Escalar recursos de proceso en Azure Synapse Analytics.
Una de las características de administración clave que tiene a su disposición en Azure Synapse Analytics es la capacidad de escalar los recursos de proceso para los grupos de SQL o Spark a fin de satisfacer las demandas de procesamiento de los datos. En los grupos de SQL, la unidad de escalado es una abstracción de la eficacia del proceso que se conoce como unidad de almacenamiento de datos. Como el proceso está separado del almacenamiento, se puede escalar con independencia de los datos del sistema. Esto significa que puede escalar y reducir verticalmente la capacidad del proceso para satisfacer sus necesidades.
Puede escalar un grupo de SQL de Synapse mediante Azure Portal, Azure Synapse Studio o mediante programación con TSQL o PowerShell.
En Azure Portal, puede hacer clic en el icono Escalar.
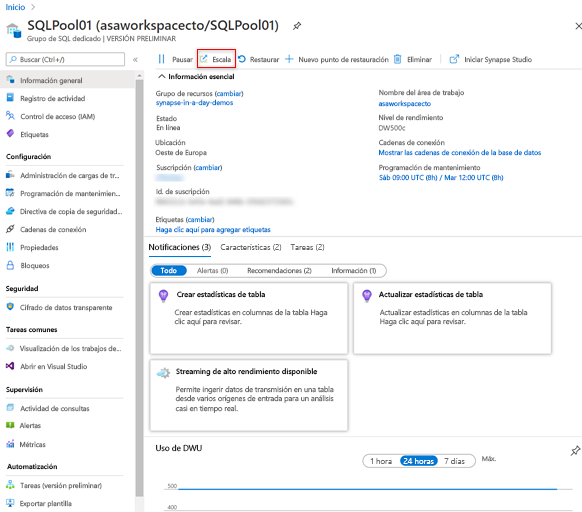
Y, a continuación, puede ajustar el control deslizante para escalar el grupo de SQL.
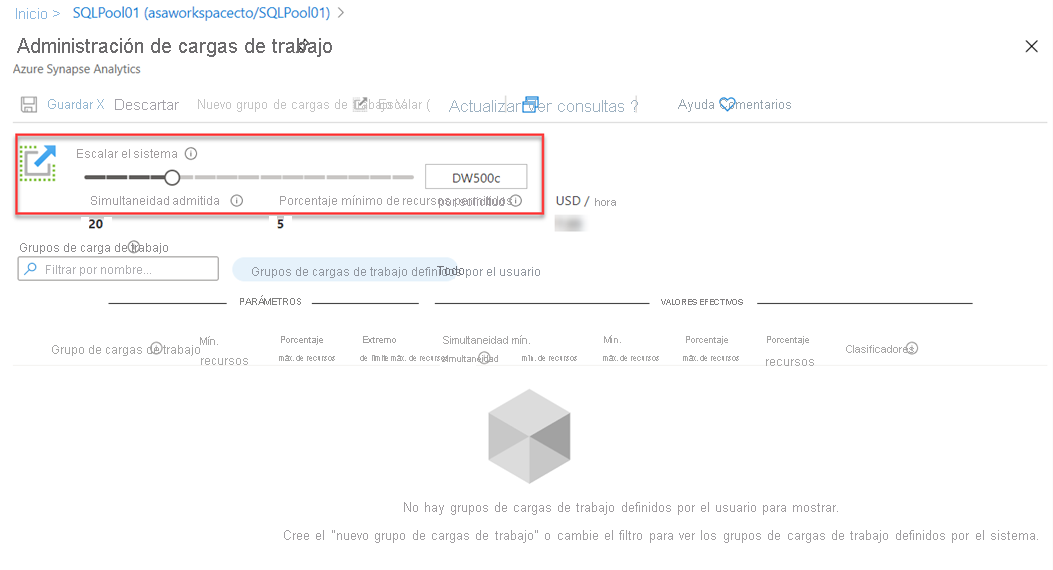
Otra opción para escalar está en Azure Synapse Studio. Haga clic en el icono Escalar:
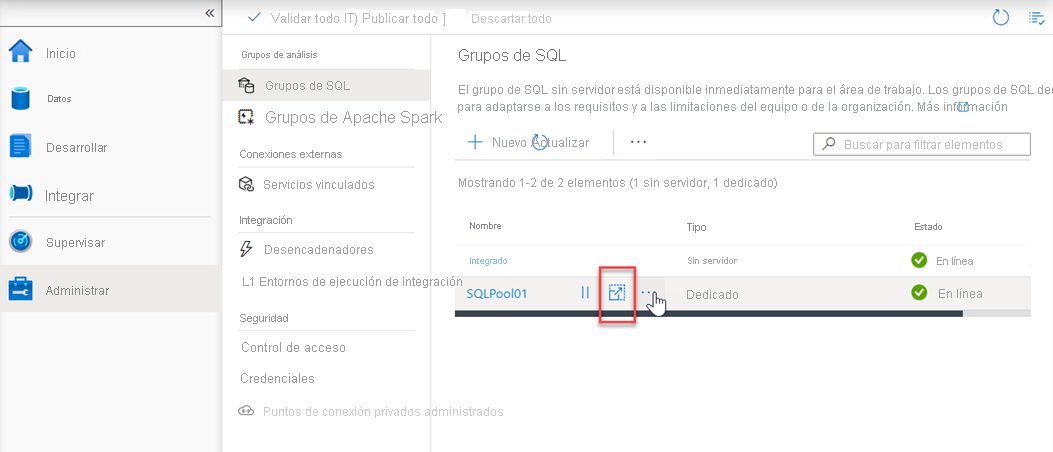
Y, a continuación, mueva el control deslizante como se indica a continuación:
