Ejercicio: Carga y consulta de datos en HDInsight
Ahora que ha aprovisionado una cuenta de almacenamiento y un clúster de Interactive Query, es el momento de cargar los datos inmobiliarios y ejecutar algunas consultas. Para ello, cargará datos inmobiliarios de la ciudad de Nueva York. Incluyen más de 28 000 registros de propiedades, incluidas direcciones, precios de ventas, superficie e información de ubicación geocodificada para facilitar la asignación. Su empresa de inversión inmobiliaria usa esta información para determinar los precios adecuados para la superficie de las nuevas propiedades que salen al mercado, en función de los precios de venta de las propiedades que ya se han vendido.
Para cargar y consultar los datos, usaremos Data Analytics Studio, una aplicación basada en web que se instaló en la acción de script que usamos al crear el clúster de Interactive Query. Puede usar Data Analytics Studio para cargar datos en Azure Storage, transformar los datos en tablas de Hive con los tipos de datos y los nombres de columna que establezca y consultar los datos del clúster mediante HiveQL. Además de Data Analytics Studio, puede usar cualquier herramienta compatible con ODBC o JDBC para trabajar con los datos mediante Hive, como Spark & Hive Tools para Visual Studio Code.
Después, usará un cuaderno de Zeppelin Notebook para visualizar rápidamente las tendencias de los datos. Los cuadernos de Zeppelin Notebook permiten enviar consultas y ver los resultados en diversos gráficos predefinidos. Los cuadernos de Zeppelin Notebook instalados en los clústeres de Interactive Query tienen un intérprete de JDBC con un controlador de Hive.
Descarga de los datos inmobiliarios
- Vaya a https://github.com/Azure/hdinsight-mslearn/tree/master/Sample%20data y descargue el conjunto de datos para guardar el archivo propertysales.csv en el equipo.
Carga de los datos mediante Data Analytics Studio
- Ahora abra Data Analytics Studio en el explorador de Internet. Para ello, vaya a esta dirección URL, pero reemplace servername por el nombre del clúster que usó: https://servername.azurehdinsight.net/das/.
Para iniciar sesión, el nombre de usuario es admin, y la contraseña es la que creó.
Si se produce algún error, en la pestaña Información general del clúster en Azure Portal, asegúrese de que el estado está establecido en En ejecución y el tipo de clúster y la versión de HDI están establecidos en Interactive Query 3.1 (HDI 4.0).
- Data Studio Analytics se iniciará en el explorador de Internet.
- Haga clic en Base de datos en el menú de la izquierda, en el botón de puntos suspensivos verticales verdes y en Crear base de datos.
Asigne a la base de datos el nombre "newyorkrealestate" y haga clic en Crear.
En el Explorador de bases de datos, haga clic en el cuadro de nombre de la base de datos y seleccione newyorkrealestate.
- En el Explorador de bases de datos, haga clic en + y en Crear tabla.
- Asigne a la nueva tabla el nombre "propertysales" y haga clic en Cargar tabla. Los nombres de tabla solo deben contener letras minúsculas y números; no admiten caracteres especiales.
- En el área para seleccionar el formato de archivo de la página:
- Asegúrese de que el formato de archivo es CSV.
- Active la casilla Is first row header? (¿Es la primera fila un encabezado?).
- En el área para seleccionar el origen de archivo de la página:
- Seleccione Upload from Local (Cargar de ubicación local).
- Haga clic en Drag file to upload or click browse (Arrastre un archivo para cargarlo o haga clic en Examinar) y vaya al archivo propertysales.csv.
