Creación de modelos de IA personalizados con Azure Machine Learning
La disponibilidad de modelos sofisticados de inteligencia artificial puede ayudar a las organizaciones a reducir significativamente la cantidad intimidante de recursos que puede requerir un proyecto de ciencia de datos. Veamos cómo las organizaciones pueden abordar desafíos y operaciones de aprendizaje automático con Azure Machine Learning.
Desafíos del aprendizaje automático y necesidades de operaciones de aprendizaje automático
El mantenimiento de soluciones de inteligencia artificial normalmente requiere la administración del ciclo de vida del aprendizaje automático para documentar y administrar datos, código, entornos de modelos y los propios modelos de aprendizaje automático. Necesita establecer procesos para desarrollar, crear paquetes e implementar modelos, así como para supervisar su rendimiento y volver a entrenarlos ocasionalmente. Y la mayoría de las organizaciones administran varios modelos en producción a la vez, lo que aporta mayor complejidad.
Para hacer frente de manera eficaz a esta complejidad, se requieren algunos procedimientos recomendados. Están centrados en la colaboración entre equipos, la automatización y la estandarización de procesos y garantizan que los modelos se puedan auditar, explicar y reutilizar fácilmente. Para ello, los equipos de ciencia de datos se basan en el enfoque de operaciones de aprendizaje automático. Esta metodología está inspirada en DevOps (desarrollo y operaciones), el estándar del sector para administrar las operaciones de un ciclo de desarrollo de aplicaciones, ya que las dificultades de los desarrolladores y científicos de datos son similares.
Azure Machine Learning
Los científicos de datos pueden administrar y ejecutar DevOps de aprendizaje automático desde Azure Machine Learning, una plataforma de Microsoft para facilitar el aprendizaje automático administración del ciclo de vida y las operaciones. Estas herramientas ayudan a los equipos a colaborar en un entorno compartido, auditable y seguro donde se pueden optimizar numerosos procesos mediante la automatización.
Administración del ciclo de vida del aprendizaje automático
Azure Machine Learning admite la administración del ciclo de vida de aprendizaje automático de un extremo a otro de modelos previamente entrenados y personalizados. El ciclo de vida típico incluye los pasos siguientes: preparación de datos, entrenamiento de modelos, empaquetado de modelos, validación de modelos, implementación de modelos, supervisión de modelos y reentrenamiento.
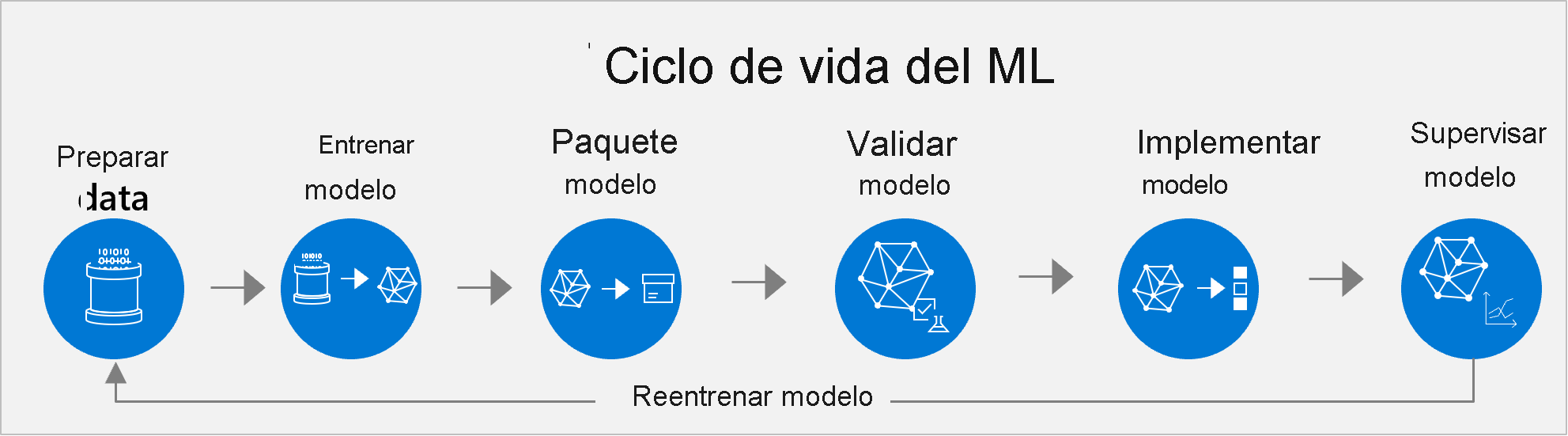
El enfoque clásico abarca todos los pasos habituales de un proyecto de ciencia de datos.
- Preparación del conjunto de datos. La inteligencia artificial comienza con los datos. En primer lugar, los científicos de datos deben preparar los datos con los que entrenar el modelo. La preparación de datos suele ser el mayor compromiso en el ciclo de vida. Esta tarea implica buscar o crear su propio conjunto de datos y limpiarlo para que sea fácil de leer por las máquinas. Quiere asegurarse de que los datos son un ejemplo representativo, que las variables son pertinentes para su objetivo, etc.
- Entrenamiento y prueba. Después, los científicos de datos aplican algoritmos a los datos para entrenar un modelo de aprendizaje automático. Luego se prueba con nuevos datos para ver la precisión de las predicciones.
- Empaquetado. Un modelo no se puede colocar directamente en una aplicación. Debe incluirse en contenedores, por lo que puede ejecutarse con todas las herramientas y marcos de trabajo en los que se basa.
- Validación. aquí es donde el equipo evalúa cuál es el rendimiento del modelo con respecto a sus objetivos empresariales. Las pruebas pueden devolver métricas suficientes, pero es posible que el modelo no funcione según lo previsto cuando se usa en un escenario empresarial real.
- Repetición de los pasos del 1 al 4. puede que tenga que dedicar cientos de horas de entrenamiento hasta encontrar un modelo que resulte satisfactorio. El equipo de desarrollo puede entrenar muchas versiones del modelo ajustando los datos de entrenamiento, optimizando los hiperparámetros del algoritmo o probando algoritmos diferentes. En una situación ideal, el modelo mejora con cada ronda de ajuste. En última instancia, el equipo de desarrollo es el encargado de decidir qué versión del modelo se adapta mejor al caso de uso de la empresa.
- Deploy. Por último, implementan el modelo. Entre las opciones de implementación se incluyen: en la nube, en un servidor local y en dispositivos como cámaras, puertas de enlace de IoT o maquinaria.
- Supervisión y reentrenamiento. incluso si un modelo funciona bien al principio, debe supervisarse continuamente y volver a entrenarse para que siga siendo relevante y preciso.
Nota:
Integrar modelos entrenados previamente y adaptarlos a sus necesidades empresariales requiere un flujo de trabajo diferente que integre modelos personalizados. Con Azure Machine Learning, puede usar modelos entrenados previamente o crear sus propios modelos. Elegir un enfoque sobre otro depende del escenario. Trabajar con modelos previamente entrenados tiene la ventaja de requerir menos recursos y ofrecer resultados más rápido. Sin embargo, los modelos precompilados están entrenados para resolver una amplia gama de casos de uso, por lo que pueden tener dificultades para satisfacer necesidades muy específicas. En estos casos, un modelo personalizado completo puede ser una mejor idea. Una combinación flexible de ambos enfoques suele ser preferible y ayuda al escalado. Los equipos de inteligencia artificial pueden ahorrar recursos mediante modelos entrenados previamente para los casos de uso más fáciles, al tiempo que invierten estos recursos en la creación de modelos de inteligencia artificial personalizados para los escenarios más difíciles. Las iteraciones adicionales pueden mejorar los modelos precompilados si se vuelven a entrenar.
