Definición del aprendizaje supervisado
El proceso de entrenamiento de un modelo puede ser supervisado o sin supervisión. Nuestro objetivo es contrastar estos enfoques y analizar el proceso de aprendizaje con especial atención al aprendizaje supervisado. Merece la pena recordar a lo largo de este análisis que la única diferencia entre el aprendizaje supervisado y sin supervisión es cómo funciona la función objetivo.
¿Qué es el aprendizaje sin supervisión?
En el aprendizaje sin supervisión, se entrena un modelo para resolver un problema sin saber la respuesta correcta. De hecho, el aprendizaje sin supervisión normalmente se usa para los problemas en los que no hay una respuesta correcta, sino soluciones mejores y peores.
Imagine que queremos que nuestro modelo de aprendizaje automático dibuje imágenes realistas de perros de rescate de avalanchas. No hay un dibujo "correcto" para dibujar. Siempre que la imagen tenga un aspecto similar al de un perro, estaremos satisfechos. Sin embargo, si la imagen producida es de un gato, es una solución peor.
Recuerde que el entrenamiento requiere varios componentes:
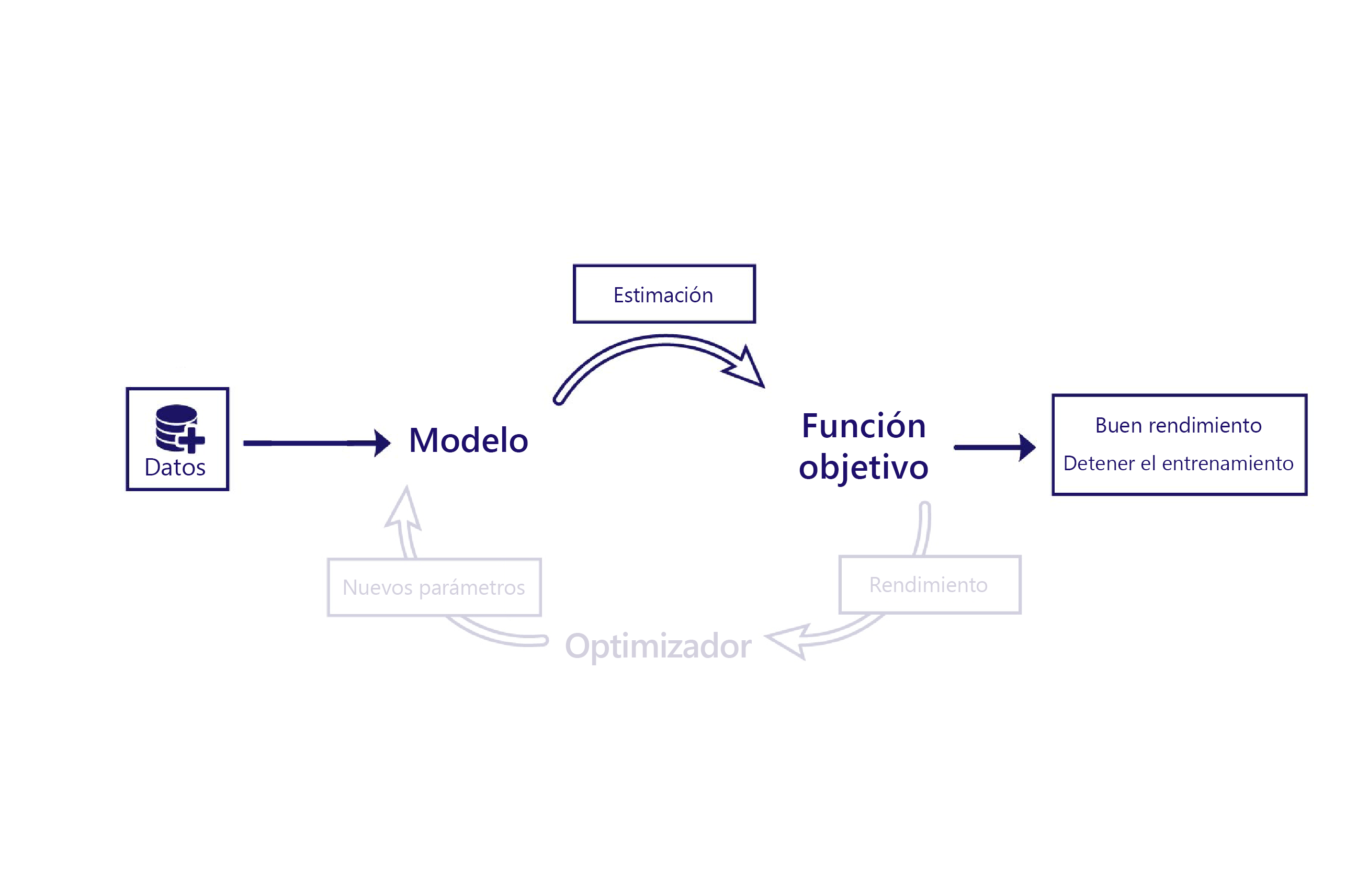
En el aprendizaje sin supervisión, la función objetivo establece su criterio basándose de forma exclusiva en la estimación del modelo. Esto significa que la función objetivo a menudo tiene que ser relativamente sofisticada. Por ejemplo, es posible que la función objetivo deba contener un "detector de perros" para evaluar si las imágenes que dibuja el modelo son realistas. Los únicos datos que necesitamos para el aprendizaje sin supervisión son las características que proporcionamos al modelo.
