Configuración de la terminación anticipada
El ajuste de hiperparámetros le ayuda a ajustar el modelo y a seleccionar los valores de hiperparámetros que harán que el modelo funcione mejor.
Sin embargo, encontrar el mejor modelo puede ser una conquista interminable. Siempre debe tener en cuenta si vale la pena el tiempo y el gasto de probar nuevos valores de hiperparámetros para encontrar un modelo que pueda funcionar mejor.
En cada prueba de un trabajo de barrido, se entrena un nuevo modelo con una nueva combinación de valores de hiperparámetros. Si el entrenamiento de un nuevo modelo no da como resultado un modelo significativamente mejor, es posible que quiera detener el trabajo de barrido y usar el modelo que mejor funcionó hasta el momento.
Al configurar un trabajo de barrido en Azure Machine Learning, también puede establecer un número máximo de pruebas. Un enfoque más sofisticado puede ser detener un trabajo de barrido cuando los nuevos modelos no producen resultados significativamente mejores. Para detener un trabajo de barrido en función del rendimiento de los modelos, puede usar una directiva de terminación anticipada.
Cuándo usar una directiva de terminación anticipada
La conveniencia de utilizar una directiva de terminación anticipada puede depender del espacio de búsqueda y del método de muestreo con el que se trabaje.
Por ejemplo, puede optar por usar un método de muestreo de cuadrícula en un espacio de búsqueda discreto que da como resultado un máximo de seis pruebas. Con seis pruebas, se entrenará un máximo de seis modelos y una directiva de terminación anticipada puede ser innecesaria.
Una directiva de terminación anticipada puede ser especialmente beneficiosa cuando se trabaja con hiperparámetros continuos en el espacio de búsqueda. Los hiperparámetros continuos presentan un número ilimitado de valores posibles entre los que elegir. Lo más probable es que quiera usar una directiva de terminación anticipada al trabajar con hiperparámetros continuos y un método de muestreo aleatorio o bayesiano.
Configuración de una directiva de terminación anticipada
Hay dos parámetros principales al elegir usar una directiva de terminación anticipada:
evaluation_interval: especifica en qué intervalo desea evaluar la directiva. Cada vez que se registra la métrica principal para una prueba cuenta como un intervalo.delay_evaluation: especifica cuándo empezar a evaluar la directiva. Este parámetro permite que se completen al menos un mínimo de pruebas sin una directiva de terminación anticipada que les afecte.
Es posible que los nuevos modelos sigan funcionando solo ligeramente mejor que los anteriores. Para determinar la medida en que un modelo debe funcionar mejor que las pruebas anteriores, hay tres opciones para la terminación anticipada:
- Directiva de ladrón: usa un
slack_factor(relativo) oslack_amount(absoluto). Cualquier modelo nuevo debe funcionar dentro del rango de holgura del modelo de mejor rendimiento. - Directiva de detención de mediana: usa la mediana de los promedios de la métrica principal. Cualquier nuevo modelo debe funcionar mejor que la mediana.
- Directiva de selección de truncamiento: usa un
truncation_percentage, que es el porcentaje de pruebas con menor rendimiento. Cualquier modelo nuevo debe funcionar mejor que las pruebas de menor rendimiento.
Directiva de bandidos
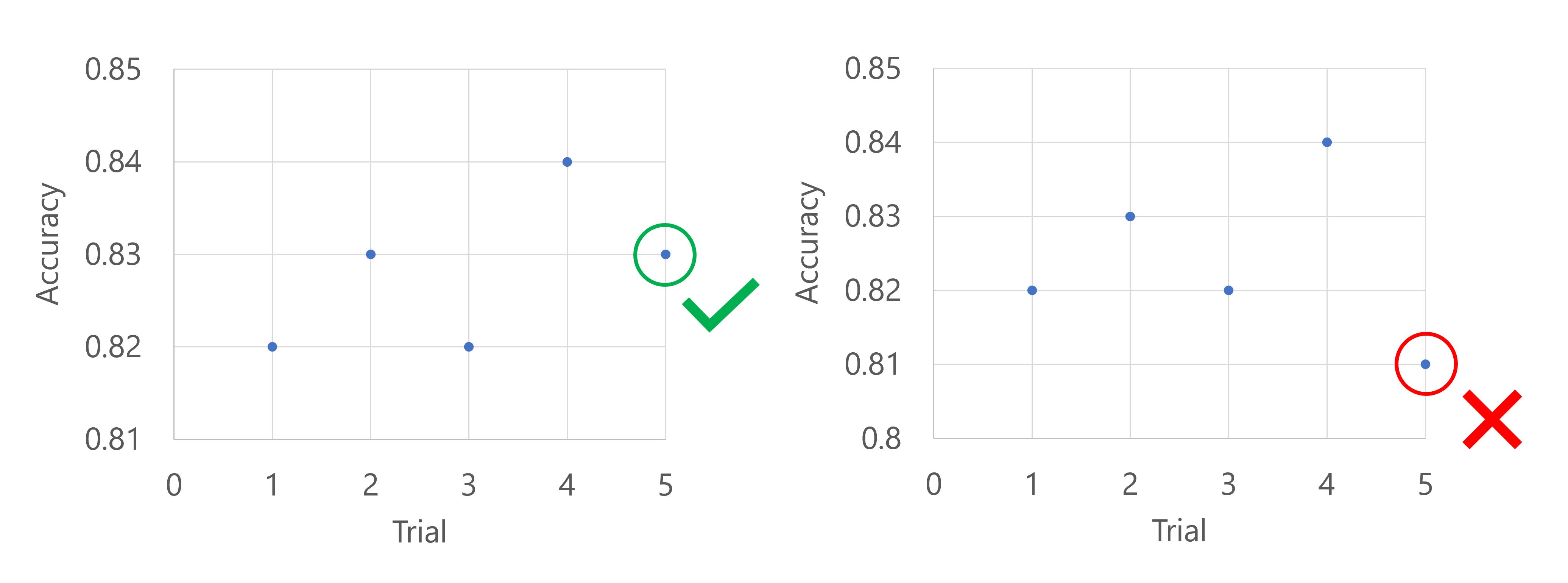
Puede usar una directiva de ladrón para detener una prueba si la métrica de rendimiento objetivo es inferior a la mejor prueba hasta el momento por un margen especificado.