Operaciones de aprendizaje automático
Las operaciones de aprendizaje automático (MLOps) aplican la metodología de DevOps (desarrollo y operaciones) para administrar el ciclo de vida de aprendizaje automático de forma más eficaz. Permite una colaboración más ágil y productiva en los equipos de inteligencia artificial entre todas las partes interesadas. Estas colaboraciones implican a científicos de datos, ingenieros de inteligencia artificial, desarrolladores de aplicaciones y otros equipos de TI.
Los procesos y las herramientas de MLOps ofrecen una manera sencilla de colaborar entre equipos y lograr mayor visibilidad al poder compartir y auditar documentación. Las tecnologías de MLOps permiten a los usuarios guardar y realizar un seguimiento de los cambios en todos los recursos, como datos, código, modelos y otras herramientas. Estas tecnologías también mejoran la eficiencia y aceleran el ciclo de vida mediante automatización, flujos de trabajo repetibles y recursos reutilizables. Todas estas prácticas hacen que los proyectos de inteligencia artificial sean más ágiles y eficientes.
Azure Machine Learning admite los siguientes procedimientos de MLOps:
Reproducibilidad del modelo: significa que los distintos miembros del equipo pueden ejecutar modelos en el mismo conjunto de datos y obtener resultados similares. La reproducibilidad es fundamental para hacer que los resultados de los modelos en producción sean confiables. Azure Machine Learning admite la reproducibilidad del modelo con recursos administrados de forma centralizada, como entornos, código, conjuntos de datos, modelos y canalizaciones de aprendizaje automático.
Validación del modelo: antes de implementar un modelo, es fundamental validar sus métricas de rendimiento. Puede tener varias métricas que se usan para indicar el "mejor" modelo. La validación de métricas de rendimiento de maneras relevantes para el caso de uso empresarial es fundamental. Azure Machine Learning admite la validación de modelos con muchas herramientas para evaluar las métricas del modelo, como las funciones de pérdida y las matrices de confusión.
Implementación de modelos: cuando se implementa un modelo, es importante que los científicos de datos e ingenieros de inteligencia artificial trabajen juntos para determinar la mejor opción de implementación. Estas opciones incluyen, nube, locales y dispositivos perimetrales (cámaras, drones, maquinaria).
Reentrenamiento del modelo: los modelos deben supervisarse y volver a entrenarse periódicamente para corregir los problemas de rendimiento y aprovechar las ventajas de los datos de entrenamiento más recientes. Azure Machine Learning admite un proceso sistemático e iterativo para refinar continuamente y garantizar la precisión del modelo.
Sugerencia

Historia de cliente: Una organización sanitaria usa Azure Machine Learning para entrenar modelos de aprendizaje automático personalizados que predicen la probabilidad de complicaciones durante los procedimientos quirúrgicos. Los modelos se entrenan con enormes volúmenes de datos, que incluyen factores como la edad, la etnia, el historial de consumo de tabaco, el índice de masa corporal y el recuento de plaquetas en sangre. El uso de estos modelos permite a los profesionales médicos evaluar mejor el riesgo y determinar las opciones de cirugía o las recomendaciones de cambio de estilo de vida para cada paciente. El panel de IA responsable en Azure Machine Learning ayuda a explicar los factores predictivos y a mitigar el sesgo de los factores demográficos. En última instancia, la solución de modelado predictivo ayuda a reducir el riesgo y la incertidumbre y a mejorar los resultados quirúrgicos. Lea aquí el artículo completo del cliente: https://aka.ms/azure-ml-customer-story.
Sugerencia
Dedique un momento a tener en cuenta cómo su organización puede aprovechar la experiencia en ciencia de datos y aprendizaje automático para crear modelos personalizados.

A continuación, vamos a encapsular todo con una comprobación de conocimientos.