¿Qué es el aprendizaje supervisado?
Piense en el aprendizaje supervisado como aprendizaje por ejemplo. En el aprendizaje supervisado, el rendimiento del modelo se evalúa mediante la comparación de sus estimaciones con la respuesta correcta. Aunque podemos tener funciones objetivo sencillas, necesitamos:
- Características que se proporcionan como entradas al modelo
- Etiquetas, que son las respuestas correctas que queremos que el modelo pueda generar
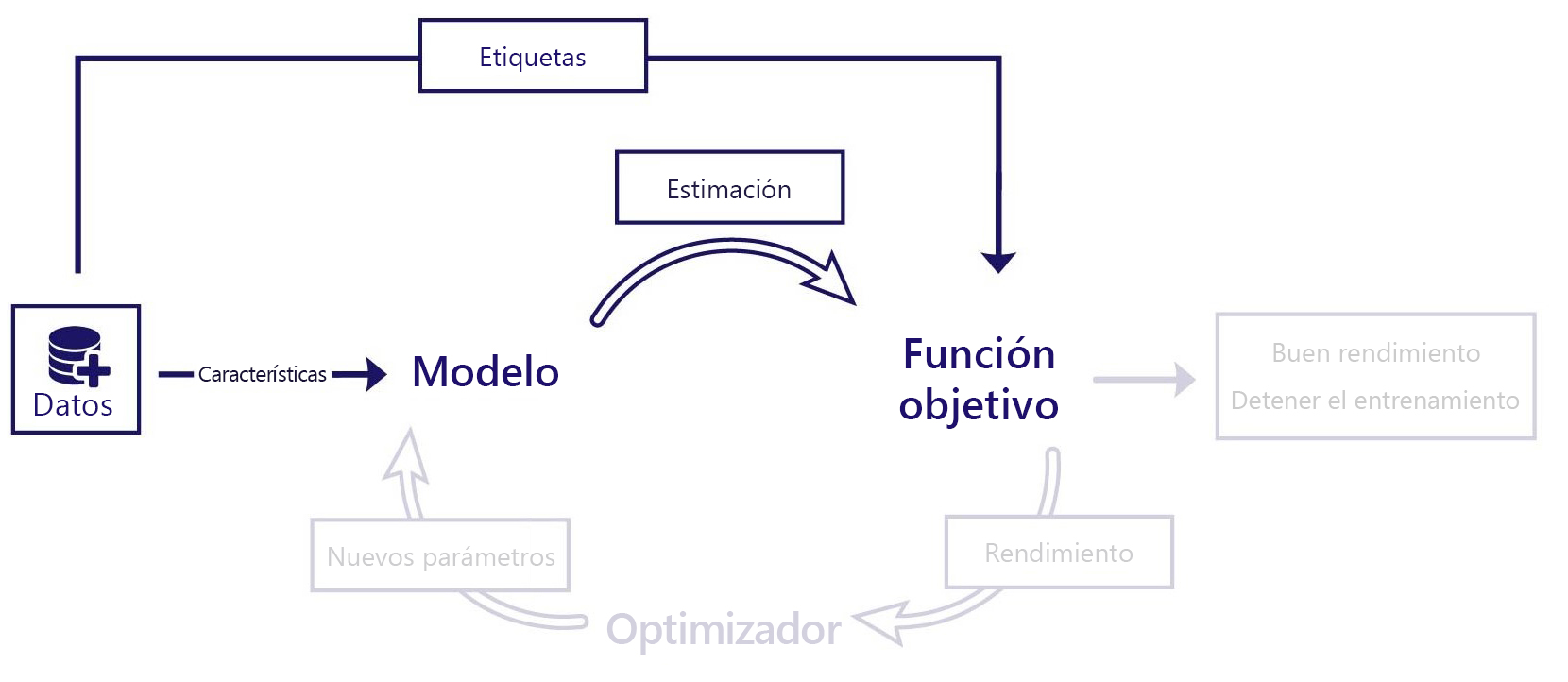
Por ejemplo, considere nuestra voluntad de predecir qué temperatura se alcanzará el 31 de enero de un año determinado. Para esta predicción, necesitamos datos con dos componentes:
- Característica: fecha
- Etiqueta: temperatura diaria (por ejemplo, de registros históricos)
En el escenario descrito, se proporciona la característica de la fecha al modelo. El modelo predice la temperatura y este resultado se compara con la temperatura "correcta" del conjunto de datos. La función objetivo calcula entonces la eficacia del modelo y podemos realizar ajustes en el modelo.
Las etiquetas son solo para el aprendizaje
Es importante recordar que, independientemente de cómo se entrenan, los modelos solo procesan las características. Durante el aprendizaje supervisado, la función objetivo es el único componente que depende del acceso a las etiquetas. Después del entrenamiento, no necesitamos las etiquetas para usar nuestro modelo.