Registro y servicio de modelos con MLflow
El registro de modelos permite que MLflow y Azure Databricks lleven un seguimiento de los modelos, algo que resulta importante por dos motivos:
- El registro de un modelo le permite proporcionar el modelo para la inferencia por lotes, streaming o en tiempo real. El registro facilita el proceso de uso de un modelo entrenado, ya que ahora los científicos de datos no tienen que desarrollar código de aplicación; el proceso de servicio compila ese contenedor y expone automáticamente una API REST o un método para la puntuación por lotes.
- Registrar un modelo le permite crear versiones nuevas de ese modelo a lo largo del tiempo, lo que le ofrece la oportunidad de realizar un seguimiento de los cambios en el modelo e incluso realizar comparaciones entre diferentes versiones históricas de los modelos.
Registro de un modelo
Al ejecutar un experimento para entrenar un modelo, puede registrar el modelo mismo como parte de la ejecución del experimento, tal como se muestra aquí:
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model = model,
artifact_path=unique_model_name,
conda_env=mlflow.spark.get_default_conda_env())
Al revisar la ejecución del experimento, incluidas las métricas registradas que indican qué tan precisas son las predicciones del modelo, el modelo se incluye en los artefactos de la ejecución. Luego, puede seleccionar la opción para registrar el modelo mediante la interfaz de usuario en el visor de experimentos.
Como alternativa, si desea registrar el modelo sin revisar las métricas de la ejecución, puede incluir el parámetro registered_model_name en el método log_model, en cuyo caso el modelo se registra automáticamente durante la ejecución del experimento.
with mlflow.start_run():
# code to train model goes here
# log the model itself (and the environment it needs to be used)
unique_model_name = "my_model-" + str(time.time())
mlflow.spark.log_model(spark_model=model,
artifact_path=unique_model_name
conda_env=mlflow.spark.get_default_conda_env(),
registered_model_name="my_model")
Puede registrar varias versiones de un modelo, lo que le permite comparar el rendimiento de las versiones del modelo durante un período de tiempo antes de mover todas las aplicaciones cliente a la versión con el mejor rendimiento.
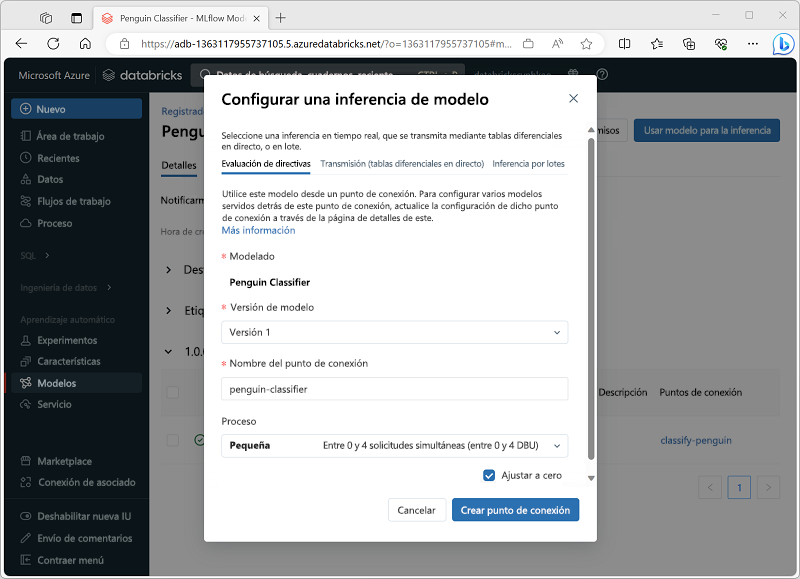
Uso de un modelo para la inferencia
El proceso de usar un modelo para predecir etiquetas a partir de datos de características nuevos se conoce como inferencia. Puede usar MLflow en Azure Databricks para que los modelos estén disponibles para la inferencia de estas maneras:
- Hospede el modelo como un servicio en tiempo real con un punto de conexión HTTP al que las aplicaciones cliente pueden realizar solicitudes REST.
- Use el modelo para realizar la inferencia de streaming perpetuo de etiquetas en función de una tabla delta de características, escribiendo los resultados en una tabla de salida.
- Use el modelo para la inferencia por lotes en función de una tabla delta, escribiendo los resultados de cada operación por lotes en una carpeta específica.
Puede implementar un modelo para la inferencia desde su página en la sección Modelos del portal de Azure Databricks, tal como se muestra aquí: