Configuración del almacenamiento y las bases de datos
A menudo, parte del proceso de implementación requiere que se conecte a bases de datos o servicios de almacenamiento. Esta conexión puede ser necesaria para aplicar un esquema de base de datos, agregar algunos datos de referencia a una tabla de base de datos o cargar algunos blobs. En esta unidad, obtendrá información sobre cómo se puede ampliar el flujo de trabajo para trabajar con datos y servicios de almacenamiento.
Configuración de las bases de datos desde un flujo de trabajo
Muchas bases de datos tienen esquemas, que representan la estructura de los datos contenidos en la base de datos. A menudo es una buena práctica aplicar un esquema a la base de datos desde el flujo de trabajo de implementación. Esta práctica permite garantizar que todo lo que necesita la solución se implementa conjuntamente. También garantiza que, si hay un problema cuando se aplica el esquema, el flujo de trabajo le mostrará un error, de modo que pueda corregir el problema y volver a implementarlo.
Al trabajar con Azure SQL, debe aplicar esquemas de la base de datos conectándolos al servidor de bases de datos y ejecutando comandos mediante scripts de SQL. Estos comandos son operaciones del plano de datos. El flujo de trabajo debe autenticarse en el servidor de bases de datos y, después, ejecutar los scripts. Acciones de GitHub proporciona la acción azure/sql-action que puede conectarse a un servidor de base de datos de Azure SQL y ejecutar comandos.
No es necesario configurar otros servicios de almacenamiento y datos mediante una API de plano de datos. Por ejemplo, cuando se trabaja con Azure Cosmos DB, los datos se almacenan en un contenedor. Puede configurar los contenedores mediante el plano de control, directamente desde el archivo de Bicep. Del mismo modo, también puede implementar y administrar la mayoría de los aspectos de contenedores de blobs de Azure Storage en Bicep. En el ejercicio siguiente, verá un ejemplo de cómo crear un contenedor de blobs a partir de Bicep.
Agregar datos
Hay muchas soluciones que, para funcionar, requieren que se agreguen datos de referencia a sus bases de datos o cuentas de almacenamiento. Los flujos de trabajo pueden ser un buen lugar para agregar estos datos. Esto significa que, una vez ejecutado el flujo de trabajo, el entorno está completamente configurado y listo para usarse.
También resulta útil tener datos de ejemplo en las bases de datos, especialmente en entornos que no son de producción. Los datos de ejemplo permiten a los evaluadores y a otras personas que usan esos entornos poder probar la solución inmediatamente. Estos datos pueden incluir productos de ejemplo o cosas como cuentas de usuario falsas. Por lo general, no quiere agregar estos datos al entorno de producción.
El enfoque que use para agregar datos depende del servicio que utilice. Por ejemplo:
- Para agregar datos a una base de datos de Azure SQL, debe ejecutar un script, de forma muy similar a configurar un esquema.
- Cuando necesite insertar datos en Azure Cosmos DB, debe acceder a su API del plano de datos, lo que podría requerir que escriba algún código de script personalizado.
- Para cargar blobs en un contenedor de blobs de Azure Storage, puede usar diversas herramientas de scripts de flujo de trabajo, como la aplicación de la línea de comandos AzCopy, Azure PowerShell o la CLI de Azure. Cada una de estas herramientas entiende cómo autenticarse en Azure Storage en su nombre y cómo conectarse a la API del plano de datos para cargar blobs.
Idempotencia
Una de las características de los flujos de trabajo de implementación y la infraestructura como código es que debería poder volver a implementar varias veces sin que se produzca ningún efecto secundario adverso. Por ejemplo, al volver a implementar un archivo de Bicep que ya ha implementado, Azure Resource Manager compara el archivo que envió con el estado existente de los recursos de Azure. Si no hay cambios, Resource Manager no hace nada. La capacidad de volver a ejecutar una operación repetidamente se denomina idempotencia. Un procedimiento recomendado consiste en asegurarse de que los scripts y otros pasos del flujo de trabajo son idempotentes.
La idempotencia es especialmente importante cuando se interactúa con los servicios de datos, ya que mantienen el estado. Imagine que va a insertar un usuario de ejemplo en una tabla de base de datos desde el flujo de trabajo. Si no tiene cuidado, cada vez que ejecute el flujo de trabajo, se creará un usuario de ejemplo. Probablemente este no es el resultado que quiere.
Al aplicar esquemas a una base de datos de Azure SQL, puede usar un paquete de datos, también denominado archivo DACPAC, para implementar el esquema. El flujo de trabajo compila un archivo DACPAC desde el código fuente y crea un artefacto de flujo de trabajo, al igual que con una aplicación. Después, el trabajo de implementación del flujo de trabajo publica el archivo DACPAC en la base de datos:
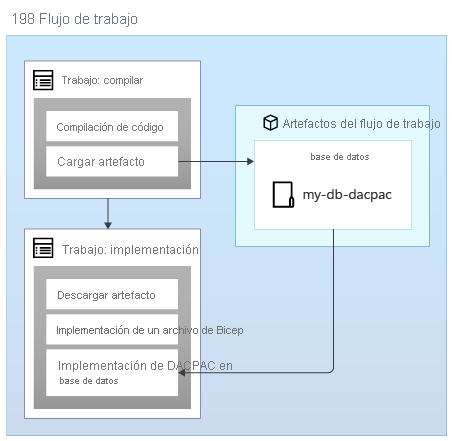
Cuando se implementa un archivo DACPAC, se comporta de forma idempotente comparando el estado de destino de la base de datos con el estado definido en el paquete. En muchas situaciones, esto significa que no es necesario escribir scripts que sigan el principio de idempotencia, ya que las herramientas lo administran automáticamente. Algunas de las herramientas de Azure Cosmos DB y Azure Storage también se comportan correctamente.
Pero cuando se crean datos de ejemplo en una base de datos de Azure SQL u otro servicio de almacenamiento que no funciona automáticamente de forma idempotente, es una buena práctica escribir el script para que cree los datos solo si aún no existen.
También es importante tener en cuenta si es posible que necesite revertir implementaciones, por ejemplo, al volver a ejecutar una versión anterior de un flujo de trabajo de implementación. La reversión de sus datos puede complicarse, así que considere cuidadosamente cómo funcionará su solución si necesita permitir reversiones.
Seguridad de las redes
A veces, puede aplicar restricciones de red a algunos de los recursos de Azure. Estas restricciones pueden aplicar reglas sobre las solicitudes realizadas al plano de datos de un recurso como, por ejemplo:
- Este servidor de bases de datos solo es accesible desde una lista especificada de direcciones IP.
- Esta cuenta de almacenamiento solo es accesible desde los recursos implementados en una red virtual específica.
Las restricciones de red son comunes con las bases de datos, ya que puede parecer que no es necesario que haya nada en Internet que se conecte a un servidor de bases de datos.
Pero las restricciones de red además pueden dificultar que los flujos de trabajo de implementación funcionen también con los planos de datos de los recursos. Cuando se usa un ejecutor hospedado en GitHub, su dirección IP no se puede conocer fácilmente de antemano y podría asignarse desde un grupo grande de direcciones IP. Además, los ejecutores hospedados en GitHub no se pueden conectar a sus propias redes virtuales.
Algunas de las acciones que le permiten realizar operaciones del plano de datos pueden resolver estos problemas. Por ejemplo, la acción azure/sql-action:
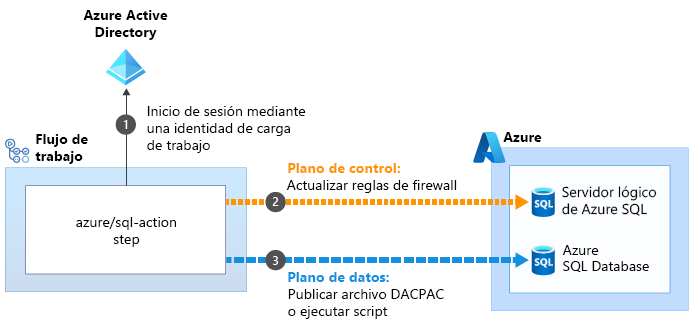
Cuando se usa la acción azure/sql-action para trabajar con un servidor lógico o una base de datos de Azure SQL, usa la identidad de carga de trabajo  para conectarse al plano de control del servidor lógico de Azure SQL. Actualiza el firewall para permitir que el ejecutor acceda al servidor desde su dirección IP
para conectarse al plano de control del servidor lógico de Azure SQL. Actualiza el firewall para permitir que el ejecutor acceda al servidor desde su dirección IP . Luego, puede enviar correctamente el archivo DACPAC o el script para su ejecución
. Luego, puede enviar correctamente el archivo DACPAC o el script para su ejecución . Después, la acción quita automáticamente la regla de firewall cuando haya terminado.
. Después, la acción quita automáticamente la regla de firewall cuando haya terminado.
En otras situaciones, no es posible crear excepciones como esta. En estas circunstancias, plantéese usar un ejecutor autohospedado, que se ejecuta en una máquina virtual u otro recurso de proceso que controle. Después, puede configurar este ejecutor tal como lo necesite. Puede usar una dirección IP conocida o conectarse a su propia red virtual. En este módulo no se analizan los ejecutores autohospedados, pero se proporcionan vínculos para obtener más información en la página Resumen al final del módulo.
El flujo de trabajo de implementación
En el ejercicio siguiente, actualizará el flujo de trabajo de implementación a fin de agregar nuevos trabajos para compilar los componentes de base de datos del sitio web, implementar la base de datos y agregar datos de inicialización:
