Ejercicio: Transmisión de datos de Kafka a un cuaderno de Jupyter Notebook y visualización de los datos
El clúster de Kafka ahora escribe datos en su registro, que se puede procesar mediante el flujo estructurado de Spark.
En el ejemplo que ha clonado se incluye un cuaderno de Spark, que tendrá que cargar en el clúster de Spark para usarlo.
Carga del cuaderno de Python en el clúster de Spark
En Azure Portal, haga clic en Inicio > Clústeres de HDInsight y, después, seleccione el clúster de Spark que acaba de crear (no el de Kafka).
En el panel Paneles de clúster, haga clic en Jupyter Notebook.

Cuando se le pidan las credenciales, escriba un nombre de usuario de administrador y la contraseña que ha creado al crear los clústeres. Se muestra el sitio web de Jupyter.
Haga clic en PySpark y, después, en la página de PySpark, haga clic en Cargar.
Vaya a la ubicación donde ha descargado el ejemplo de GitHub, seleccione el archivo RealTimeStocks.ipynb, haga clic en Abrir, después en Cargar y luego clic en Actualizar en el explorador de Internet.
Una vez que el cuaderno se cargue en la carpeta PySpark, haga clic en RealTimeStocks.ipynb para abrir el cuaderno en el explorador.
Ejecute la primera celda del cuaderno; para ello, coloque el cursor en la celda y presione Mayús+Entrar.
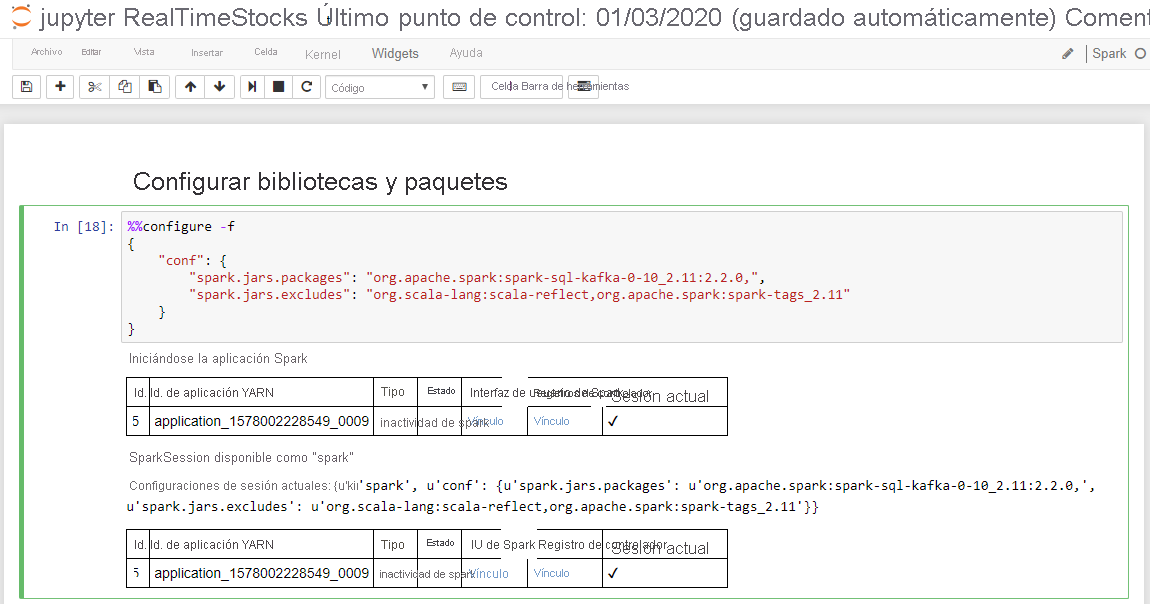
La celda Configure libraries and packages (Configurar bibliotecas y paquetes) se completa correctamente cuando muestra el mensaje Starting Spark application (Iniciando aplicación de Spark) e información adicional, como se muestra en la captura de pantalla siguiente.
