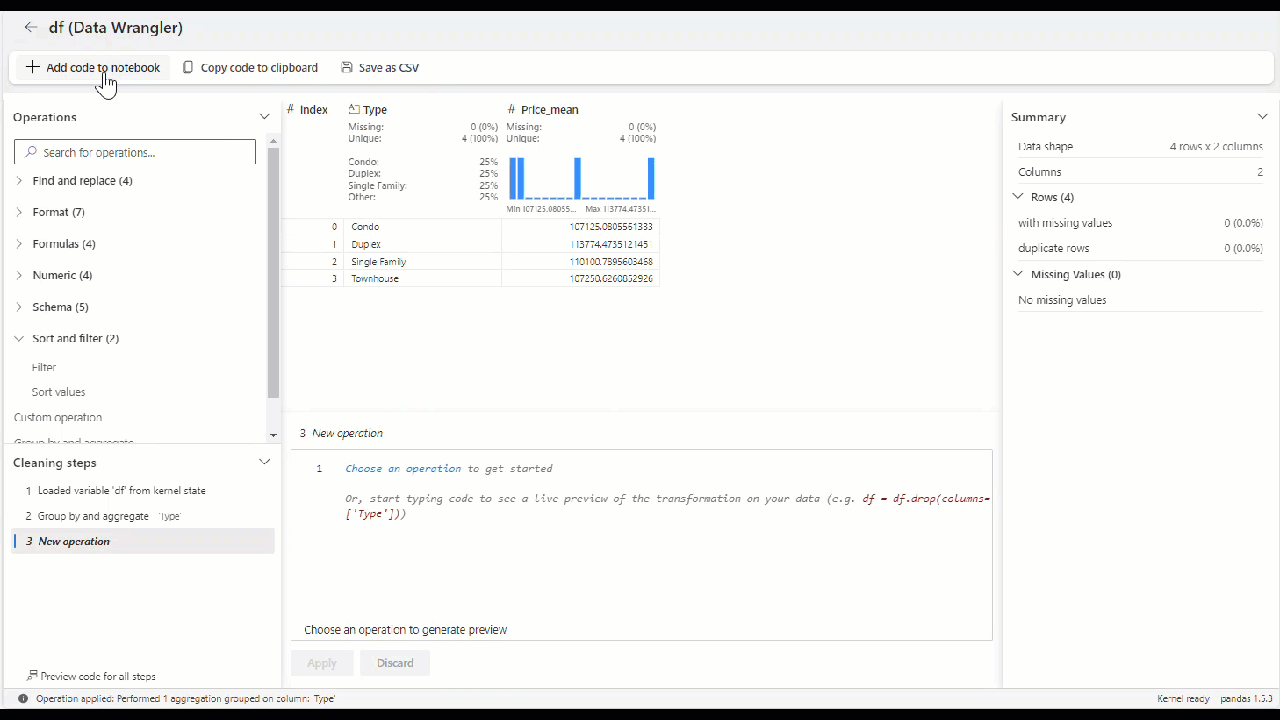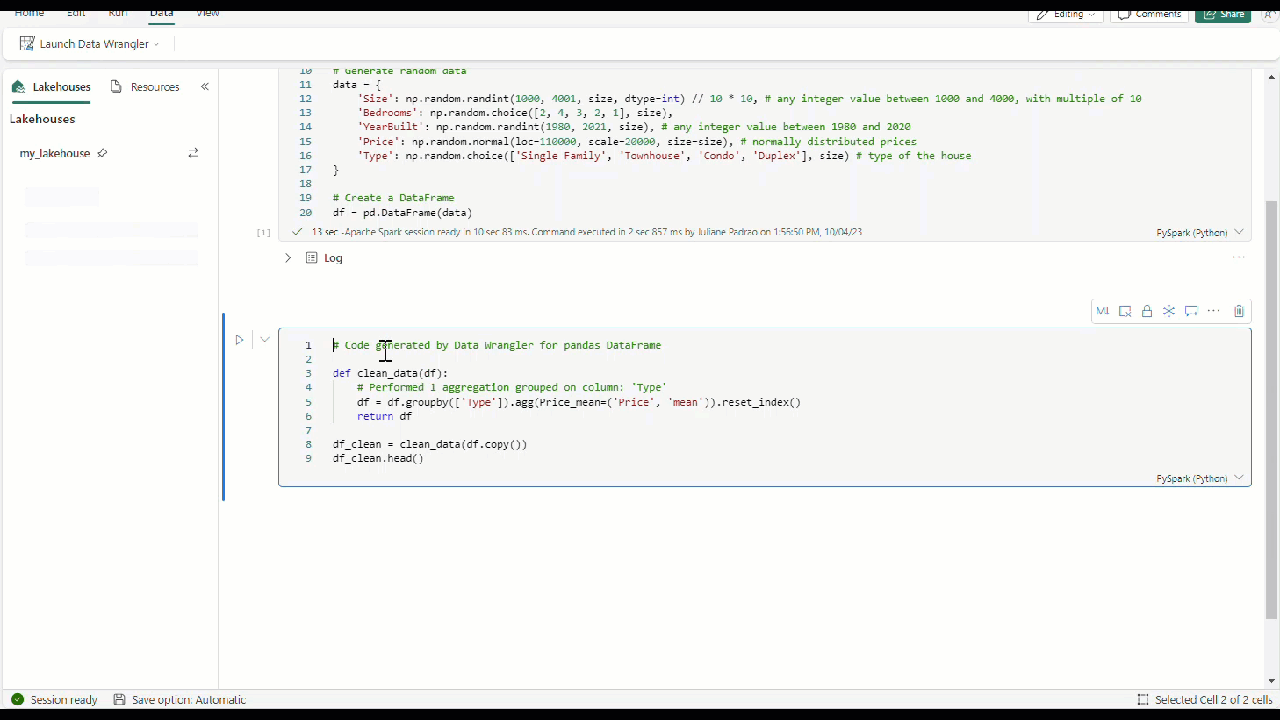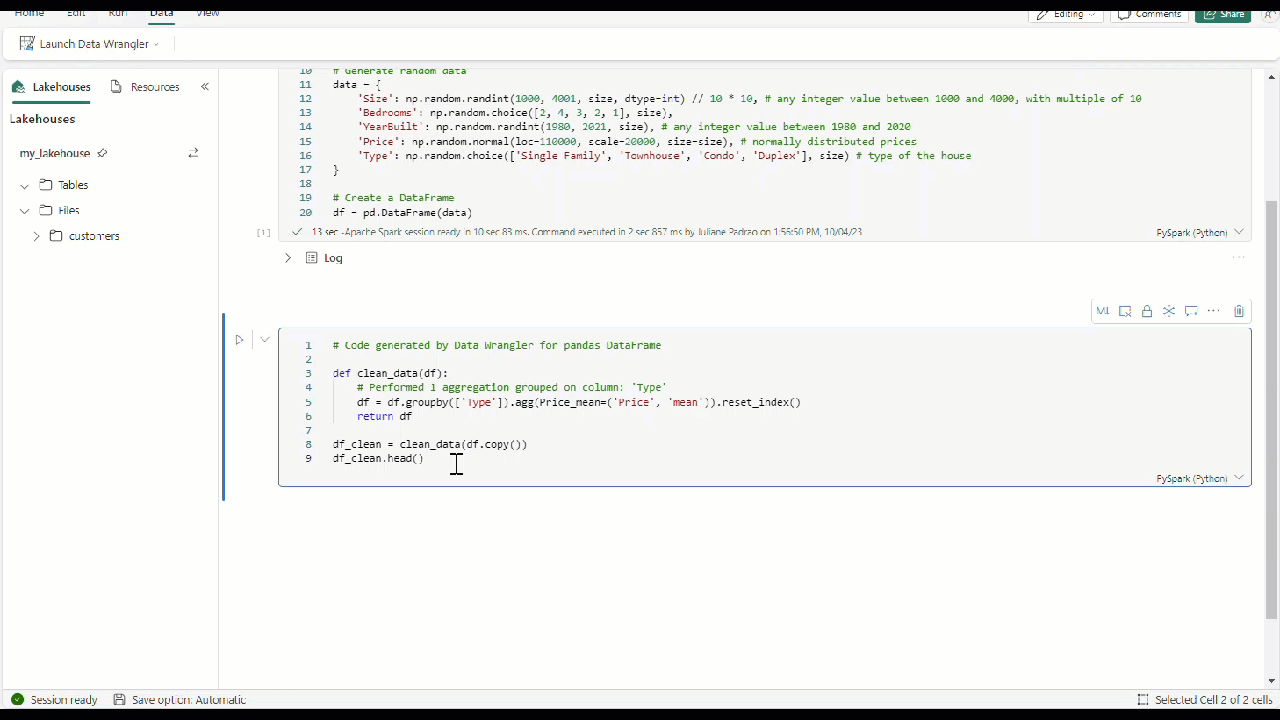
Para las variables numéricas, la cuadrícula muestra un histograma y recuentos de valores que faltan y los valores únicos, así como los valores mínimo y máximo. Cuando se trata de variables de categorías, la cuadrícula ofrece información sobre la proporción de cada categoría en la variable.
En el panel Resumen se proporcionan estadísticas descriptivas detalladas y actualizaciones dinámicas a medida que se seleccionan las distintas columnas en la cuadrícula.
Agrupación y agregación de datos
Como alternativa, puede aplicar la agregación en los datos mediante el operador Agrupar por y agregar del panel de operadores.
Para nuestro escenario de precios de casas, supongamos que necesitamos el promedio de precio de las viviendas por tipo.

En cuestión de segundos, podemos configurar el operador Agrupar por y agregar, donde el código se genera automáticamente. Además, en la cuadrícula se muestran los nuevos datos en verde y las columnas que se van a quitar en rojo.
Una vez aplicado el operador, este es el aspecto que debería tener la cuadrícula final.

En este punto, puede decidir generar el código, o bien descargar el dataframe transformado como un archivo de valores separados por comas (CSV).
Generación de código
En Data Wrangler, cuando se usan operadores integrados o personalizados, el dataframe no cambia hasta que se agrega y ejecuta el código generado en el cuaderno.
Una vez que haya aplicado todos los operadores para transformar los datos, seleccione + Agregar código al cuaderno en la barra de herramientas situada encima de la cuadrícula de Data Wrangler. Se generará una función que podrá ejecutar en la canalización de datos.
Esta característica simplifica las tareas de exploración y preprocesamiento de datos en el flujo de trabajo de ciencia de datos.