Ejercicio: Entrenamiento de un modelo de aprendizaje automático
Ha recopilado datos de los sensores tanto de los dispositivos de fabricación que funcionan correctamente como de los que no lo hacen. Ahora desea usar Model Builder para entrenar un modelo de Machine Learning que prediga si una máquina funcionará correctamente, o no. El uso del aprendizaje automático para automatizar la supervisión de estos dispositivos permite a su empresa ahorrar dinero, ya que proporciona un mantenimiento más rápido y confiable.
Incorporación de un nuevo elemento Modelo de Machine Learning (ML.NET)
Para iniciar el proceso de entrenamiento, es preciso agregar un nuevo elemento Modelo de Machine Learning (ML.NET) a una aplicación .NET nueva o existente.
Creación de una biblioteca de clases de C#
Como está empezando desde cero, cree un proyecto de biblioteca de clases en C# al que agregará un modelo de Machine Learning.
Inicie Visual Studio.
En la ventana inicial, elija Crear un proyecto.
En el cuadro de diálogo Crear un proyecto, escriba biblioteca de clases en la barra de búsqueda.
Seleccione Biblioteca de clases en la lista de opciones. Asegúrese de que el lenguaje es C# y seleccione Siguiente.
En el cuadro de texto Nombre de proyecto, escriba PredictiveMaintenance. Deje los valores predeterminados en los restantes campos y seleccione Siguiente.
Seleccione .NET 6.0 (Preview) (.NET 6.0 [versión preliminar]) en la lista desplegable Marco y seleccione Crear para realizar el scaffolding de la biblioteca de clases de C#.

Agregue el aprendizaje automático al proyecto.
Cuando el proyecto de biblioteca de clases se abra en Visual Studio, será el momento de agregarle el aprendizaje automático.
En el Explorador de soluciones de Visual Studio, haga clic con el botón derecho en el proyecto.
Seleccione Agregar>Modelo de Machine Learning.
En la lista de elementos nuevos del cuadro de diálogo Agregar nuevo elemento, seleccione Machine Learning Model (ML.NET) (Modelo de Machine Learning [ML.NET]).
En el cuadro de texto Nombre, use el nombre PredictiveMaintenanceModel.mbconfig para el modelo y seleccione Agregar.


Al cabo de unos segundos, se agrega al proyecto un archivo denominado PredictiveMaintenanceModel.mbconfig.
Selección del escenario
La primera vez que se agrega un modelo de Machine Learning a un proyecto, se abre la pantalla de Model Builder. Ahora es el momento de seleccionar el escenario.
En su caso de uso, está intentando determinar si una máquina está estropeada o no. Dado que solo hay dos opciones y quiere determinar en qué estado se encuentra una máquina, el escenario de clasificación de datos es el más adecuado.
En el paso Escenario de la pantalla de Model Builder, seleccione el escenario Clasificación de datos. Una vez que haya seleccionado este escenario, pasará inmediatamente al paso Entorno.

Selección del entorno
En escenarios de clasificación de datos, solo se admiten los entornos locales que usan la CPU.
- En el paso Entorno de la pantalla de Model Builder, está seleccionado Local (CPU) de forma predeterminada. Deje seleccionado el entorno predeterminado.
- Seleccione Paso siguiente.

Carga y preparación de los datos
Ahora que ha seleccionado el escenario y el entorno de entrenamiento, es el momento de cargar y preparar los datos que ha recopilado mediante Model Builder.
Preparar los datos
Abra el archivo en el editor de texto de su elección.
Los nombres de columna originales contienen caracteres de corchetes especiales. Para evitar problemas al analizar los datos, quite los caracteres especiales de los nombres de columna.
Encabezado original:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNFEncabezado actualizado:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNFGuarde el archivo ai4i2020.csv con los cambios.
Selección del tipo de origen de datos
El conjunto de datos de mantenimiento predictivo es un archivo .csv.
En el paso Datos de la pantalla de Model Builder, seleccione File (csv, tsv, txt) (Archivo [.csv, .tsv, .txt]) en Tipo de origen de datos.
Especificación de la ubicación de los datos
Seleccione el botón Examinar y use el explorador de archivos para proporcionar la ubicación del conjunto de datos ai4i2020.csv.
Selección de la columna de etiqueta
Seleccione Machine failure (Error de la máquina) en la lista desplegable Column to predict (Label) (Columna que se predice [etiqueta]).