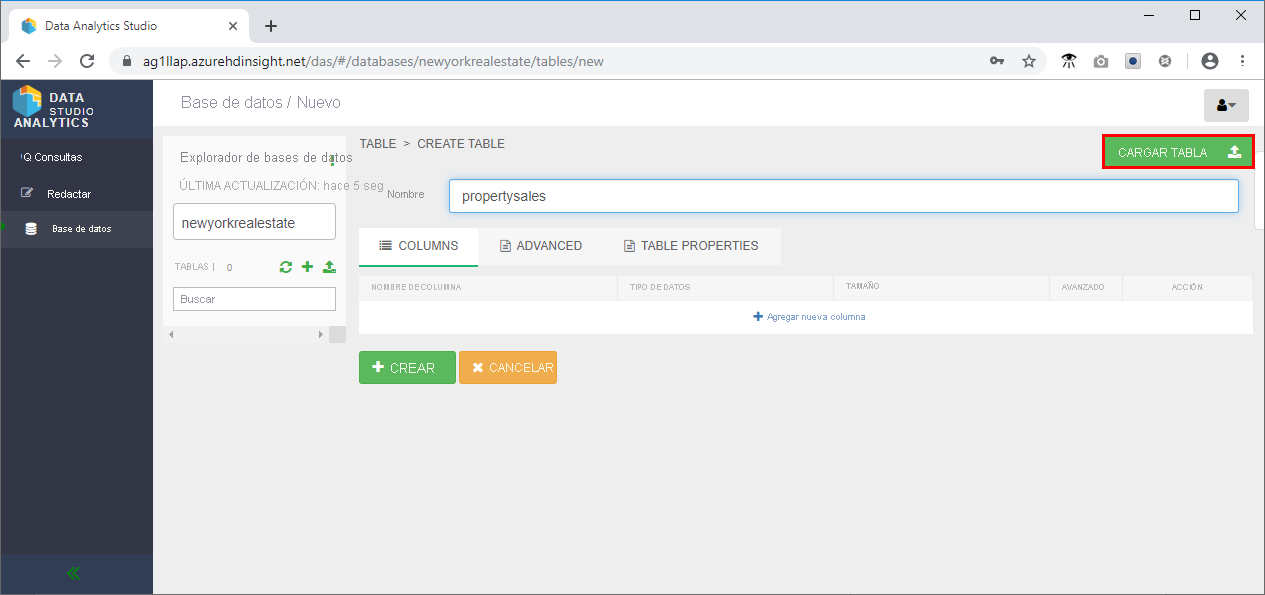
- En la sección Columnas, cambie el tipo de datos de la latitud y la longitud a String y el de la fecha de venta a Date.
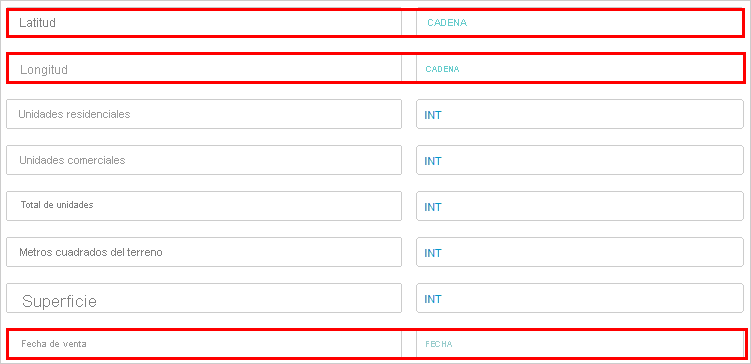
- Desplácese hacia arriba y revise la sección Vista previa de tabla para comprobar que los encabezados de columna son correctos.
- Desplácese hacia abajo del todo y haga clic en Crear para crear la tabla de Hive en la base de datos newyorkrealestate.

- En el menú de la izquierda, haga clic en Redactar.
- Pruebe la siguiente consulta de Hive para asegurarse de que todo funciona según lo previsto.
SELECT `ADDRESS`, `ZIP CODE`, `SALE PRICE`, `SQUARE FOOTAGE`
FROM newyorkrealestate.propertysales;
- La salida debe tener una apariencia similar a la siguiente.
