Control de similitudes entre entornos mediante flujos de trabajo reutilizables
Al implementar los cambios en varios entornos, los pasos implicados en la implementación en cada entorno son similares o incluso idénticos. En esta unidad, aprenderá a diseñar los flujos de trabajo para evitar la repetición y permitir la reutilización del código del flujo de trabajo.
Implementación en varios entornos
Después de hablar con sus compañeros en el equipo del sitio web, decide aplicar el siguiente flujo de trabajo para el sitio web de la empresa de juguetes:
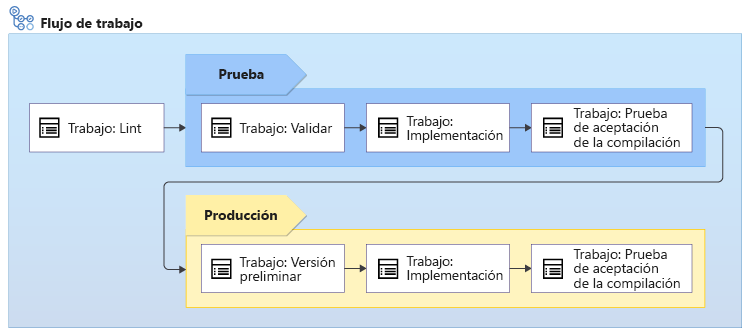
El flujo de trabajo ejecuta el linter de Bicep para comprobar que el código de Bicep es válido y sigue los procedimientos recomendados.
El linting se produce en el código de Bicep sin necesidad de conectarse a Azure, por lo que no importa el número de entornos en los que se va a implementar. Solo se ejecuta una vez.
El flujo de trabajo se implementa en el entorno de prueba y requiere lo siguiente:
- Ejecutar la validación preparatoria de Azure Resource Manager.
- Implementar el código de Bicep.
- Ejecutar algunas pruebas en el entorno de prueba.
Si se produce un error en alguna parte del flujo de trabajo, se detiene todo el flujo de trabajo para que se pueda investigar y resolver el problema. Pero si todo se realiza correctamente, el flujo de trabajo se sigue implementando en el entorno de producción:
- El flujo de trabajo incluye un paso de versión preliminar, que ejecuta la operación hipotética en el entorno de producción para indicar los cambios que se realizarán en los recursos de Azure de producción. La operación hipotética también valida la implementación, por lo que no es necesario ejecutar un paso de validación independiente para el entorno de producción.
- El flujo de trabajo se detiene para la validación manual.
- Si se recibe la aprobación, el flujo de trabajo ejecuta las pruebas de implementación y humo en el entorno de producción.
Algunas de estas tareas se repiten entre los entornos de prueba y producción, y otras solo se ejecutan para entornos específicos:
| Tarea | Entornos |
|---|---|
| Lint | Ninguno: el linting no funciona en un entorno |
| Validación | Solo prueba |
| Versión preliminar | Solo producción |
| Implementar | Ambos entornos |
| Prueba de aceptación de la compilación | Ambos entornos |
Cuando necesite repetir los pasos del flujo de trabajo, copiar y pegar las definiciones de paso no es un procedimiento recomendado. Es fácil realizar errores sutiles accidentalmente o que las cosas no se sincronicen cuando se duplica el código del flujo de trabajo. Además, en el futuro, si necesita realizar un cambio en los pasos, tiene que acordarse de aplicar el cambio en varios lugares. Un procedimiento recomendado es usar flujos de trabajo reutilizables.
Flujos de trabajo reutilizables
Acciones de GitHub permite crear secciones reutilizables de definiciones de flujo de trabajo mediante la creación de un archivo YAML de flujo de trabajo independiente que define pasos o trabajos. Puede crear archivos YAML para reutilizar partes de un flujo de trabajo varias veces dentro de un solo flujo de trabajo, o incluso en varios. El flujo de trabajo que se reutiliza es un flujo de trabajo llamado, mientras que el flujo de trabajo que lo incluye es un flujo de trabajo de llamador. Conceptualmente, puede pensar que son equivalentes a los módulos de Bicep.
Cuando se crea un flujo de trabajo reutilizable, se usa el desencadenador workflow_call para indicarle a Acciones de GitHub que otros flujos de trabajo pueden llamar al flujo de trabajo en cuestión. Este es un ejemplo básico de un flujo de trabajo reutilizable, guardado en un archivo denominado script.yml:
on:
workflow_call:
jobs:
say-hello:
runs-on: ubuntu-latest
steps:
- run: |
echo Hello world!
En el flujo de trabajo de llamador, para hacer referencia al flujo de trabajo llamado, se incluye la palabra clave uses: y se especifica la ruta de acceso al flujo de trabajo llamado dentro del repositorio actual:
on:
workflow_dispatch:
jobs:
job:
uses: ./.github/workflows/script.yml
También puede hacer referencia a un archivo de definición de flujo de trabajo de otro repositorio.
Entradas y secretos del flujo de trabajo llamado
Puede usar entradas y secretos para facilitar la reutilización de los flujos de trabajo llamados, ya que puede permitir que haya pequeñas diferencias en los flujos de trabajo cada vez que los use.
Al crear un flujo de trabajo llamado, puede indicar sus entradas y secretos en la parte superior del archivo:
on:
workflow_call:
inputs:
environmentType:
required: true
type: string
secrets:
AZURE_CLIENT_ID:
required: true
AZURE_TENANT_ID:
required: true
AZURE_SUBSCRIPTION_ID:
required: true
Puede definir tantas entradas y secretos como necesite. Aun así, igual que sucede con los parámetros de Bicep, intente no usar en exceso las entradas de flujo de trabajo. Debe facilitar que otra persona reutilice el flujo de trabajo sin tener que especificar demasiadas configuraciones.
Las entradas pueden tener varias propiedades, entre las que se incluyen las siguientes:
- El nombre de entrada, que se usa para hacer referencia a la entrada en las definiciones de flujo de trabajo.
- El tipo de entrada. Las entradas admiten valores de cadena, número y booleanos.
- Valor predeterminado de la entrada, que es opcional. Si no especifica un valor predeterminado, habrá que proporcionar un valor cuando se use el flujo de trabajo en un flujo de trabajo de llamador.
Los secretos tienen nombres, pero no tienen tipos ni valores predeterminados.
En el ejemplo, el flujo de trabajo define una entrada de cadena obligatoria denominada environmentType y tres secretos obligatorios denominados AZURE_CLIENT_ID, AZURE_TENANT_ID y AZURE_SUBSCRIPTION_ID.
En el flujo de trabajo, se usa una sintaxis especial para hacer referencia al valor del parámetro, como en este ejemplo:
jobs:
say-hello:
runs-on: ubuntu-latest
steps:
- run: |
echo Hello ${{ inputs.environmentType }}!
El valor de las entradas se pasa a un flujo de trabajo llamado mediante la palabra clave with. Debe definir los valores de cada entrada dentro de la sección with; no puede usar la palabra clave env para hacer referencia a las variables de entorno de un flujo de trabajo. Los valores de los secretos se pasan a un flujo de trabajo llamado mediante la palabra clave secrets.
on:
workflow_dispatch:
permissions:
id-token: write
contents: read
jobs:
job-test:
uses: ./.github/workflows/script.yml
with:
environmentType: Test
secrets:
AZURE_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID_TEST }}
AZURE_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
AZURE_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
job-production:
uses: ./.github/workflows/script.yml
with:
environmentType: Production
secrets:
AZURE_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID_PRODUCTION }}
AZURE_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
AZURE_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
Uso de identidades de carga de trabajo de los flujos de trabajo llamados
Al trabajar con flujos de trabajo llamados, a menudo se definen algunas de las acciones de implementación en varios archivos de definición de flujo de trabajo. Debe conceder permiso al flujo de trabajo del autor de la llamada, lo que garantiza que cada flujo de trabajo llamado pueda acceder a la identidad del flujo de trabajo y autenticarse en Azure:
on:
workflow_dispatch:
permissions:
id-token: write
contents: read
jobs:
job-test:
uses: ./.github/workflows/script.yml
with:
environmentType: Test
secrets:
AZURE_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID_TEST }}
AZURE_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
AZURE_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
job-production:
uses: ./.github/workflows/script.yml
with:
environmentType: Production
secrets:
AZURE_CLIENT_ID: ${{ secrets.AZURE_CLIENT_ID_PRODUCTION }}
AZURE_TENANT_ID: ${{ secrets.AZURE_TENANT_ID }}
AZURE_SUBSCRIPTION_ID: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
Condiciones
Puede usar condiciones de flujo de trabajo para especificar si se debe ejecutar un paso o un trabajo en función de una regla que especifique. Puede combinar entradas y condiciones de flujo de trabajo para personalizar el proceso de implementación en muchas situaciones diferentes.
Por ejemplo, imagine que define un flujo de trabajo que ejecuta pasos de script. Tiene previsto reutilizar la plantilla en cada uno de los entornos. Al implementar el entorno de producción, quiere ejecutar otro paso. A continuación se muestra cómo puede lograrlo mediante la condición if en el paso:
jobs:
say-hello:
runs-on: ubuntu-latest
steps:
- run: |
echo Hello ${{ inputs.environmentType }}!
- run: |
echo This step only runs for production deployments.
if: inputs.environmentType == 'Production'
La condición aquí se traduce como: si el valor del parámetro environmentType es igual a "Producción", ejecute el paso.
Aunque las condiciones agregan flexibilidad al flujo de trabajo, demasiadas de ellas pueden complicar el flujo de trabajo y dificultar la comprensión. Si tiene muchas condiciones en un flujo de trabajo llamado, puede considerar la posibilidad de volver a diseñarlas.
Además, use comentarios de YAML para explicar las condiciones que use y cualquier otro aspecto del flujo de trabajo que pueda necesitar más explicación. Los comentarios ayudan a que el flujo de trabajo sea más fácil de entender y trabajar con en el futuro. Hay algunos comentarios de YAML de ejemplo en los ejercicios de este módulo.