Por ejemplo, el siguiente código aplica una directiva de ladrón con un retraso de cinco pruebas, evalúa la directiva en cada intervalo y permite una cantidad de holgura absoluta de 0,2.
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
Imagine que la métrica principal es la precisión del modelo. Cuando, después de las cinco primeras pruebas, el modelo que mejor funciona tiene una precisión de 0,9, cualquier modelo nuevo tiene que funcionar mejor que (0,9-0,2) o 0,7. Si la precisión del nuevo modelo es superior a 0,7, el trabajo de barrido continuará. Si el nuevo modelo tiene una puntuación de precisión inferior a 0,7, la directiva finalizará el trabajo de barrido.
También puede aplicar una directiva de ladrón mediante un factor de margen de demora, que compara la métrica de rendimiento como una proporción en lugar de un valor absoluto.
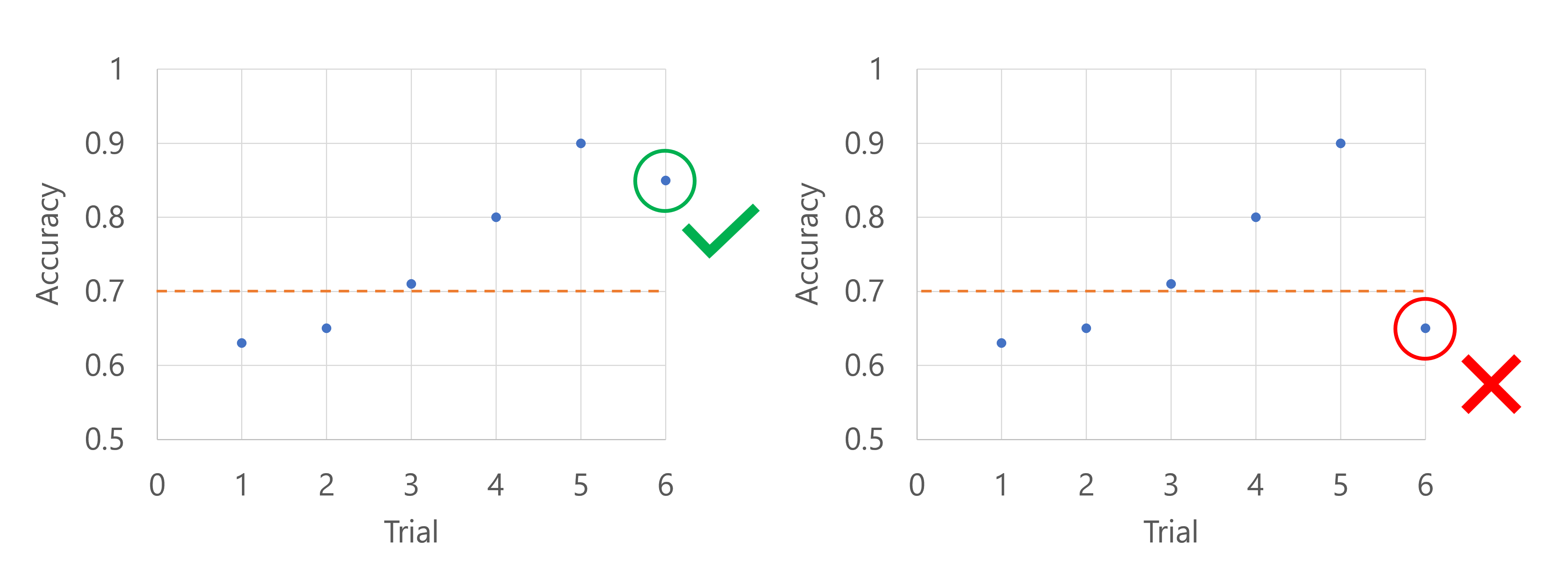
Directiva de mediana de detención
La directiva de detención de la mediana abandona las pruebas cuando la métrica de rendimiento de destino es inferior a la mediana del promedio de ejecuciones para todas las pruebas.