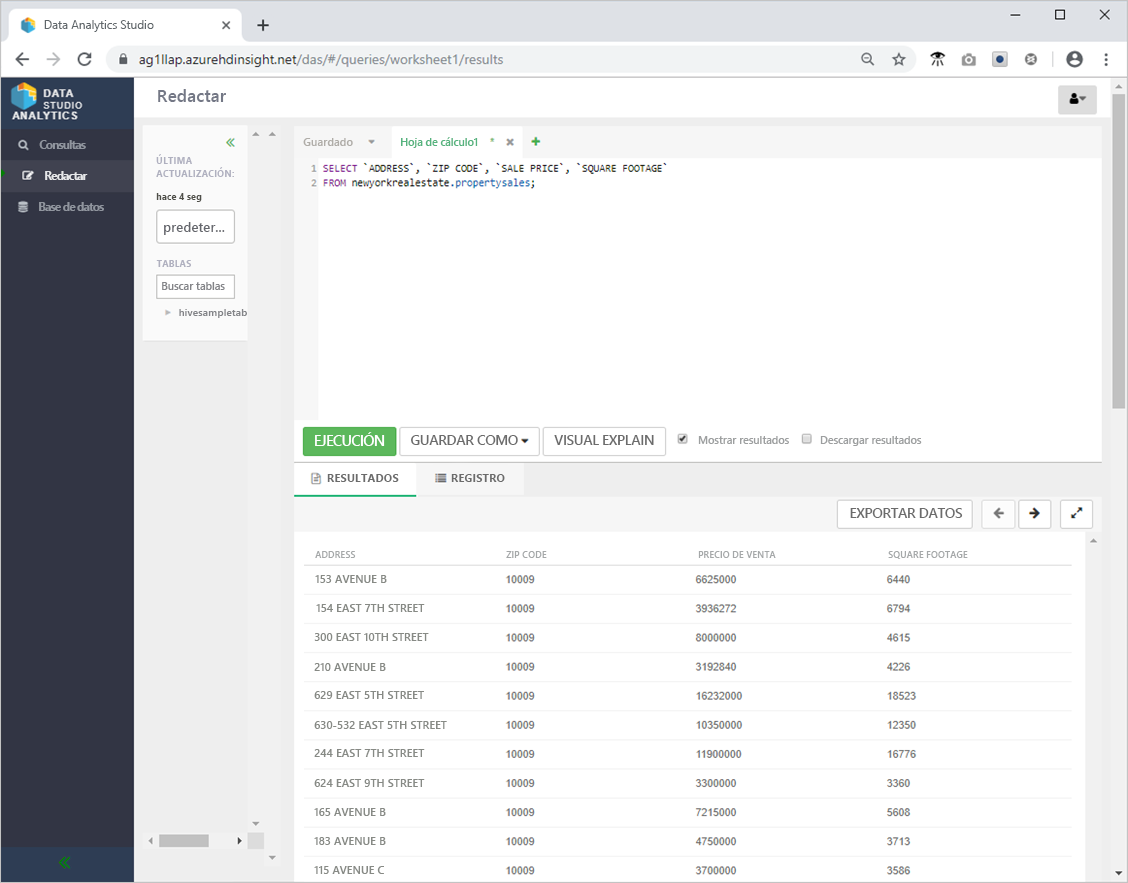
- Revise el rendimiento de la consulta. Para ello, haga clic en Consultas en el menú de la izquierda y seleccione la consulta SELECT
ADDRESS,ZIP CODE,SALE PRICE,SQUARE FOOTAGEFROM newyorkrealestate.propertysales que acaba de ejecutar.
Si hay recomendaciones de rendimiento disponibles, la herramienta las mostrará. En esta página también se muestra la consulta SQL real que se ejecutó, se proporciona una explicación visual de la consulta, se indican los detalles de configuración que infiere Hive al ejecutar la consulta y se ofrece una escala de tiempo en la que se detalla cuánto tiempo se invirtió en ejecutar cada parte de la consulta.
Exploración de las tablas de Hive mediante un cuaderno de Zeppelin Notebook
- En Azure Portal, en la página Información general, en el cuadro Panel de clúster, haga clic en Zeppelin Notebook.

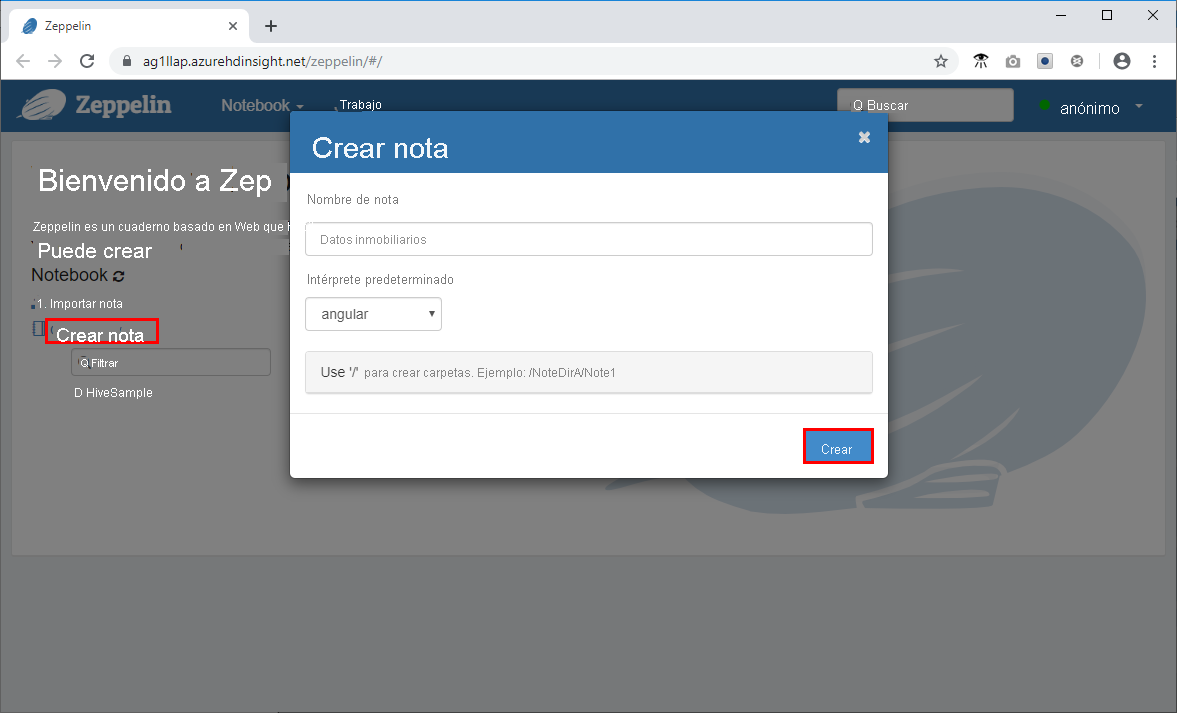
- Haga clic en Nueva nota, asigne a la nota el nombre Real Estate Data (Datos inmobiliarios) y haga clic en Crear.
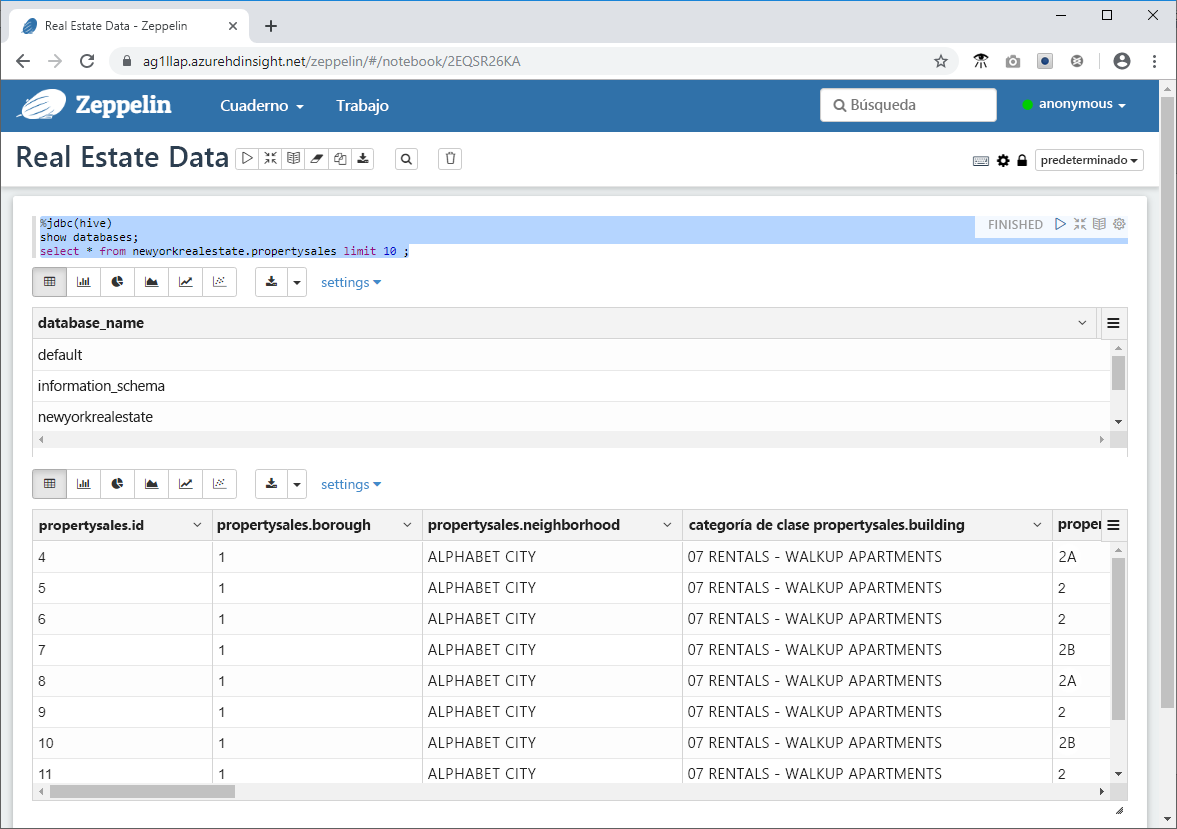
- Pegue el siguiente fragmento de código en el símbolo del sistema en la ventana de Zeppelin y haga clic en el icono de reproducción.
%jdbc(hive)
show databases;
select * from newyorkrealestate.propertysales limit 10 ;
Se mostrará en la ventana la salida de la consulta. Verá que se devuelven los 10 primeros resultados.
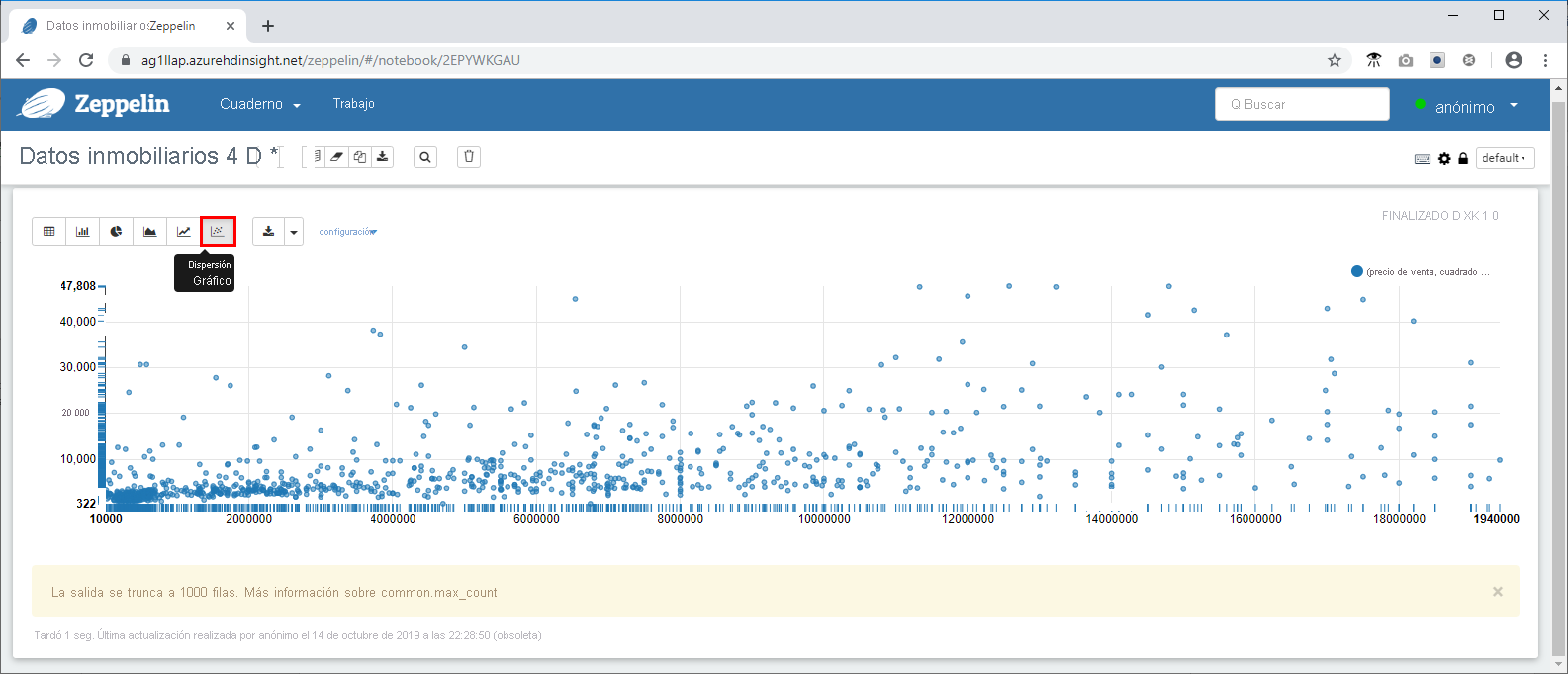
- Ahora realizará una consulta más compleja para usar algunas de las funcionalidades de visualización y gráficos disponibles en Zeppelin. Copie la consulta siguiente en el símbolo del sistema y haga clic en .
%jdbc(hive)
select `sale price`, `square footage` from newyorkrealestate.propertysales
where `sale price` < 20000000 AND `square footage` < 50000;
De forma predeterminada, la salida de la consulta se muestra en formato de tabla. En su lugar, seleccione Gráfico de dispersión para ver uno de los objetos visuales que proporcionan los cuadernos de Zeppelin Notebook.