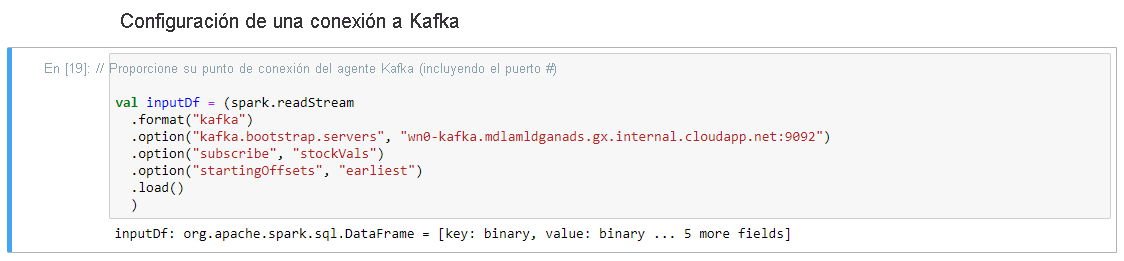
En la celda Set-up Connection to Kafka (Configurar la conexión a Kafka), en la línea .option("kafka.bootstrap.servers", ""), escriba el agente de Kafka entre el segundo conjunto de comillas. Por ejemplo. .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), y después presione Mayús+Entrar para ejecutar la celda.
La celda Set-up Connection to Kafka se completa correctamente cuando muestra el mensaje inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary... 5 more fields]. Spark usa la API readStream para leer los datos.
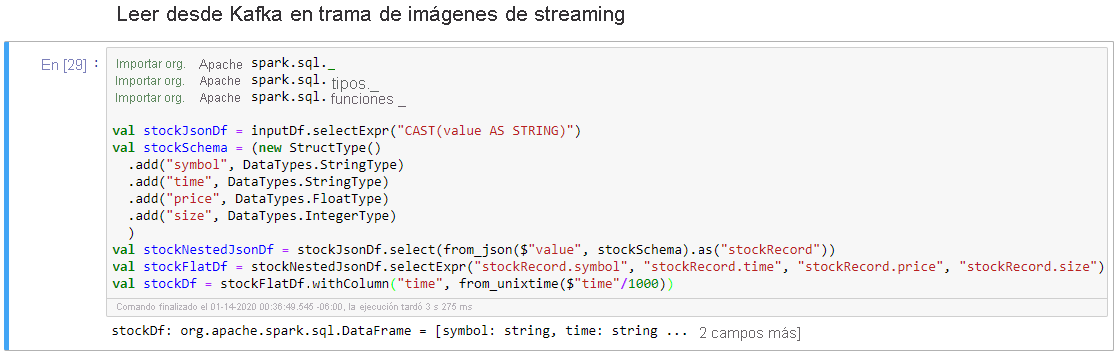
Seleccione la celda Read from Kafka into Streaming Dataframe (Leer desde Kafka en marco de datos de streaming) y, después, presione Mayús+Entrar para ejecutarla.
