Evaluación del panel de inteligencia artificial responsable
Cuando se genera el panel de Inteligencia artificial responsable, puede explorar su contenido en Azure Machine Learning Studio para evaluar el modelo.
Al abrir el panel de Inteligencia Artificial Responsable, Studio intenta conectarlo automáticamente a una instancia de cálculo. La instancia de computación proporciona la capacidad de cálculo necesaria para la exploración interactiva dentro del tablero.
La salida de cada componente que agregó a la canalización se refleja en el panel. En función de los componentes seleccionados, puede encontrar las siguientes conclusiones en el panel de inteligencia artificial responsable:
- Análisis de errores
- Explicaciones
- Contrahechos
- Análisis causal
Vamos a explorar lo que podemos revisar para cada una de estas conclusiones.
Exploración del análisis de errores
Se espera que un modelo realice predicciones falsas o errores. Con la característica de análisis de errores en el panel De inteligencia artificial responsable, puede revisar y comprender cómo se distribuyen los errores en el conjunto de datos. Por ejemplo, ¿hay subgrupos específicos o cohortes en el conjunto de datos para el que el modelo realiza predicciones más falsas?
Al incluir el análisis de errores, hay dos tipos de objetos visuales que puede explorar en el panel de Inteligencia artificial responsable:
- mapa de árbol de errores: permite explorar qué combinación de subgrupos da como resultado el modelo que realiza predicciones más falsas.
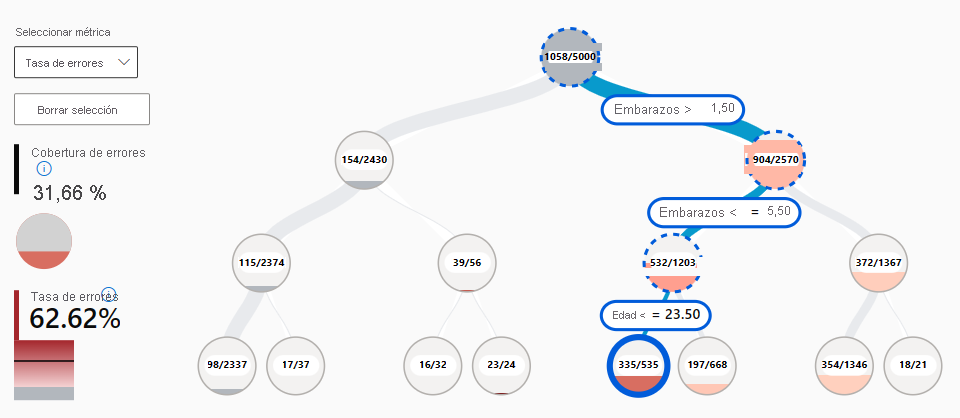
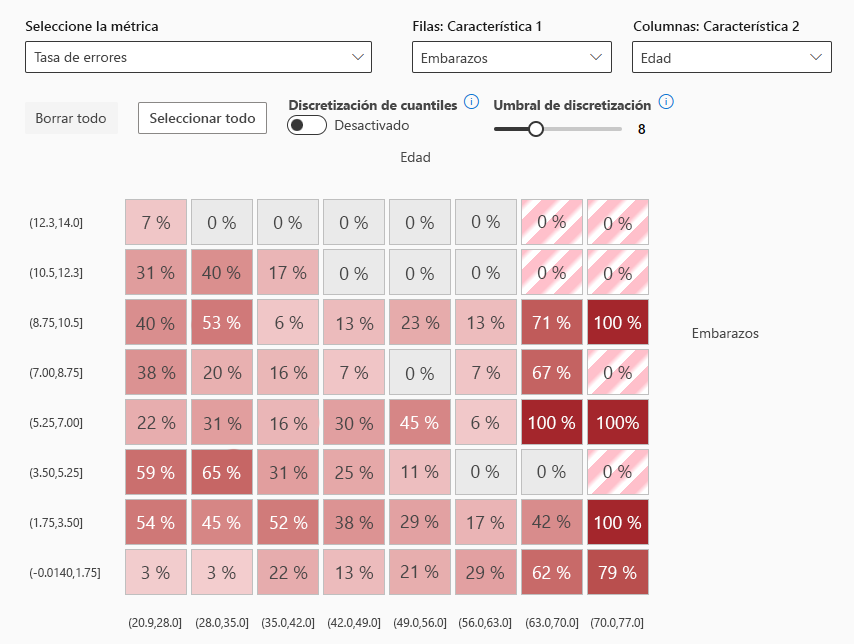
- mapa térmico de errores: presenta una visión general de la cuadrícula de los errores de un modelo a través de la escala de una o dos características.
Exploración de explicaciones
Siempre que use un modelo para la toma de decisiones, querrá comprender cómo un modelo alcanza una predicción determinada. Siempre que hayas entrenado un modelo demasiado complejo de entender, puedes ejecutar explicadores de modelos para calcular la importancia de las características . En otras palabras, quiere comprender cómo cada una de las características de entrada influye en la predicción del modelo.
Hay diversas técnicas estadísticas puedes usar como explicadores de modelos. Normalmente, el imita explicador entrena un modelo sencillo interpretable en los mismos datos y tareas. Como resultado, puede explorar dos tipos de importancia de características:
- importancia de las características agregadas: muestra cómo cada característica de los datos de prueba influye en las predicciones del modelo general.
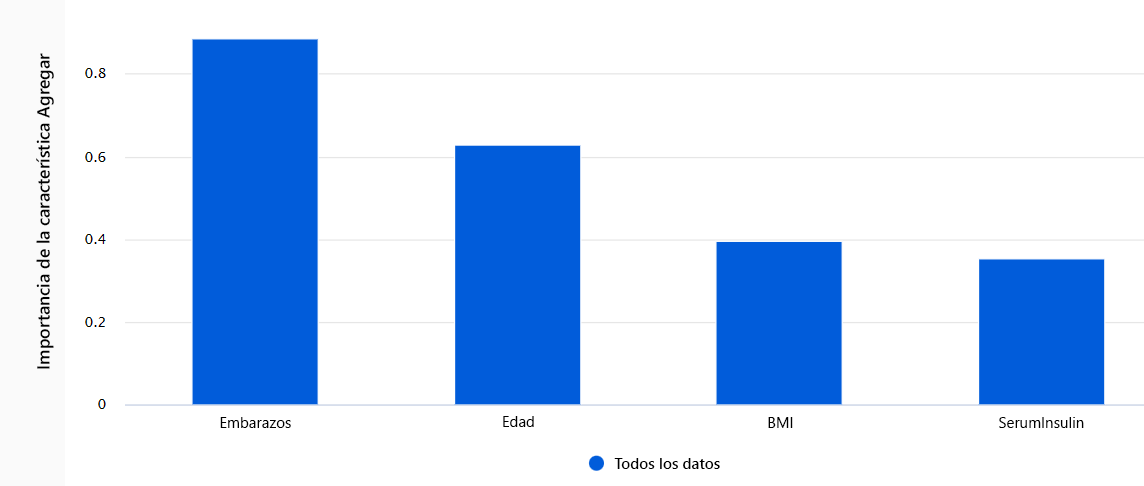
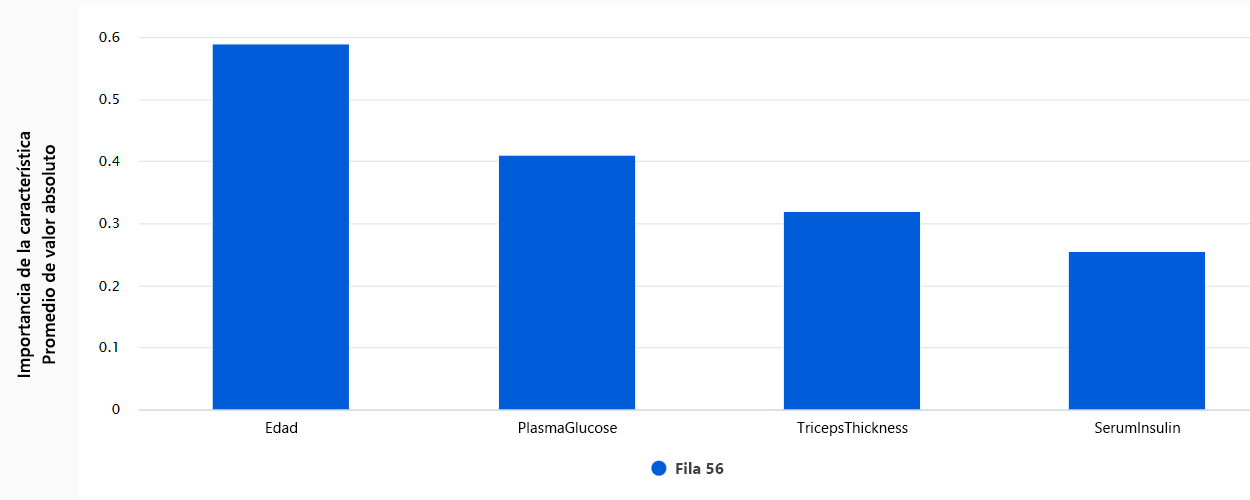
- Importancia de características individuales: Muestra cómo cada característica afecta a una predicción individual .
Explora contrafactuales
Las explicaciones pueden proporcionar información sobre la importancia relativa de las características en las predicciones del modelo. A veces, es posible que quiera seguir un paso más allá y comprender si las predicciones del modelo cambiarían si la entrada fuera diferente. Para explorar cómo cambiaría el resultado del modelo a partir de un cambio en la entrada, puede usar contrafactuales .
Puede elegir explorar contrafactuales ejemplos de what-if seleccionando un punto de datos y la predicción del modelo deseado para ese punto. Al crear un análisis contrafactual, el cuadro de mando abre un panel para ayudarle a comprender qué entrada daría como resultado la predicción deseada.
Exploración del análisis causal
Las explicaciones y los contrafactuales le ayudan a comprender las predicciones del modelo y los efectos de las características en las predicciones. Aunque la interpretación del modelo ya puede ser un objetivo por sí mismo, es posible que también necesite más información para ayudarle a mejorar la toma de decisiones.
análisis causal usa técnicas estadísticas para calcular el efecto medio de una característica en una predicción deseada. Analiza cómo ciertas intervenciones o tratamientos pueden dar lugar a un mejor resultado, en una población o para un individuo específico.
Hay tres pestañas disponibles en el panel de inteligencia artificial responsable al incluir el análisis causal:
- efectos causales agregados: muestra los efectos causales promedio para las características de tratamiento predefinidas (las características que desea cambiar para optimizar las predicciones del modelo).
- efectos causales individuales: muestra puntos de datos individuales y permite cambiar las características de tratamiento para explorar su influencia en la predicción.
- Política de tratamiento: muestra qué partes de tus datos se benefician más de un tratamiento.