Desequilibrios de datos
Cuando nuestras etiquetas de datos tienen más de una categoría que otra, se dice que tenemos un desequilibrio de datos. Por ejemplo, recuerde que, en nuestro escenario, estamos intentando identificar los objetos que han encontrado los sensores de drones. Nuestros datos están desequilibrados porque hay un número enormemente diferente de excursionistas, animales, árboles y rocas en nuestros datos de entrenamiento. Esto se puede ver mediante la tabulación de estos datos:
| Etiqueta | Excursionista | Animal | Árbol | Piedra |
|---|---|---|---|---|
| Count | 400 | 200 | 800 | 800 |
O bien, se puede representar de esta manera:
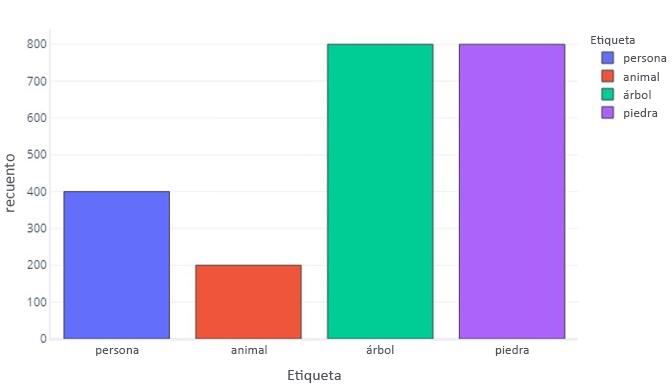
Observe cómo la mayoría de los datos son árboles o rocas. Un conjunto de datos equilibrado no tiene este problema.
Por ejemplo, si intentáramos predecir si un objeto es un excursionista, un animal, un árbol o una roca, lo ideal sería tener un número igual de todas las categorías, de la siguiente manera:
| Etiqueta | Excursionista | Animal | Árbol | Piedra |
|---|---|---|---|---|
| Count | 550 | 550 | 550 | 550 |
Si simplemente intentáramos predecir si un objeto era un excursionista, lo ideal sería tener un número igual de objetos de excursionista y objetos de no excursionista:
| Etiqueta | Excursionista | No excursionista |
|---|---|---|
| Count | 1100 | 1100 |
¿Por qué son importantes los desequilibrios de datos?
Los desequilibrios de datos son importantes porque los modelos pueden aprender a imitar estos desequilibrios cuando no es deseable. Por ejemplo, imagine que entrenamos un modelo de regresión logística para identificar objetos como excursionista o no excursionista. Si en los datos de entrenamiento dominan en gran medida las etiquetas de "excursionista", el entrenamiento sesgará el modelo para devolver casi siempre estas etiquetas. Sin embargo, en el mundo real, es posible que descubramos que la mayoría de las cosas que encuentran los drones son árboles. Es probable que el modelo sesgado etiquete muchos de estos árboles como excursionistas.
Este fenómeno tiene lugar porque las funciones de costo, de forma predeterminada, determinan si se ha dado la respuesta correcta. Esto significa que, en un conjunto de datos sesgado, la manera más sencilla que tiene un modelo de alcanzar un rendimiento óptimo puede ser omitir prácticamente las características proporcionadas y siempre, o casi siempre, devolver la misma respuesta. Esta situación puede tener consecuencias negativas. Por ejemplo, imagine que nuestro modelo de excursionista/no excursionista se entrena con datos donde solo 1 de cada 1000 muestras contienen un excursionista. Un modelo que ha aprendido a devolver "no excursionista" cada vez tiene una precisión del 99,9 %. Esta estadística parece excelente, pero el modelo es inútil porque nunca nos dirá si alguien está en la montaña, y no sabremos rescatarlo si se produce una avalancha.
