Consideraciones sobre el anclaje de procesos
¿Por qué anclar procesos y subprocesos?
Ancle siempre los procesos a núcleos específicos con el fin de obtener el rendimiento máximo y más coherente entre ejecuciones.
Anclaje de procesos:
Maximiza el ancho de banda de memoria mediante la colocación o el anclaje de los procesos en ubicaciones que usan todos los canales de memoria y los distribuyen de forma equitativa entre los núcleos.
Mejora el rendimiento de punto flotante garantizando que cada proceso está en un núcleo propio. Esto elimina la posibilidad de que dos procesos se destinen al mismo núcleo.
Optimiza el movimiento de datos entre los procesos colocando los procesos que se comunican en nodos de dominio de acceso a memoria no uniforme (NUMA). Esto garantiza que tienen la latencia más baja y el ancho de banda más alto.
Reduce la sobrecarga del sistema operativo y proporciona resultados más coherentes, ya que el sistema operativo no puede trasladar los procesos a otros núcleos o dominios NUMA.
¿Dónde se anclan los procesos y subprocesos?
Para determinar dónde anclar los procesos y los subprocesos, primero debe entender la topología del procesador y la memoria, en concreto el número y la ubicación de los dominios NUMA.
La utilidad lstopo-no-graphics (de hwloc rpm) e Intel Memory Latency Checker (MLC)l son herramientas útiles para determinar la topología del procesador y la memoria. Por ejemplo: ¿Cuántos dominios NUMA tiene la máquina virtual? ¿Qué núcleos son miembros de cada dominio NUMA? ¿Cuál es la latencia y el ancho de banda de los procesos de cada dominio NUMA a medida que se comunican entre sí?
La siguiente imagen muestra el mapa de latencia del dominio NUMA de HB120_v2 generado por Intel MLC. Cuanto menor sea la latencia entre los dominios NUMA, más rápida es la comunicación entre ellos. En la ilustración se muestra claramente que HB120_v2 tiene 30 dominios NUMA y cuáles están en cada socket. También se muestra qué dominios NUMA se pueden agrupar para lograr la menor latencia de transferencia de datos y comunicación.

Los procesadores Intel tienen seis canales de memoria y los AMD EPYC ocho. Asegúrese de que usa todos los canales de memoria para maximizar el ancho de banda de memoria disponible. Para hacerlo, distribuya los procesos paralelos de manera uniforme entre los dominios de nodos NUMA. Para las aplicaciones paralelas híbridas, mantenga la agrupación de procesos y subprocesos en los mismos dominios NUMA; lo ideal es compartir la misma caché L3. Asegúrese de que el número total de subprocesos no supera el número total de núcleos.
En la imagen siguiente se muestra una SKU de HC44 con 2 dominios NUMA y 44 núcleos.
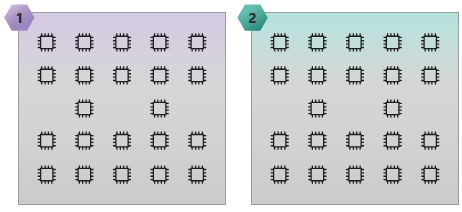
En la imagen siguiente se muestra una SKU de HB60 con 15 dominios NUMA y 60 núcleos.
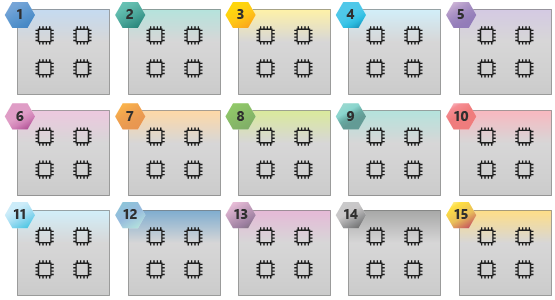
Aplicaciones limitadas por ancho de banda de memoria
Si tiene una aplicación enlazada por ancho de banda de memoria, puede obtener un mejor rendimiento en la máquina virtual reduciendo el número de procesos y subprocesos paralelos en cada dominio de nodo NUMA. Esto puede proporcionar más ancho de banda de memoria por proceso y, posiblemente, reducir el tiempo de reloj.
Por ejemplo, si usa HB120_v2 SKU con 30 dominios de nodo NUMA, puede intentar ejecutar 1, 2 y 3 procesos y subprocesos por dominio de nodo NUMA (por ejemplo, 30, 60 y 90 procesos y subprocesos por máquina virtual). Después, puede ver qué configuración proporciona el mejor rendimiento.