Introducción
El aprendizaje automático está transformando el funcionamiento de las empresas al permitir la toma de decisiones basada en datos y la automatización. Sin embargo, desarrollar un modelo de aprendizaje automático es solo el principio. El verdadero reto consiste en implementar estos modelos en entornos de producción en los que puedan ofrecer información y predicciones en tiempo real.
Azure Databricks es una plataforma versátil que combina ingeniería de datos y ciencia de datos. Proporciona una plataforma de análisis unificada que simplifica el proceso de crear, entrenar e implementar modelos de aprendizaje automático a gran escala. Gracias a su entorno colaborativo, los científicos de datos y los ingenieros pueden trabajar juntos para crear soluciones eficaces de aprendizaje automático.
Para utilizar plenamente las capacidades de Azure Databricks, es esencial comprender el flujo de trabajo completo del aprendizaje automático.
Explorar flujo de trabajo de aprendizaje automático
El flujo de trabajo del aprendizaje automático es un proceso integral que abarca varias tareas críticas, cada una de las cuales desempeña un papel vital a la hora de desarrollar e implementar modelos de aprendizaje automático eficaces. El flujo de trabajo de aprendizaje automático incluye las siguientes tareas:
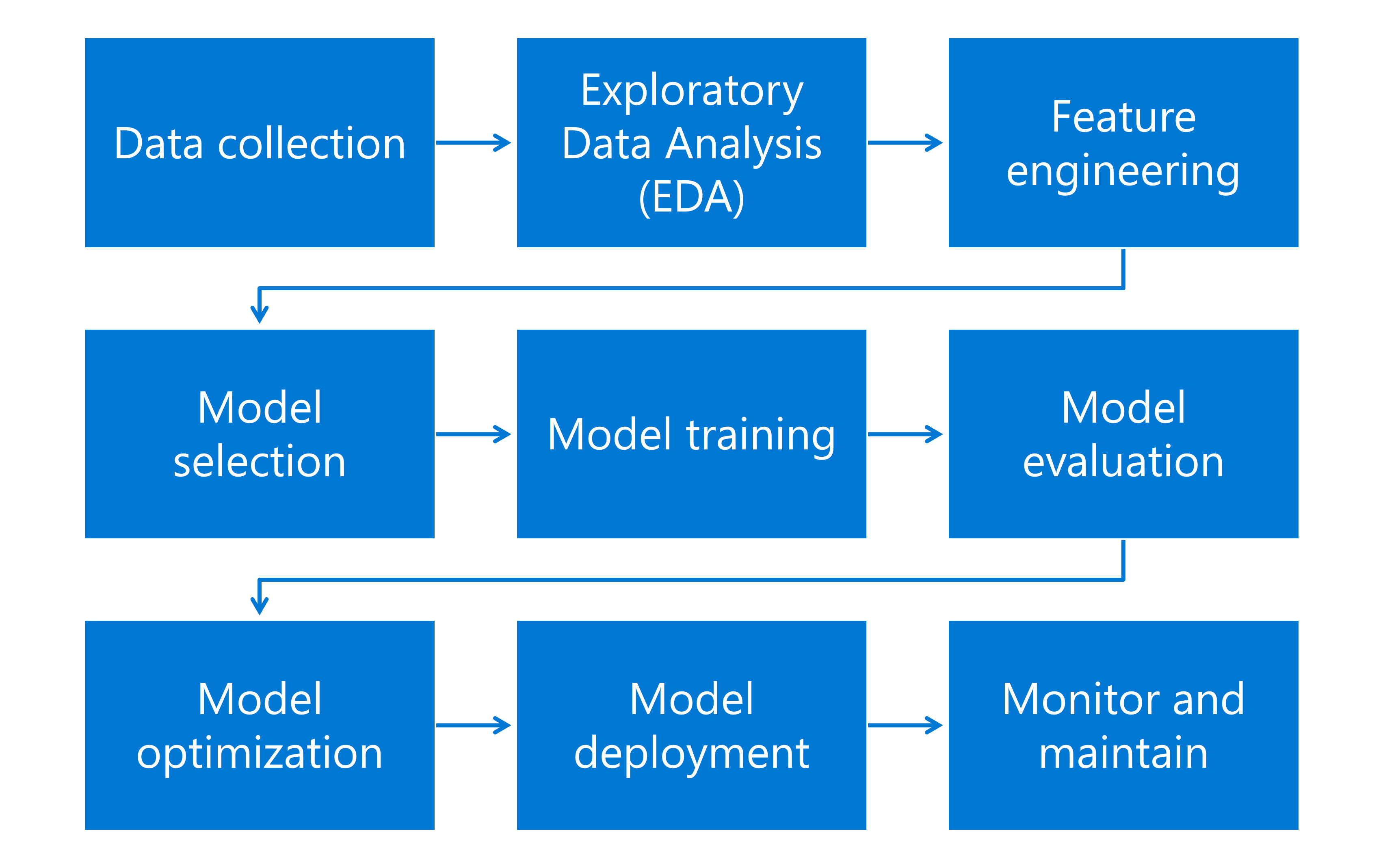
- Recopilación de datos: Los datos pueden ser cualquier cosa, desde números e imágenes hasta texto, dependiendo de lo que la máquina necesite aprender.
- EDA (Análisis exploratorio de los datos): Analizar los datos para resumir sus principales características y descubrir patrones.
- Diseño de características: Crear nuevas características o modificar las existentes para mejorar el rendimiento del modelo.
- Selección de modelos: El modelo es una fórmula matemática o un algoritmo que realiza predicciones mediante la búsqueda de patrones en los datos.
- Entrenamiento de modelo: El algoritmo de aprendizaje automático usa datos para aprender los patrones que conectan la entrada (características) a la salida (destino). El modelo ajusta sus parámetros para minimizar la diferencia entre sus predicciones y los resultados reales en los datos de entrenamiento.
- Evaluación de modelo: El rendimiento del modelo se evalúa mediante un nuevo conjunto de datos denominado conjunto de pruebas. Las métricas como la exactitud, la precisión, la recuperación y el área bajo la curva ROC se usan para evaluar diferentes tipos de modelos.
- Optimización de modelo: Los parámetros y el algoritmo del modelo están ajustados para mejorar su precisión y eficiencia.
- Implementación de modelo: El modelo se implementa en un entorno de producción donde realiza predicciones por lotes o en tiempo real.
- Supervisión y mantenimiento: La supervisión continua es fundamental para garantizar que el modelo siga siendo eficaz a medida que se produzcan nuevos cambios en la distribución de datos subyacente.
Para navegar por cada fase del flujo de trabajo de aprendizaje automático e incorporar modelos a la producción, es importante usar las herramientas y tecnologías adecuadas. Azure Databricks, junto con otros servicios de Azure, ofrece un conjunto de herramientas que admiten cada paso de este proceso. Desde la recopilación de datos y la ingeniería de características hasta la implementación y la supervisión del modelo, Azure proporciona herramientas que permiten una integración sin problemas y flujos de trabajo eficaces.
Vamos a explorar las herramientas que le ayudan a incorporar los flujos de trabajo de aprendizaje automático a la producción.