Sesgo en una matriz de confusión
Las matrices de confusión son la clave para identificar los desequilibrios de datos o el sesgo del modelo. En un escenario ideal, los datos de prueba tienen un número aproximadamente igual de etiquetas y las predicciones realizadas por el modelo también se reparten aproximadamente entre las etiquetas. En 1000 muestras, un modelo no sesgado, pero que a menudo obtiene respuestas incorrectas, podría tener un aspecto parecido al siguiente:
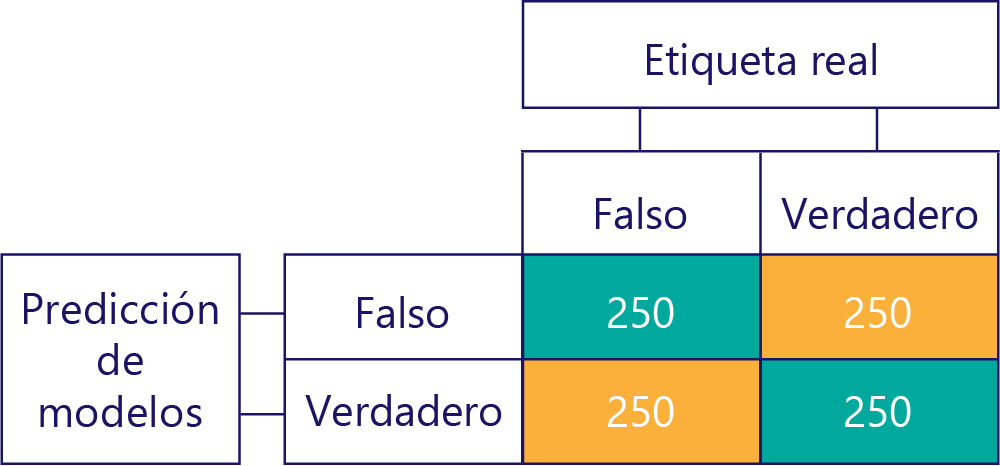
Podemos indicar que los datos de entrada no están sesgados, porque las sumas de las filas son las mismas (500 cada una), lo que indica que la mitad de las etiquetas son "true" y la mitad son "false". Del mismo modo, podemos ver que el modelo está dando respuestas no sesgadas porque devuelve "true" la mitad del tiempo y "false" la otra mitad.
