Optimización del sistema de origen: avanzado
Esta guía más avanzada puede resultar útil para la exportación de origen de sistemas VLDB:
División de tablas de identificadores de fila de Oracle
SAP ha publicado la nota de SAP 1043380, que contiene un script con el que la cláusula WHERE de un archivo WHR se convierte en un valor ROW ID. Como alternativa, las últimas versiones de SAPInst generan de forma automática archivos WHR divididos por ROW ID si SWPM se ha configurado para la migración de Oracle a R3load de Oracle. Los archivos STR y WHR generados por SWPM son independientes del sistema operativo y de la base de datos (al igual que todos los aspectos del proceso de migración del sistema operativo o la base de datos).
La nota de OSS contiene la instrucción "ROWID table splitting CANNOT be used if the target database is a non-Oracle database" (NO se puede usar la división de tablas por ROWID si la base de datos de destino no es de Oracle). Técnicamente, los archivos de volcado de R3load son independientes de la base de datos y del sistema operativo. Sin embargo, existe una restricción, que no es posible reiniciar ningún paquete durante su importación en SQL Server. En este escenario, se debe anular toda la tabla y reiniciar todos sus paquetes. Siempre se recomienda terminar las tareas de R3load para una tabla de división específica, aplicar TRUNCATE a la tabla y reiniciar todo el proceso de importación si se anula una instancia de R3load dividida. El motivo es que el proceso de recuperación integrado en R3load implica la aplicación de instrucciones DELETE individuales fila por fila para eliminar los registros cargados por el proceso R3load que se anula. Esto es lento y, con frecuencia, causará situaciones de bloqueo en la base de datos. La experiencia ha demostrado que es más rápido comenzar la importación de esta tabla específica desde el principio, por lo que la limitación mencionada en la nota de SAP 1043380 no es una limitación.
ROW ID tiene la desventaja de que el cálculo de las divisiones debe realizarse durante el tiempo de inactividad; consulte la nota de SAP 1043380.
Creación de varios "clones" de la base de datos de origen y exportación en paralelo
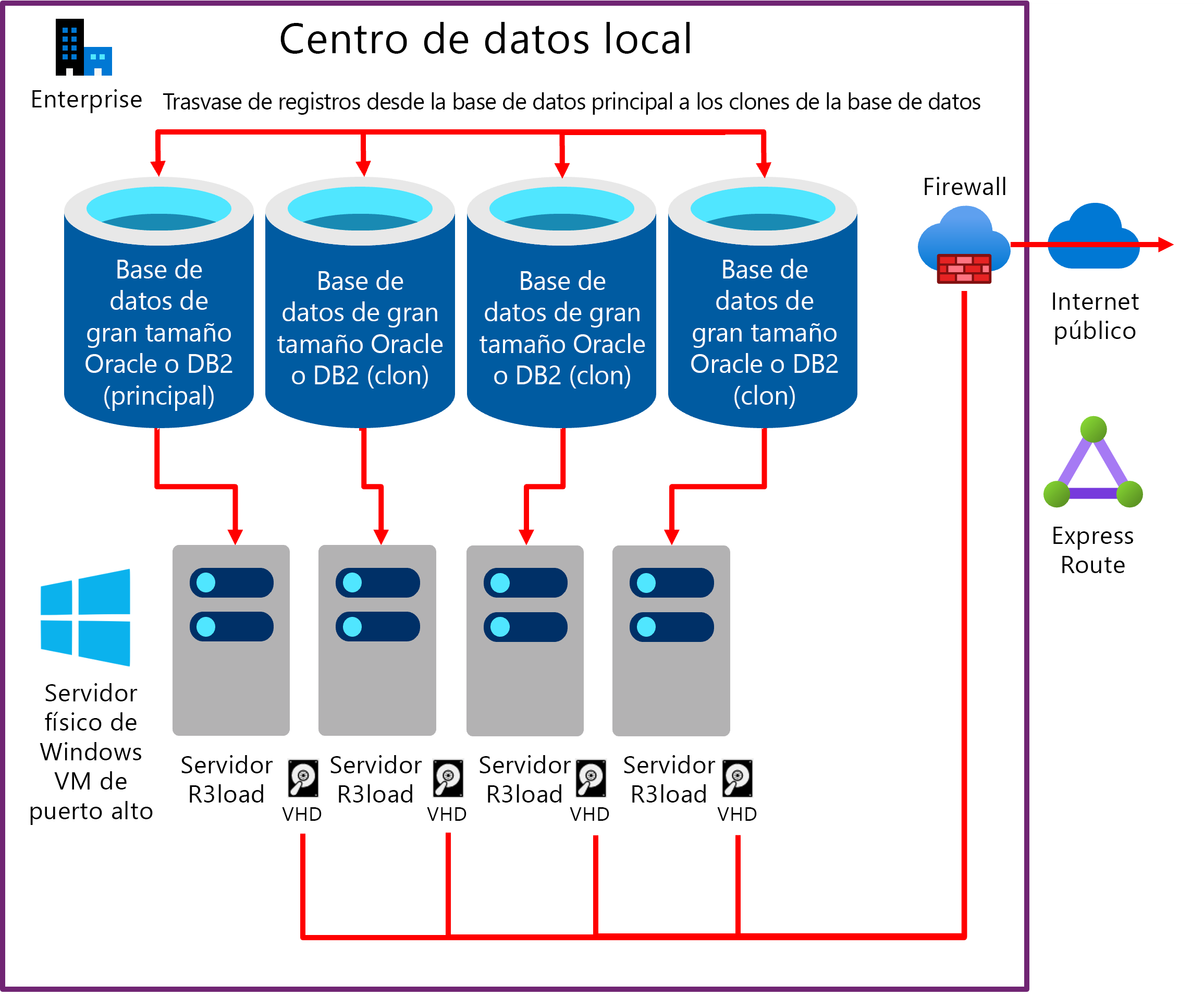
Un método para aumentar el rendimiento de la exportación consiste en exportar desde varias copias de la misma base de datos. Si la infraestructura subyacente (incluidos los servidores, la red y el almacenamiento) es escalable, este enfoque tiende a ser escalable de forma lineal. La exportación desde dos copias de la misma base de datos es el doble de rápida y, por consiguiente, desde cuatro copias es cuatro veces más rápida. Migration Monitor está configurado para exportar en un número seleccionado de tablas de cada "clon" de la base de datos. En el caso siguiente, la carga de trabajo de exportación se distribuye de forma que recaiga aproximadamente en un 25 % en cada uno de los cuatro servidores de base de datos.
- Servidor de base de datos 1 y servidor de exportación 1: dedicados a las tablas de 1 a 4 más grandes (en función de la asimetría de la distribución de datos en la base de datos de origen)
- Servidor de base de datos 2 y servidor de exportación 2: dedicados a las tablas con divisiones de tabla
- Servidor de base de datos 3 y servidor de exportación 3: dedicados a las tablas con divisiones de tabla
- Servidor de base de datos 4 y servidor de exportación 4: todas las tablas restantes
Se debe tener mucho cuidado para garantizar que las bases de datos se sincronicen con precisión, ya que, de lo contrario, podrían producirse una pérdida de datos o incoherencias entre estos. Si se siguen con exactitud los pasos que se proporcionan, se mantendrá la integridad de los datos.
La técnica es sencilla y barata con el hardware estándar de Intel, pero también es posible para los clientes que ejecutan hardware de UNIX de su propiedad. Los recursos esenciales de hardware están libres hacia la mitad de un proyecto de migración de sistema operativo o base de datos, cuando los sistemas de espacio aislado, desarrollo, control de calidad, entrenamiento y recuperación ante desastres ya se han pasado a Azure. No existe ningún requisito estricto de que los servidores "clonados" tengan recursos de hardware idénticos. Con un rendimiento adecuado de CPU, RAM, disco y red, la adición de cada clon aumenta el rendimiento.
Si aun así se necesita un rendimiento de exportación adicional, abra un incidente de SAP en BC-DB-MSS a fin de obtener los pasos adicionales para aumentar el rendimiento de las exportaciones (solo consultores avanzados).
Los pasos para implementar una exportación paralela múltiple son los siguientes:
- Realice una copia de seguridad de la base de datos principal y restáurela en un número "n" de servidores (donde n es el número de clones). En este ejemplo, supongamos que n = 3 servidores, lo que hace un total de cuatro servidores de base de datos.
- Restaure la copia de seguridad en tres servidores.
- Establezca el trasvase de registros desde el servidor de base de datos de origen principal a los tres servidores "clonados" de destino.
- Supervise el trasvase de registros durante varios días y asegúrese de que funcione de forma confiable.
- Al inicio del tiempo de inactividad, apague todos los servidores de aplicaciones SAP excepto el PAS. Asegúrese de que tanto el procesamiento por lotes al completo como todo el tráfico RFC se hayan detenido.
- En la transacción SM02, escriba el texto "Checkpoint PAS Running". Esto actualiza la tabla TEMSG.
- Detenga el servidor de aplicaciones principal. SAP está apagado. No se pueden realizar más actividades de escritura en la base de datos de origen. Asegúrese de que no haya ninguna aplicación que no sea SAP conectada a la base de datos de origen (no debería haberla nunca, pero compruebe si hay sesiones que no sean SAP en el nivel de base de datos).
- Ejecute esta consulta en el servidor de base de datos principal:
SELECT EMTEXT FROM [schema].TEMSG; - Ejecute la instrucción de nivel DBMS nativa:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(la sintaxis exacta depende del DBMS de origen. INSERT en EMTEXT). - Detenga las copias de seguridad automáticas del registro de transacciones. Ejecute manualmente una última copia de seguridad del registro de transacciones en el servidor de base de datos principal. Asegúrese de que la copia de seguridad del registro se copie en los servidores clonados.
- Restaure la última copia de seguridad del registro de transacciones en los tres nodos.
- Recupere la base de datos en los tres nodos "clonados".
- Ejecute la siguiente instrucción SELECT en los cuatro nodos:
SELECT EMTEXT FROM [schema].TEMSG; - Capture los resultados de la pantalla de la instrucción SELECT para cada uno de los cuatro servidores de base de datos (el principal y los tres clones). Asegúrese de incluir cada uno de los nombres de host (para que sirva como prueba de que la base de datos clonada y la principal son idénticas y contienen los mismos datos del mismo momento dado).
- Inicie export_monitor.bat en cada servidor de exportación de Intel R3load.
- Inicie el proceso de copia del archivo de volcado en Azure (AzCopy o Robocopy).
- Inicie import_monitor.bat en las máquinas virtuales de Azure de R3load.
En el diagrama siguiente se muestra un trasvase de registros de servidor de base de datos de producción existente a instancias de bases de datos "clonadas". Cada servidor de base de datos tiene uno o más servidores Intel R3load.