Descripción de Data Wrangler
Data Wrangler es una herramienta creada en cuadernos de Microsoft Fabric que ofrece una plataforma completa para tareas exploratorias y de preprocesamiento. Ofrece visualizaciones de los datos, estadísticas de resumen dinámicas, visualizaciones integradas y una biblioteca de operaciones comunes de preprocesamiento de datos.
Cada operación actualiza la visualización de datos en tiempo real y genera código reutilizable que se puede guardar en el cuaderno. Su interfaz fácil de usar hace que sea una herramienta eficaz para los científicos de datos para controlar grandes volúmenes de datos y transformar los datos sin procesar en un conjunto de datos listo para usar para el análisis.
Data Wrangler se puede considerar una herramienta que genera código para las necesidades de exploración y preprocesamiento de datos.
Nota:
Data Wrangler actualmente solo admite el dataframe de Pandas.
Trabajo con Wrangler de datos
Data Wrangler puede ayudar con la fase de preprocesamiento de la creación de un modelo de Machine Learning, ya que proporciona herramientas y funcionalidades para la limpieza de datos, la ingeniería de características, la exploración de datos y la mejora de la eficacia en el preprocesamiento de los datos.
Exploración de datos: La visualización de datos tipo cuadrícula de la herramienta permite explorar visualmente los datos, con lo que se puede conseguir información sobre las variables.
Limpieza de datos: Data Wrangler proporciona una biblioteca de operaciones comunes de limpieza de datos, por lo que resulta más fácil gestionar los valores que faltan, los valores atípicos y los tipos de datos incorrectos.
Ingeniería de características: Con sus visualizaciones integradas y sus estadísticas de resumen dinámicas, Data Wrangler puede resultar útil para comprender la distribución de los datos y crear nuevas características.
Data Wrangler puede ser de ayuda para asegurarse de que los datos estén en el mejor estado posible antes de usarlos para entrenar un modelo de Machine Learning. De esta manera se pueden obtener modelos más precisos y mejores predicciones.
Inicio de Data Wrangler desde un cuaderno
Para iniciar Data Wrangler en Microsoft Fabric, siga estos pasos.
Cambie de Power BI a Ciencia de datos mediante el icono del conmutador de experiencia del lado izquierdo de la página principal. Luego, cree un nuevo cuaderno.
Lea los datos en un DataFrame de Pandas en un cuaderno de Microsoft Fabric.
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") Add another dataset example.Una vez cargados los datos en un dataframe, seleccione Datos en la cinta de opciones del cuaderno.
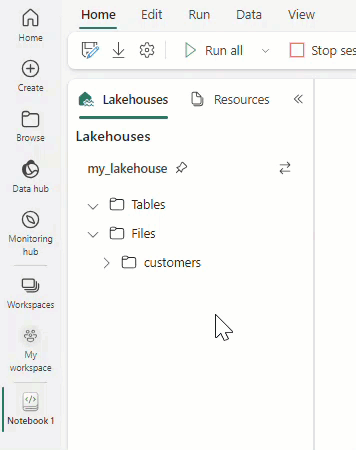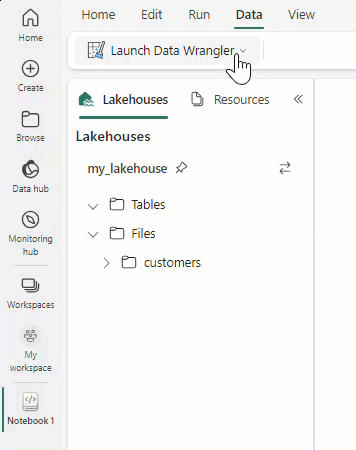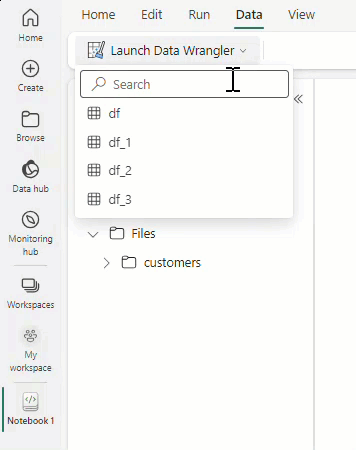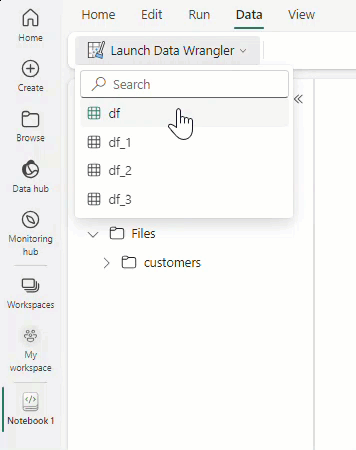
Seleccione Iniciar Data Wrangler y, luego, seleccione el dataframe que desea abrir en Data Wrangler. Si tiene varios dataframes, se mostrarán todos.
Sugerencia
La extensión de Data Wrangler de datos para Visual Studio Code permite la integración de Data Wrangler tanto en cuadernos de Visual Studio Code como de Jupyter Notebook de VS Code.
Trabajo con operadores
Imagine que está trabajando en un conjunto de datos grande para un proyecto crítico. Los datos necesitan mucho trabajo. Faltan valores, hay filas duplicadas y se debe cambiar el nombre de varias columnas. Además, tiene que transformar algunos datos categóricos a un formato que el modelo de Machine Learning pueda comprender.
Aquí es donde entra Data Wrangler. Con un esfuerzo mínimo, puede ordenar y filtrar filas, aplicar codificación one-hot a datos categóricos, cambiar tipos de columnas, quitar las columnas innecesarias, cambiar el nombre de las columnas, gestionar los valores que faltan y mucho más. Data Wrangler no solo facilita estas tareas, sino que también genera código de Python reutilizable para cada operación, el cual se puede guardar en el cuaderno. Esto significa que puede automatizar las tareas de procesamiento de datos para los futuros conjuntos de datos.
Estas son las categorías de operadores que están disponibles actualmente en Data Wrangler.
| Category | Descripción |
|---|---|
| Buscar y reemplazar | Incluye varias operaciones, como la eliminación de filas duplicadas, la gestión de los valores que faltan y la búsqueda y reemplazo de valores. |
| Formato | Implica distintas transformaciones del texto, como la conversión a mayúsculas o minúsculas, la división del texto, la eliminación de espacios en blanco y las transformaciones automáticas con la tecnología de Microsoft Flash Fill. |
| Fórmulas | Permite la creación de nuevas columnas mediante fórmulas personalizadas de Python, el binarizador de varias etiquetas, la codificación one-hot y el cálculo de la longitud del texto. |
| Numérico | Incluye varias operaciones, como el redondeo como el redondeo (hacia arriba, hacia abajo o al número más próximo) y el escalado de valores mín./máx. |
| Esquema | Permite cambios en el esquema del DataFrame, como la modificación de los tipos de columna y la clonación, la eliminación, el cambio de nombre y la selección de columnas. |
| Ordenar y filtrar | Incluye operaciones para filtrar y ordenar valores. |
| Otro | Incluye operaciones personalizadas para modificar el dataframe, la agrupación y agregación, y la creación automática de columnas con la tecnología de Microsoft Flash Fill. |
En las unidades siguientes, exploraremos una variedad de operadores y veremos cómo pueden facilitar las tareas de preprocesamiento para crear modelos predictivos.