Por el contrario, los datos sesgados contienen principalmente un tipo de etiqueta, como:
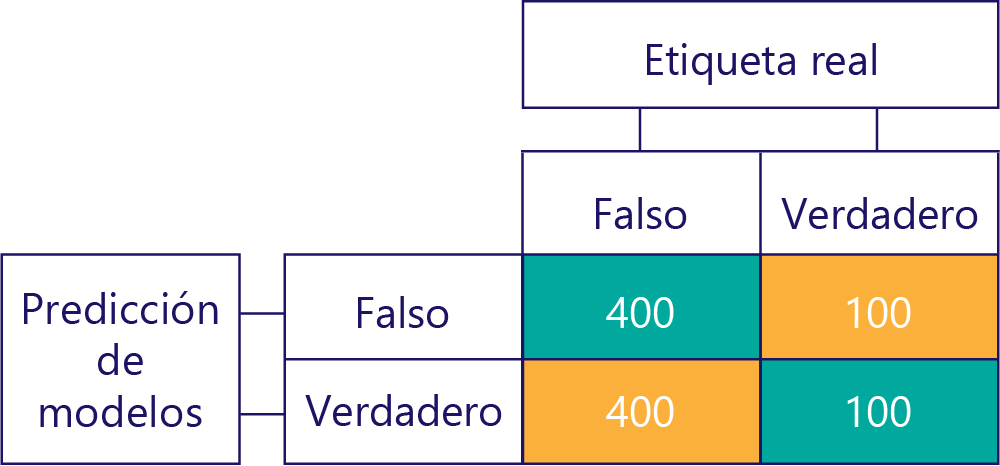
De forma similar, un modelo sesgado genera principalmente un tipo de etiqueta, como la siguiente:
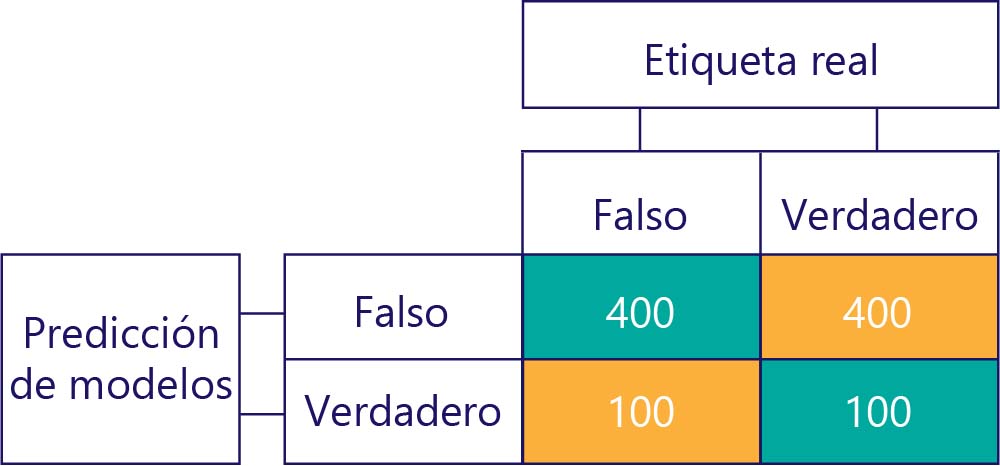
El sesgo del modelo no es la precisión
Recuerde que el sesgo no es la precisión. Por ejemplo, algunos de los ejemplos anteriores están sesgados y otros no, pero todos muestran un modelo que obtiene la respuesta correcta el 50 % de las veces. Como ejemplo más extremo, la siguiente matriz muestra un modelo no sesgado que es inexacto:
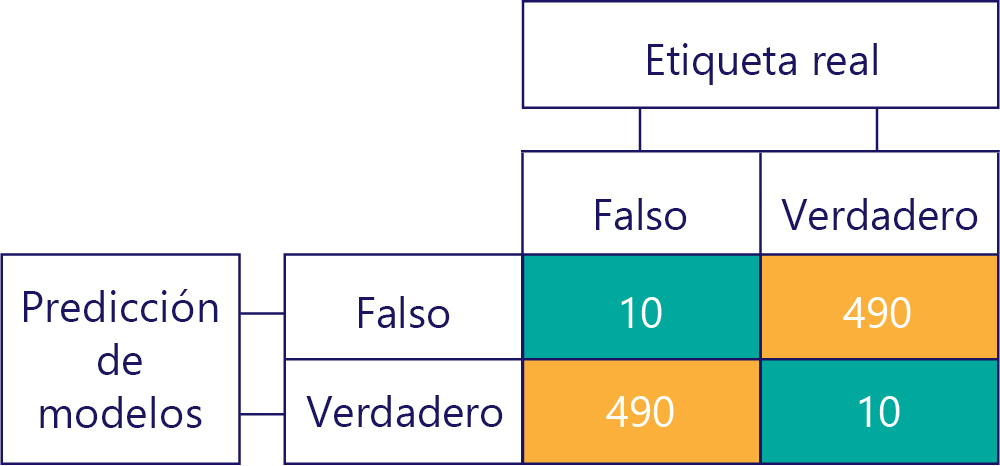
Observe cómo el número de filas y columnas se agrega a 500, lo que indica que ambos datos están equilibrados y que el modelo no está sesgado. Sin embargo, este modelo está obteniendo casi todas las respuestas incorrectas.