Seleccionar opciones de datos avanzadas
De forma predeterminada, todas las columnas que no sean la etiqueta se usarán como características. Algunas columnas contienen información redundante, mientras que otras no informan de la predicción. Use las opciones de datos avanzadas para omitir esas columnas.
Seleccione Advanced data options (Opciones de datos avanzadas).
En la columna Advanced data options (Opciones de datos avanzadas), seleccione la pestaña Configuración de columnas.
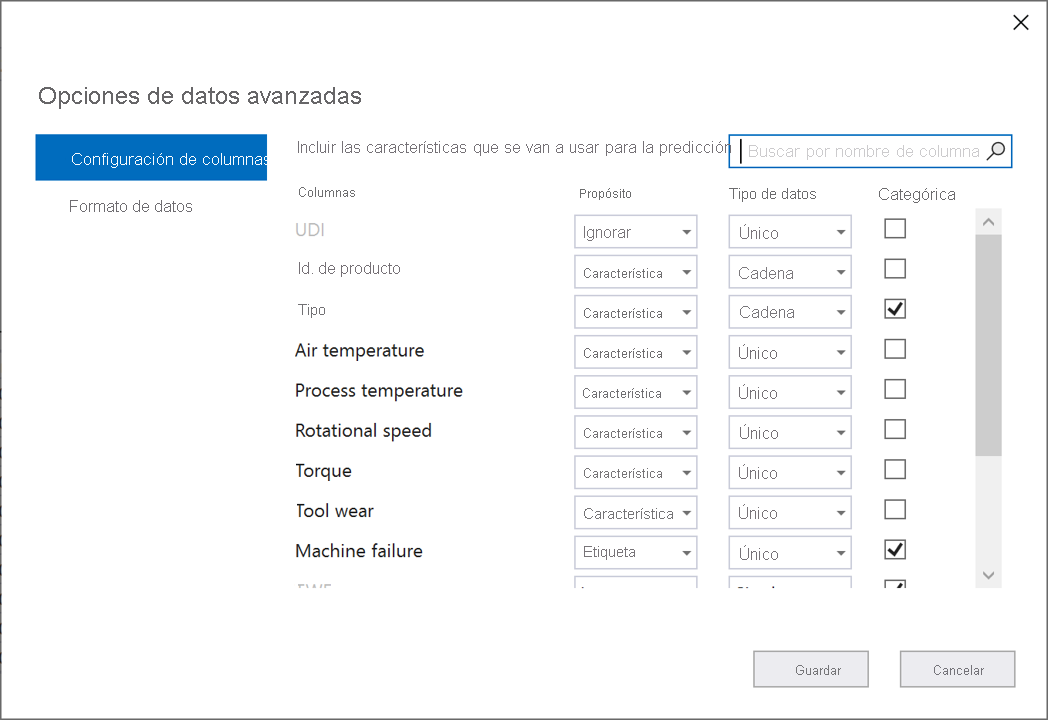
Configure las opciones de columna como se muestra a continuación:
Columnas Propósito Tipo de datos Categorías UDI Ignore Single Product ID Característica String Tipo Característica String X Temperatura del aire Característica Single Temperatura del proceso Característica Single Velocidad de rotación Característica Single Torque Característica Single Desgaste de la herramienta Característica Single Error de la máquina Etiqueta Single X TWF Ignore Single X HDF Ignore Single X PWF Ignore Single X OSF Ignore Single X RNF Ignore Single X Seleccione Guardar.
En el paso Datos de la pantalla de Model Builder, seleccione Siguiente paso.

Entrenamiento de un modelo
Use Model Builder y AutoML para entrenar el modelo.
Establecimiento del tiempo de entrenamiento
Model Builder establece automáticamente durante cuánto tiempo debe realizarse el entrenamiento en función del tamaño del archivo. En este caso, para ayudar a Model Builder a explorar más modelos, especifique un número mayor en el tiempo de entrenamiento.
- En el paso Entrenar de la pantalla de Model Builder, en Time to train (seconds) (Tiempo de entrenamiento [segundos]), seleccione 30.
- Seleccione Entrenar.
Seguimiento del proceso de entrenamiento

Cuando se inicia el proceso de entrenamiento, Model Builder explora varios modelos. El seguimiento del proceso de entrenamiento se realiza en los resultados del propio entrenamiento y en la ventana de salida de Visual Studio. Los resultados del entrenamiento proporcionan información sobre el mejor modelo que se ha encontrado a lo largo del proceso de entrenamiento. La ventana de salida proporciona información detallada como el nombre del algoritmo usado, el tiempo que duró el entrenamiento y las métricas de rendimiento del modelo.
Es posible que vea que el mismo nombre de algoritmo aparece varias veces. Esto sucede porque, además de probar diferentes algoritmos, Model Builder prueba diferentes configuraciones de hiperparámetros para esos algoritmos.
Evaluación del modelo
Use datos y métricas de evaluación para probar el rendimiento del modelo.
Inspección del modelo
El paso Evaluar de la pantalla de Model Builder permite inspeccionar las métricas de evaluación y el algoritmo elegido para el mejor modelo. Recuerde que no importa si los resultados son diferentes de los mencionados en este módulo, ya que tanto el algoritmo como los hiperparámetros elegidos pueden variar.
Comprobación del modelo
En la sección Try your model (Probar el modelo) del paso Evaluar, puede proporcionar nuevos datos y evaluar los resultados de la predicción.

La sección Sample data (Datos de ejemplo) es donde se proporcionan datos de entrada para que el modelo realice predicciones. Cada campo corresponde a las columnas que se usan para entrenar el modelo. Esta es una manera cómoda de comprobar que el modelo se comporta según lo previsto. De forma predeterminada, Model Builder rellena previamente los datos de ejemplo con la primera fila del conjunto de datos.
Vamos a probar el modelo para ver si genera los resultados esperados.
En la sección Sample data (Datos de ejemplo), escriba los siguientes datos. Proceden de la fila del conjunto de datos con el UID 161.
Columna Valor Product ID L47340 Tipo L Temperatura del aire 298,4 Temperatura del proceso 308,2 Velocidad de rotación 1282 Torque 60,7 Desgaste de la herramienta 216 Seleccione Predicción.
Evaluación de los resultados de la predicción
En la sección Resultados se muestra la predicción que ha realizado el modelo y el nivel de confianza en ella.
Si observa la columna Machine failure (Error de la máquina) del UID 161 en el conjunto de datos, verá que el valor es 1, que coincide con el valor predicho con máxima confianza de la sección Resultados.
Si lo desea, puede seguir probando el modelo con distintos valores de entrada y evaluar las predicciones.
¡Enhorabuena! Ha entrenado un modelo para predecir errores en máquinas. En la siguiente unidad, obtendrá más información sobre el consumo de modelos.