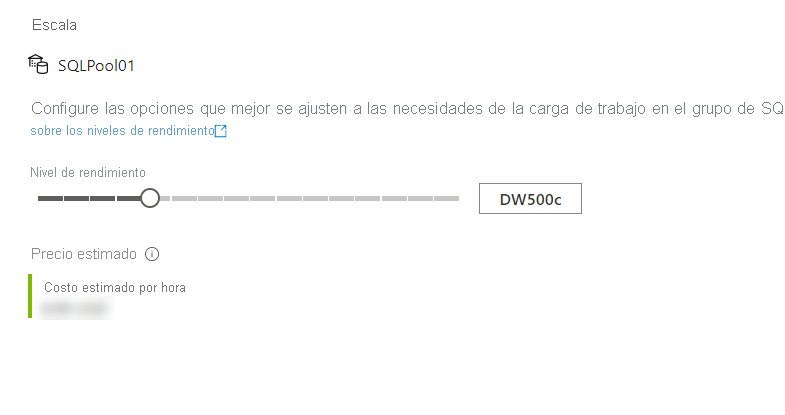
También puede realizar la modificación mediante Transact-SQL,
ALTER DATABASE mySampleDataWarehouse
MODIFY (SERVICE_OBJECTIVE = 'DW300c');
o mediante PowerShell.
Set-AzSqlDatabase -ResourceGroupName "resourcegroupname" -DatabaseName "mySampleDataWarehouse" -ServerName "sqlpoolservername" -RequestedServiceObjectiveName "DW300c"
Escalado de grupos de Apache Spark en Azure Synapse Analytics
Los grupos de Apache Spark para Azure Synapse Analytics usan una característica de escalabilidad automática que escala y reduce verticalmente de forma automática el número de nodos en una instancia de clúster. Durante la creación de un nuevo grupo de Spark, se puede establecer un número mínimo y máximo de nodos cuando se selecciona la escalabilidad automática. La escalabilidad automática luego supervisa los requisitos de recursos de la carga y escala o reduce verticalmente el número de nodos. Para habilitar la característica de escalabilidad automática, complete estos pasos como parte del proceso de creación de grupos normal:
- En la pestaña Datos básicos, marque la casilla Habilitar escalabilidad automática.
- Escriba los valores deseados para estas propiedades:
- Número mínimo de nodos.
- Número máximo de nodos.
El número inicial de nodos será el mínimo. Este valor define el tamaño inicial de la instancia durante su creación. El número mínimo de nodos no puede ser inferior a tres.
También puede modificarlo en Azure Portal, puede hacer clic en el icono de configuración de escalabilidad automática.
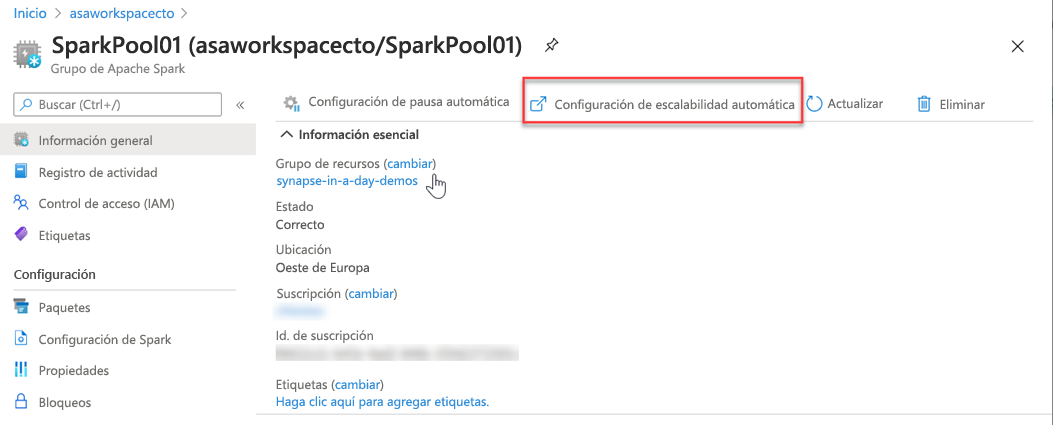
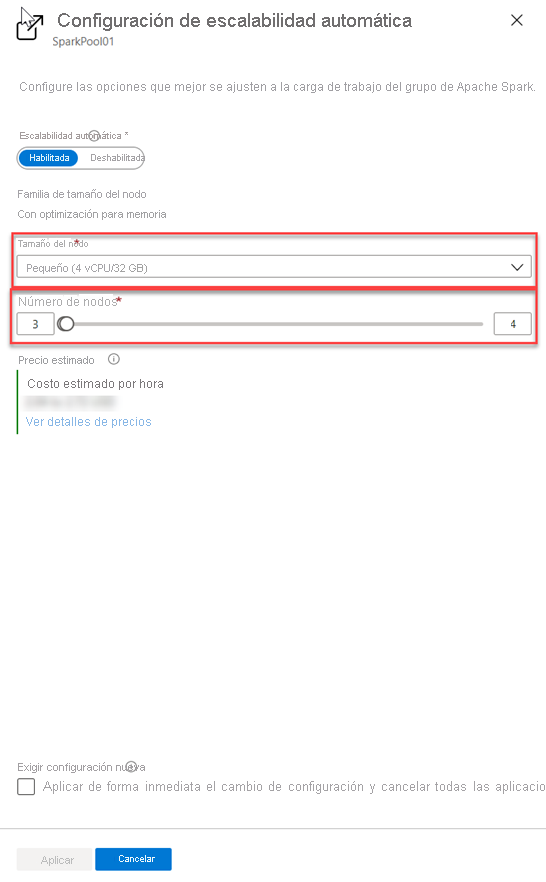
Elija el tamaño del nodo y el número de nodos.
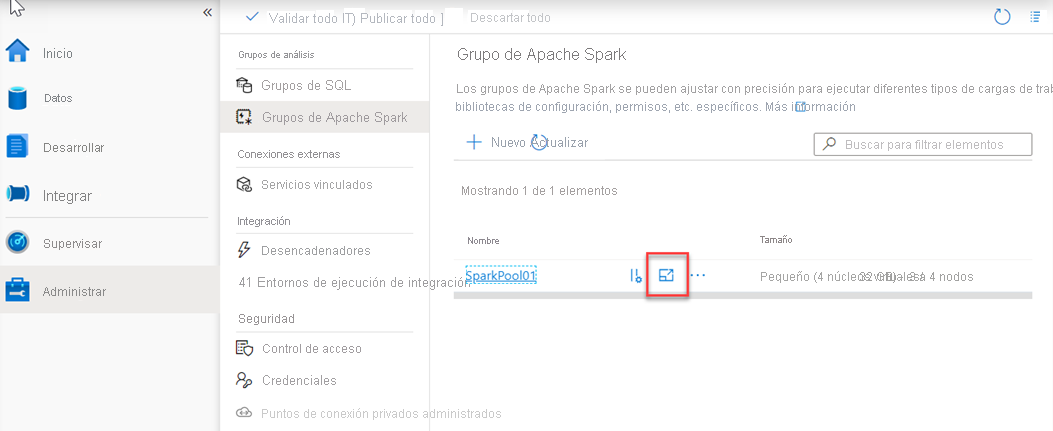
y para Azure Synapse Studio, como se indica a continuación
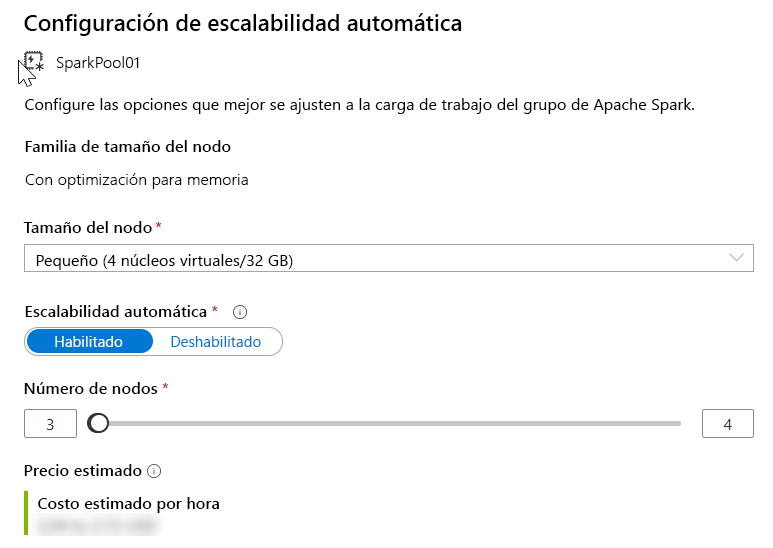
Y elija el tamaño del nodo y el número de nodos.
La escalabilidad automática supervisa continuamente la instancia de Spark y recopila las métricas siguientes:
| Métrica | Descripción |
|---|---|
| Total de CPU pendiente | El número total de núcleos necesarios para iniciar la ejecución de todos los nodos pendientes. |
| Total de memoria pendiente | La memoria total (en MB) necesaria para iniciar la ejecución de todos los nodos pendientes. |
| Total de CPU libre | La suma de todos los núcleos sin usar en los nodos activos. |
| Total de memoria libre | La suma de la memoria sin usar (en MB) en los nodos activos. |
| Memoria usada por nodo | Carga en un nodo. Un nodo donde se usan 10 GB de memoria se considera bajo más carga que un trabajo con 2 GB de memoria usada. |
En las siguientes condiciones, se escalará automáticamente la memoria o la CPU.
| Escalabilidad vertical | Reducción vertical |
|---|---|
| El total de CPU pendiente es mayor que el total de CPU libre durante más de 1 minuto. | El total de CPU pendiente es menor que el total de CPU libre durante más de 2 minutos. |
| El total de memoria pendiente es mayor que el total de memoria libre durante más de 1 minuto. | El total de memoria pendiente es menor que el total de memoria libre durante más de 2 minutos. |
La operación de escalado puede tardar entre 1 y 5 minutos. Durante una instancia en la que hay un proceso de reducción vertical, la escalabilidad automática pondrá los nodos en estado de retirada para que no se puedan iniciar nuevos ejecutores en ese nodo.
Los trabajos en ejecución se seguirán ejecutando y se completarán. Los trabajos pendientes esperarán ser programados como normales con menos nodos disponibles.