Por supuesto, nuestro objetivo es que los modelos sean precisos y no sesgados, por ejemplo:
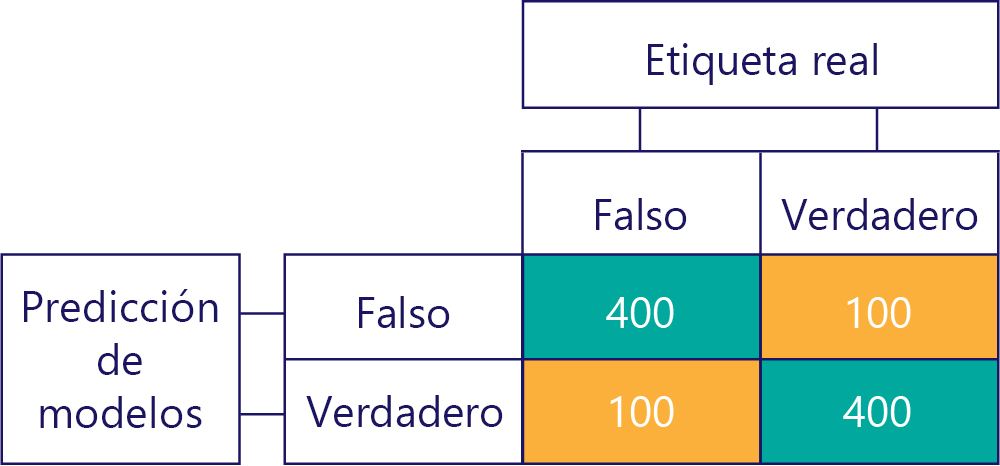
... pero debemos asegurarnos de que nuestros modelos precisos no estén sesgados, simplemente porque los datos son:
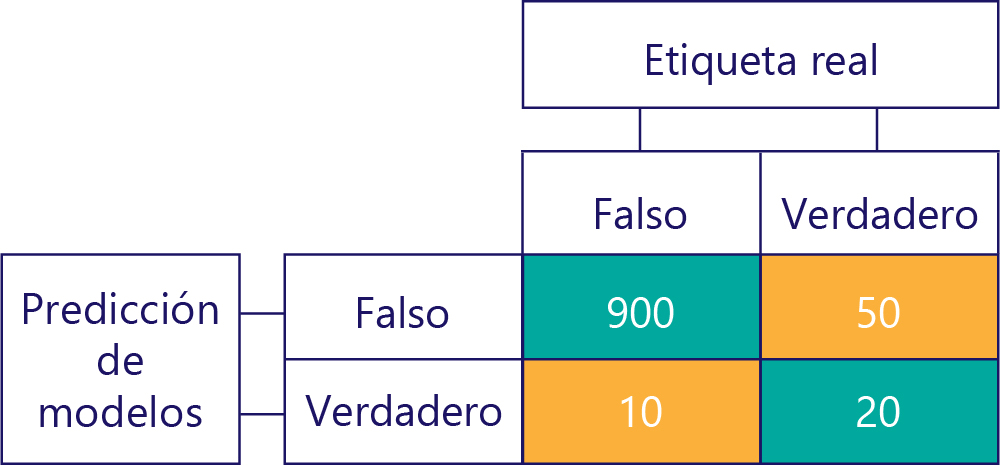
En este ejemplo, observe cómo las etiquetas reales son principalmente "false" (columna izquierda, que muestra un desequilibrio de datos) y que el modelo también devuelve con frecuencia "false" (fila superior, que muestra el sesgo del modelo). Este modelo no es bueno para dar correctamente respuestas "true".
Evitar las consecuencias de los datos desequilibrados
Algunas de las formas más sencillas de evitar las consecuencias de los datos desequilibrados son:
- Realizar una mejor selección de datos.
- "Nuevo muestreo" de los datos para que contengan duplicados de la clase de etiqueta minoritaria.
- Realizar cambios en la función de costo para que dé prioridad a las etiquetas menos comunes. Por ejemplo, si se da la respuesta incorrecta a Árbol, la función de costo podría devolver 1 mientras que, si se da la respuesta incorrecta a Excursionista, podría devolver 10.
Exploraremos estos métodos en el ejercicio siguiente.