Integración de consultas de Apache Spark y Hive LLAP
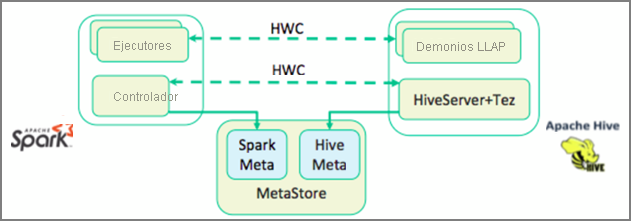
En la unidad anterior, vimos dos maneras de consultar datos estáticos almacenados en un clúster de Interactive Query: Data Analytics Studio y un cuaderno de Zeppelin Notebook. Pero ¿qué ocurre si quiere transmitir datos inmobiliarios nuevos a los clústeres mediante Spark y luego consultarlos con Hive? Dado que Hive y Spark tienen dos metastores diferentes, necesitan un conector que actúe como puente entre ambos. Dicho puente es Hive Warehouse Connector (HWC) de Apache. La biblioteca de Hive Warehouse Connector permite trabajar más fácilmente con Apache Spark y Apache Hive, ya que admite tareas como trasladar datos entre objetos DataFrame de Spark y tablas de Hive, así como dirigir datos de transmisión de Spark a tablas de Hive. No configuraremos el conector en nuestro escenario, pero es importante saber que existe la opción.
Apache Spark tiene una API de flujo estructurado que proporciona capacidades de transmisión que no están disponibles en Apache Hive. A partir de HDInsight 4.0, Apache Spark 2.3.1 y Apache Hive 3.1.0 tienen metastores independientes, lo que puede dificultar la interoperabilidad. El conector de Hive Warehouse simplifica el uso conjunto de Spark y Hive. La biblioteca de Hive Warehouse Connector carga los datos de los demonios de LLAP en ejecutores de Spark en paralelo. Esto hace que sea más eficaz y escalable que el uso de una conexión JDBC estándar de Spark a Hive.
Algunas de las operaciones compatibles con el conector de Hive Warehouse son:
- Descripción de una tabla
- Creación de una tabla para datos con formato ORC (Optimized Row Columnar)
- Selección de datos de Hive y recuperación de un elemento DataFrame
- Escritura de un elemento DataFrame en Hive en un lote
- Ejecución de una instrucción de actualización de Hive
- Lectura de datos de la tabla de Hive, transformación en Spark y escritura en una nueva tabla de Hive
- Escritura de un flujo de Spark o DataFrame en Hive mediante Hive Streaming
Cuando tenga implementados un clúster de Spark y un clúster de Interactive Query, configure las opciones del clúster de Spark en Ambari, que es una herramienta basada en web que se incluye en todos los clústeres de HDInsight. Para abrir Ambari, vaya a https://servername.azurehdinsight.net en el explorador de Internet, donde servername es el nombre del clúster de Interactive Query.
Para escribir datos de transmisión de Spark en las tablas, cree una tabla de Hive y empiece a escribir datos en ella. Después, ejecute las consultas en los datos de transmisión. Puede usar cualquiera de las opciones siguientes:
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy