Crear un modelo predictivo propio
Puede crear su propio servicio web predictivo basado en un modelo público llamado Experimento de predicción para Dynamics 365 Business Central. Este modelo predictivo está disponible en la galería de IA de Microsoft Azure.
Para usar el modelo predictivo, siga estos pasos:
Abra un navegador y vaya a Azure AI Gallery.
Busque Experimento de predicción para Dynamics 365 Business Central y, a continuación, abra el modelo en Estudio de Microsoft Azure Machine Learning.
En la página Experimento de predicción para Dynamics 365 Business Central, seleccione el vínculo Abrir en Studio (Clásico).
Cuando se le pida, utilice su cuenta de Microsoft para registrarse en un espacio de trabajo y, a continuación, copie el modelo.
El modelo está ahora disponible en el espacio de trabajo.

En la parte inferior de la página, seleccione Ejecutar > Ejecutar modelo para ejecutar el modelo. El proceso puede tardar un par de minutos en completarse.
Publique su modelo como un servicio web seleccionando Implementar servicio web.
Una vez que se haya creado el servicio web, tendrá un aspecto similar a la siguiente captura de pantalla.
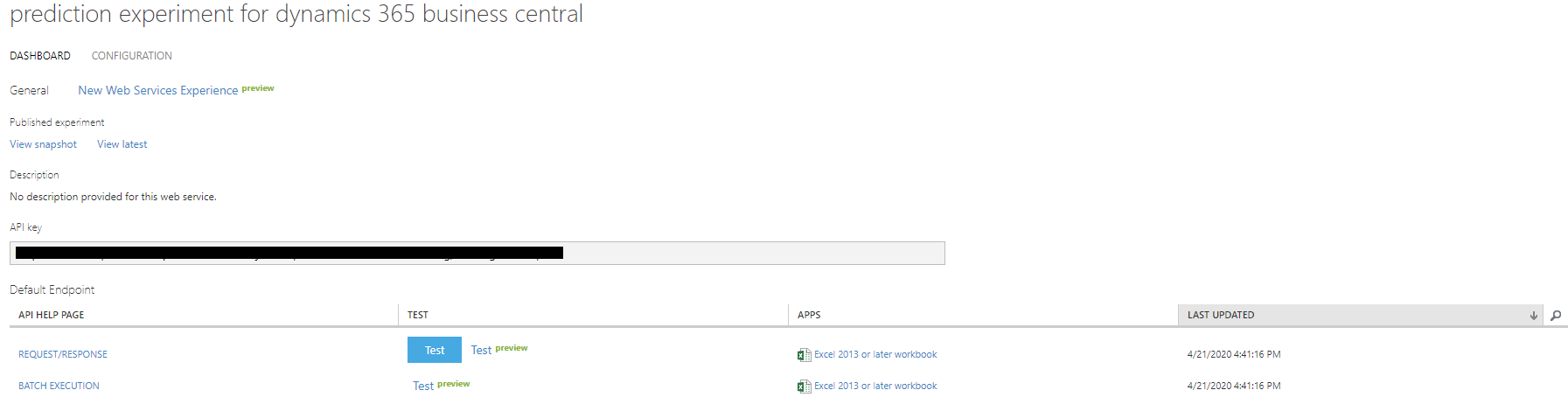
Tenga en cuenta la información que aparece en los campos URI de API y Clave de API. Puede usar estas credenciales para configurar el flujo de efectivo.
Seleccione el icono Buscar página, que abre la característica Dígame. Acceda a Configuración de predicción de pago atrasado y seleccione el vínculo relacionado.
Seleccione la opción Usar Mi suscripción a Azure.
En la ficha desplegable Mis credenciales de modelo, introduzca la URI de API (seleccione SOLICITUD/RESPUESTA y, a continuación, copie la URI de solicitud) y la Clave de API para su modelo.





El Modelo de predicción para Microsoft Dynamics 365 Business Central le ayuda a entrenar, evaluar y visualizar modelos con fines de predicción. Este modelo utiliza el módulo Ejecutar R Script para ejecutar los R scripts que realizan todas las tareas. Los dos módulos de entrada definen la estructura esperada de los conjuntos de datos de entrada. El primer módulo define la estructura del conjunto de datos, que es flexible y puede aceptar hasta 25 características. El segundo define los parámetros.
Cuando se llama a la API, necesita transferir varios parámetros:
method (cadena): parámetro obligatorio. Especifica el procedimiento de machine learning que se utilizará. El modelo admite los siguientes métodos:
train (el sistema decidirá si usa la clasificación o regresión en función de su conjunto de datos)
trainclassification
trainregression
predict
evaluate
plotmodel
Según el método seleccionado, es posible que necesite parámetros adicionales:
train_percent (numérico): obligatorio para los métodos train, trainclassification y trainregression. Especifica cómo dividir un conjunto de datos en conjuntos de entrenamiento y validación. El valor de 80 significa que el 80 por ciento del conjunto de datos se usará para entrenamiento y el 20 por ciento se usará para validar el resultado.
model (cadena; base64): obligatorio para los métodos predict, evaluate y plotmodel. Este parámetro es un modelo serializado de contenido y está codificado con Base64. Puede conseguir el parámetro model como resultado de los métodos train, trainclassification o trainregression.
captions (cadena): parámetro opcional que se utiliza con el método plotmodel. Este parámetro contiene subtítulos separados por comas para las funciones. Si no se transfiere, se utilizará Feature1..Feature25.
labels (cadena): parámetro opcional que se utiliza con el método plotmodel. Este parámetro contiene subtítulos alternativos separados por comas para las etiquetas. Si no se transfiere, se utilizan los valores reales.
dataset: necesario para los métodos train, trainclassification, trainregression, evaluate y predict, y consta de los siguientes parámetros.
Feature1..25: las características son los atributos descriptivos (también conocidos como dimensiones) que describen la observación única (registro en el conjunto de datos). Puede ser entero, decimal, booleano, opción, código o cadena.
Label: este parámetro es obligatorio, pero debe estar vacío para el método de predicción. La etiqueta es lo que está intentando predecir o pronosticar.
El resultado del servicio incluye los siguientes parámetros:
model (cadena; base64): resultado de la implementación de los métodos de train, trainclassification y trainregression. Este parámetro contiene el modelo serializado, codificado con Base64.
quality (numérico): resultado de la implementación de los métodos de train, trainclassification, trainregression y evaluate. En el experimento actual, puede utilizar la puntuación Precisión equilibrada como medida de la calidad de un modelo.
plot (aplicación/pdf; base64): resultado de implementar el método plotmodel. Este parámetro contiene la visualización del modelo en formato PDF, codificado con Base64.
dataset: resultado de implementar el método de predicción; consta de los siguientes parámetros:
Feature1..25: este parámetro es el mismo que el de la entrada.
Label: el valor previsto.
Confidence: la probabilidad de que la clasificación sea correcta.