La celda se completa correctamente cuando muestra el siguiente mensaje: stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]
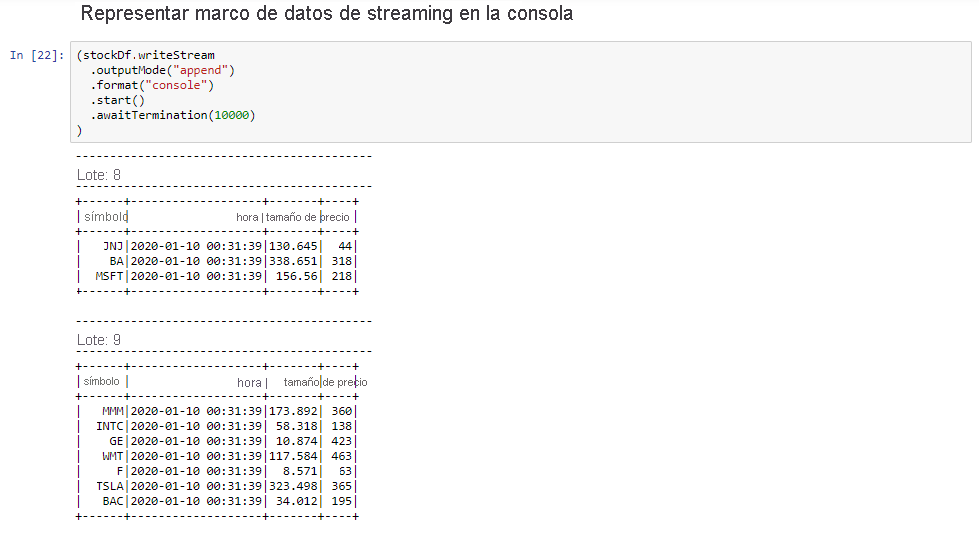
Seleccione la celda Output Streaming Dataframe to Console (Representar marco de datos de streaming en la consola) y, después, presione Mayús+Entrar para ejecutarla.
La celda se completa correctamente cuando muestra información similar a la siguiente. En la salida se muestra el valor de cada celda tal y como se ha pasado en el microlote, y hay un lote por segundo.
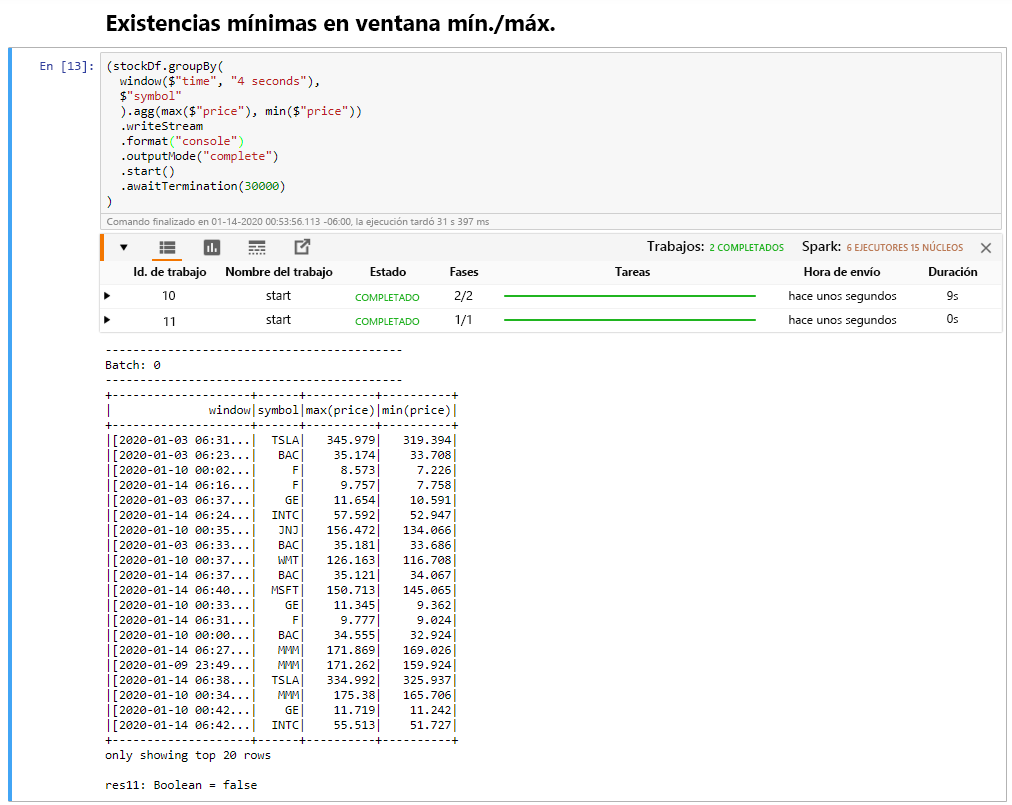
Seleccione la celda Windowed Stock Min / Max (Valor mínimo y máximo de la acción por periodo) y, después, presione Mayús+Entrar para ejecutarla.
