Selección de la biblioteca MPI correcta
Las SKU HB120_v2, HB60 y HC44 admiten interconexiones de red de InfiniBand. Como PCI Express se virtualiza mediante la virtualización de entrada/salida de raíz única (SR-IOV), todas las bibliotecas de MPI más populares (HPCX, OpenMPI, Intel MPI, MVAPICH y MPICH) están disponibles en estas VM de HPC.
La limitación actual para un clúster de HPC que se puede comunicar por medio de InfiniBand es de 300 máquinas virtuales. En la tabla siguiente se muestra el número máximo de procesos paralelos que se admiten en aplicaciones de MPI estrechamente acopladas que se comunican por medio de InfiniBand.
| SKU | Máximo de procesos paralelos |
|---|---|
| HB120_v2 | 36 000 procesos |
| HC44 | 13 200 procesos |
| HB60 | 18 000 procesos |
Nota:
Es posible que estos límites cambien en el futuro. Si tiene un trabajo de MPI estrechamente acoplado para el que se necesite un límite superior, envíe una solicitud de soporte técnico. Es posible que por su situación se aumenten los límites.
Si una aplicación de HPC recomienda una biblioteca de MPI concreta, pruebe esa versión primero. Si tiene flexibilidad en cuanto a la MPI que puede elegir y quiere el mejor rendimiento, pruebe HPCX. En general, la MPI HPCX realiza el mejor uso del marco UCX para la interfaz de InfiniBand y aprovecha todas las funciones de hardware y software de Mellanox InfiniBand.
En la ilustración siguiente se comparan las arquitecturas de biblioteca MPI populares.
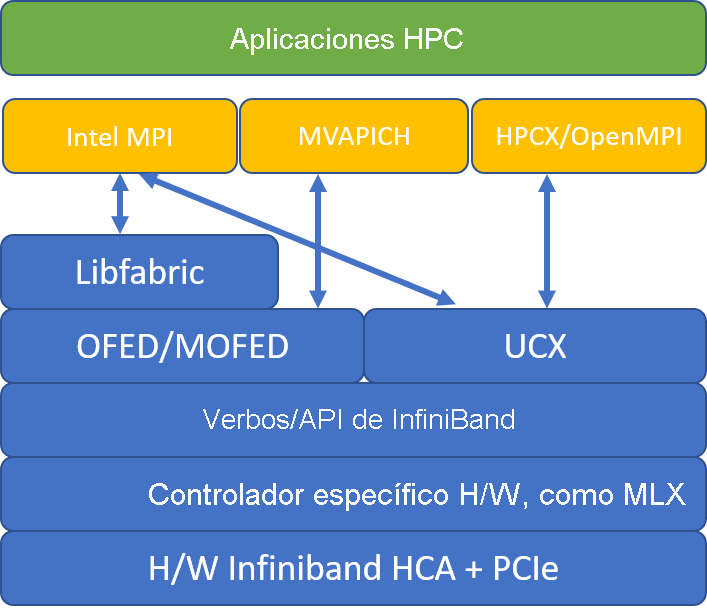
HPCX y OpenMPI son compatibles con ABI, por lo que puede ejecutar dinámicamente una aplicación de HPC con HPCX que se compiló con OpenMPI. De forma similar, Intel MPI, MVAPICH y MPICH son compatibles con ABI.
El par de colas 0 no es accesible para la máquina virtual invitada, a fin de evitar vulnerabilidades de seguridad por medio del acceso de hardware de bajo nivel. Esto no debería tener ningún efecto en las aplicaciones de HPC del usuario final, pero podría impedir que algunas herramientas de bajo nivel funcionen correctamente.
Argumentos mpirun de HPCX y OpenMPI
El siguiente comando muestra algunos argumentos de mpirun recomendados para HPCX y OpenMPI:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
En ese comando:
| Parámetro | Descripción |
|---|---|
$NPROCS |
Especifica el número de procesos de MPI. Por ejemplo: -n 16. |
$HOSTFILE |
Especifica un archivo que contiene el nombre de host o la dirección IP, para indicar la ubicación de dónde se ejecutan los procesos de MPI. Por ejemplo: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Especifica el número de procesos MPI que se ejecutan en cada dominio NUMA. Por ejemplo, para especificar cuatro procesos de MPI por NUMA, use --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Especifica el número de subprocesos por proceso de MPI. Por ejemplo, para especificar un proceso de MPI y cuatro procesos por NUMA, use --map-by ppr:1:numa:pe=4. |
-report-bindings |
Imprime la asignación de procesos de MPI a núcleos, lo que resulta útil para comprobar que el anclaje del procesos de MPI es correcto. |
$MPI_EXECUTABLE |
Especifica el ejecutable de MPI compilado mediante la vinculación en bibliotecas MPI. Los contenedores del compilador de MPI lo hacen automáticamente. Por ejemplo, mpicc o mpif90. |
Si sospecha que la aplicación de MPI estrechamente acoplada realiza una cantidad excesiva de comunicaciones colectivas, puede intentar habilitar las colectivas jerárquicas (HCOLL). Para habilitar esas características, use los parámetros siguientes:
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Argumentos de mpirun de Intel MPI
La versión Intel MPI 2019 cambió del marco Open Fabrics Alliance (OFA) al marco Open Fabrics Interfaces (OFI), y actualmente admite libfabric. Hay dos proveedores para la compatibilidad con InfiniBand: mlx y verbs. El proveedor mlx es el preferido para las máquinas virtuales HB y HC.
Estos son algunos argumentos de mpirun sugeridos para Intel MPI 2019 update 5+:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
En esos argumentos:
| Parámetros | Descripción |
|---|---|
FI_PROVIDER |
Especifica qué proveedor libfabric se va a usar, lo que afecta a la API, el protocolo y la red usados. verbs es otra opción, pero por lo general mlx ofrece un mejor rendimiento. |
I_MPI_DEBUG |
Especifica el nivel de salida de depuración adicional, que puede proporcionar detalles sobre dónde se anclan los procesos y qué protocolo y red se usan. |
I_MPI_PIN_DOMAIN |
Especifica cómo se quieren anclar los procesos. Por ejemplo, puede anclar a núcleos, sockets o dominios NUMA. En este ejemplo, establecerá esta variable de entorno en numa, lo que significa que los procesos se anclan a dominios de nodo NUMA. |
Hay otras opciones que puede probar, especialmente si las operaciones colectivas consumen una cantidad de tiempo considerable. Intel MPI 2019 update 5+ admite el proveedor mlx y usa el marco UCX para comunicarse con InfiniBand. También admite HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Argumentos de mpirun de MVAPICH
La lista siguiente contiene varios argumentos de mpirun recomendados:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
En esos argumentos:
| Parámetros | Descripción |
|---|---|
MV2_CPU_BINDING_POLICY |
Especifica la directiva de enlace que se va a usar, que afectará a cómo se anclan los procesos a los identificadores de núcleo. En este caso, se especifica scatter, por lo que los procesos se distribuyen de manera uniforme entre los dominios NUMA. |
MV2_CPU_BINDING_LEVEL |
Especifica dónde anclar los procesos. En este caso, se establece en numanode, lo que significa que los procesos se anclan a las unidades de los dominios NUMA. |
MV2_SHOW_CPU_BINDING |
Especifica si se quiere obtener información de depuración sobre dónde están anclados los procesos. |
MV2_SHOW_HCA_BINDING |
Especifica si se quiere obtener información de depuración sobre qué adaptador de canal de host usa cada proceso. |