Por ejemplo, el código siguiente aplica una directiva de detención mediana con un retraso de cinco pruebas y evalúa la directiva a cada intervalo.
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
Imagine que la métrica principal es la precisión del modelo. Cuando se registra la precisión para la sexta prueba, la métrica debe ser mayor que la mediana de las puntuaciones de precisión hasta el momento. Supongamos que la mediana de las puntuaciones de precisión hasta ahora es 0,82. Si la precisión del nuevo modelo es superior a 0,82, el trabajo de barrido continuará. Si el nuevo modelo tiene una puntuación de precisión inferior a 0,82, la directiva detendrá el trabajo de barrido y no se entrenará ningún modelo nuevo.
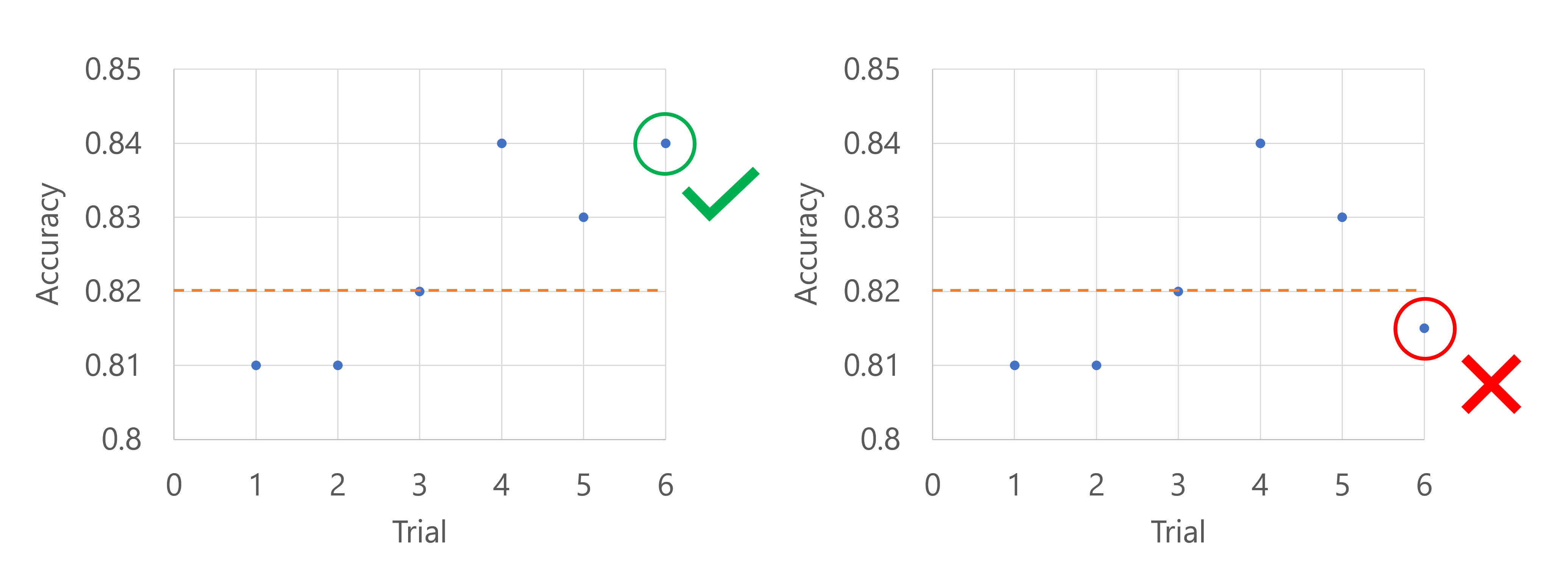
Directiva de selección de truncamiento
Una directiva de selección de truncamiento cancela el X % de ejecuciones con menor rendimiento en cada intervalo de evaluación en función del valor de truncation_percentage que especificó para X.
Por ejemplo, el código siguiente aplica una directiva de selección de truncamiento con un retraso de cuatro pruebas, evalúa la directiva en cada intervalo y usa un porcentaje de truncamiento del 20 %.
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
Imagine que la métrica principal es la precisión del modelo. Cuando se registra la precisión de la quinta prueba, la métrica no debe estar en el peor 20 % de las pruebas hasta el momento. En este caso, el 20 % se traduce en una prueba. En otras palabras, si la quinta prueba no es el modelo con peor rendimiento hasta el momento, el trabajo de barrido continuará. Si la quinta prueba tiene la puntuación de precisión más baja de todos los ensayos hasta el momento, el trabajo de barrido se detendrá.