Replicación de datos en un clúster secundario
Kafka se suele implementar en varios entornos para escenarios de recuperación ante desastres, alta disponibilidad e híbridos (entorno local y nube). En estos escenarios es necesario replicar los datos desde una instancia de Kafka a la otra mediante la característica de creación de reflejo de Apache Kafka. La creación de reflejo se puede ejecutar como un proceso continuo, o bien usarse de forma intermitente como método de migración de datos de un clúster a otro.
La creación de reflejo no debe considerarse como un medio para conseguir tolerancia a errores. El desplazamiento a los elementos de un tema es diferente entre los clústeres principales y secundarios, por lo que los clientes no pueden usarlos indistintamente.
¿Cómo funciona de creación de reflejo?
La creación de reflejo se realiza con la herramienta MirrorMaker (incluida en Apache Kafka), que consume los registros de los temas del clúster principal y crea una copia local en el clúster secundario. MirrorMaker usa uno o varios consumidores que leen los datos del clúster principal y un productor que los escribe en el clúster local (secundario).
La configuración de la creación de reflejo que resulta más útil para la recuperación ante desastres consiste en utilizar clústeres de Kafka en diferentes regiones de Azure. Para ello, se emparejan las redes virtuales en las que residen los clústeres.
En el siguiente diagrama, se ilustra el proceso de creación de reflejo y cómo fluye la comunicación entre los clústeres:
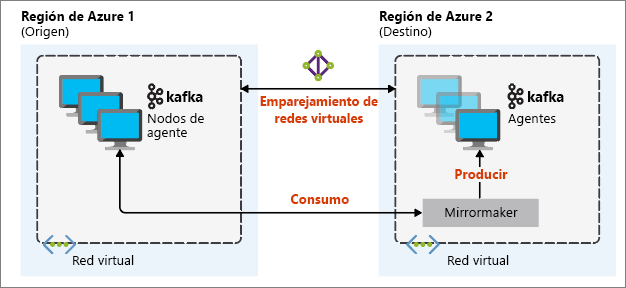
Los clústeres principales y secundarios pueden tener un número diferente de nodos y de particiones. Además, los desplazamientos dentro de los temas también son diferentes. La creación de reflejos conserva el valor de la clave que se utiliza para crear particiones, por lo que se mantiene el orden de los registros en una base por claves.
Creación de reflejo en los límites de red
Si tiene que crear un reflejo entre los clústeres Kafka en distintas redes, existen las siguientes consideraciones adicionales:
- Puertas de enlace: las redes deben poder comunicarse en el nivel TCP/IP.
- Direccionamiento del servidor: Si lo desea, puede direccionar los nodos del clúster utilizando direcciones IP o nombres de dominio completo.
- Direcciones IP: Si configura los clústeres de Kafka para que utilicen publicidad basada en direcciones IP, puede configurar la creación de reflejo utilizando las direcciones IP de los nodos de agentes y los nodos de Zookeeper.
- Nombres de dominio: Si no configura los clústeres de Kafka para que utilicen publicidad basada en direcciones IP, es necesario que los clústeres puedan conectarse entre sí utilizando los nombres de dominio completo (FQDN). Para ello, debe haber un Sistema de nombres de dominio (DNS) en cada red que esté configurado de forma que se reenvíen solicitudes a las demás redes. Al crear una instancia de Azure Virtual Network, en lugar de usar el DNS automático proporcionado con la red, debe especificar un servidor DNS personalizado y la dirección IP para el servidor. Una vez creada la red virtual, debe crear una máquina virtual de Azure que use esa dirección IP, y en ella instalar y configurar el software DNS.
Advertencia
Cree y configure el servidor DNS personalizado antes de instalar HDInsight en la red virtual. No es necesaria ninguna configuración adicional para que HDInsight use el servidor DNS configurado para la red virtual.