La celda se completa correctamente cuando proporciona el precio máximo y mínimo para cada acción en el periodo de 4 segundos, que se define en la celda. Como se ha explicado en una unidad anterior, proporcionar información sobre periodos de tiempo específicos es una de las ventajas que se obtienen al usar el flujo estructurado de Spark.
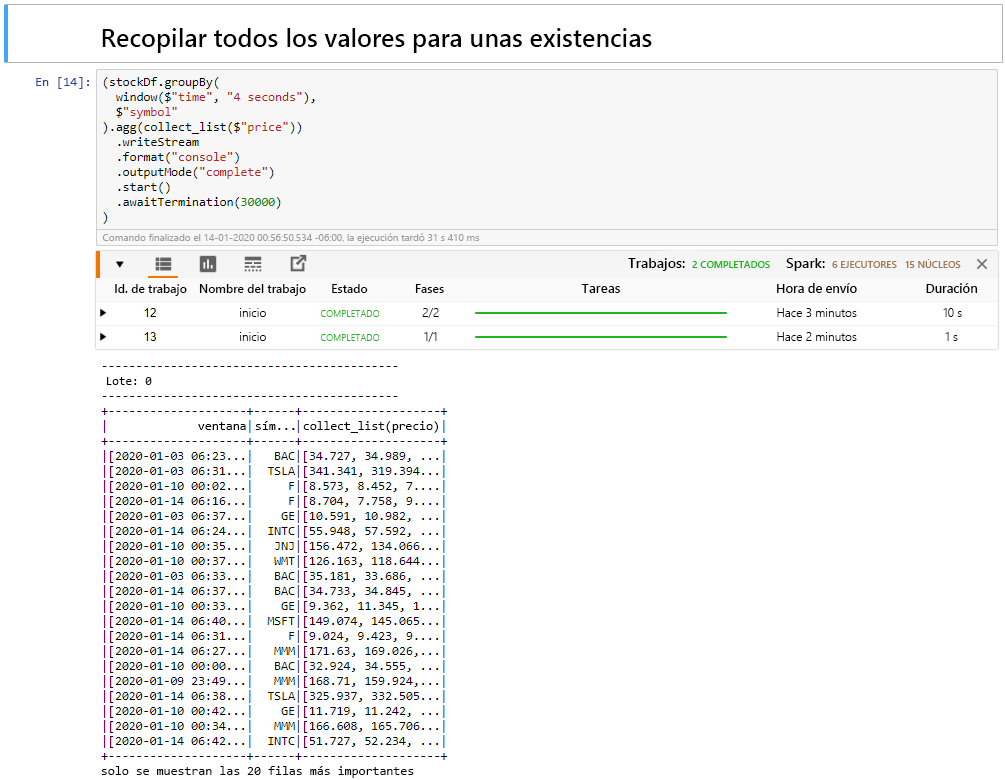
Seleccione la celda Collect all values for stocks in a window (Recopilar todos los valores de las acciones en un periodo) y, después, presione Mayús+Entrar para ejecutarla.
La celda se completa correctamente cuando proporciona una tabla con los valores de las acciones. outputMode se ha completado, de modo que se muestran todos los datos.
En esta unidad, ha cargado un cuaderno de Jupyter Notebook en un clúster de Spark, lo ha conectado al clúster de Kafka, ha generado los datos de streaming creados por el archivo de productor de Python en el cuaderno de Spark, ha definido un periodo de tiempo para los datos de streaming y ha mostrado los precios máximo y mínmo de las acciones en ese periodo, y ha mostrado todos los valores de la acción en la tabla. Enhorabuena, ha realizado correctamente el streaming estructurado con Spark y Kafka.