Uso de Azure Data Lake Storage Gen2 en cargas de trabajo de análisis de datos
Azure Data Lake Store Gen2 es una tecnología de habilitación para varios casos de uso de análisis de datos. Veamos algunos tipos comunes de cargas de trabajo analíticas y cómo funciona Azure Data Lake Storage Gen2 con otros servicios de Azure para sustentarlos.
Procesamiento y análisis de macrodatos
Los escenarios de macrodatos suelen hacer referencia a cargas de trabajo analíticas que implican volúmenes masivos de datos en una gran variedad de formatos que deben procesarse a una velocidad rápida, lo que se denomina "las tres uves". Azure Data Lake Storage Gen 2 proporciona un almacén de datos distribuido, escalable y seguro en el que los servicios de macrodatos, como Azure Synapse Analytics, Azure Databricks y Azure HDInsight, pueden aplicar marcos de procesamiento de datos, como Apache Spark, Hive y Hadoop. La naturaleza distribuida del almacenamiento y la capacidad de procesamiento permiten realizar tareas en paralelo, lo que proporciona un alto rendimiento y una elevada escalabilidad incluso cuando se procesan enormes cantidades de datos.
Almacenamiento de datos
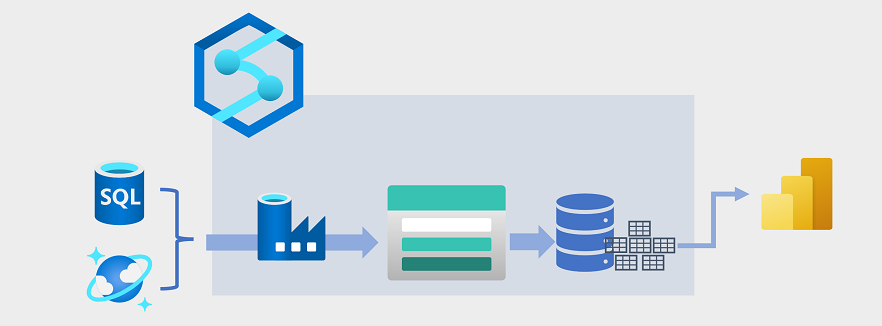
El almacenamiento de datos ha evolucionado en los últimos años para integrar grandes volúmenes de datos almacenados como archivos en un lago de datos con tablas relacionales en un almacenamiento de datos. En un ejemplo típico de solución de almacenamiento de datos, los datos se extraen de almacenes de datos operativos, como Azure SQL Database o Azure Cosmos DB, y se transforman en estructuras más adecuadas para cargas de trabajo analíticas. A menudo, los datos se almacenan provisionalmente en un lago de datos para facilitar el procesamiento distribuido antes de cargarlos en un almacenamiento de datos relacional. En algunos casos, el almacenamiento de datos usa tablas externas para definir una capa de metadatos relacionales en los archivos del lago de datos y crear una arquitectura híbrida de "almacén de lago de datos" o "base de datos de lago". Después, el almacenamiento de datos puede admitir consultas analíticas para la elaboración de informes y la visualización de los datos.
Hay varias maneras de implementar este tipo de arquitectura de almacenamiento de datos. En el diagrama se muestra una solución en la que Azure Synapse Analytics hospeda canalizaciones para realizar procesos de extracción, transformación y carga (ETL) con la tecnología de Azure Data Factory. Estos procesos extraen datos de orígenes de datos operativos y los cargan en un lago de datos hospedado en un contenedor de Azure Data Lake Storage Gen2. A continuación, los datos se procesan y cargan en un almacenamiento de datos relacional en un grupo de SQL dedicado de Azure Synapse Analytics, desde donde se pueden visualizar y usar para la elaboración de informes con Microsoft Power BI.
Análisis de datos en tiempo real
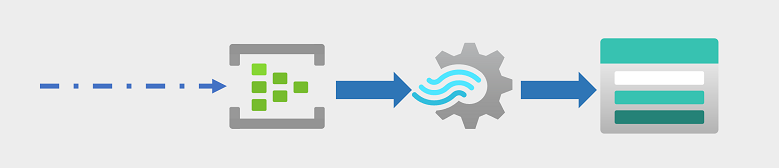
Cada vez más, las empresas y otras organizaciones necesitan capturar flujos perpetuos de datos y analizarlos en tiempo real (o lo más cerca posible). Estos flujos de datos pueden proceder de dispositivos conectados (a menudo denominados dispositivos de Internet de las cosas o IoT) o de los datos generados por los usuarios en plataformas de redes sociales u otras aplicaciones. A diferencia de las cargas de trabajo tradicionales de procesamiento por lotes, los datos de streaming requieren una solución que pueda capturar y procesar un flujo ilimitado de eventos de datos a medida que se producen.
Los eventos de streaming a menudo se capturan en una cola para su procesamiento. Hay varias tecnologías que puede usar para realizar esta tarea; por ejemplo, Azure Event Hubs, como se muestra en la imagen. Desde aquí, los datos se procesan, a menudo para agregar datos a través de ventanas temporales (por ejemplo, para contar el número de mensajes de redes sociales con una etiqueta determinada cada cinco minutos, o para calcular el promedio de lecturas de un sensor conectado a Internet por minuto). Azure Stream Analytics permite crear trabajos que consultan y agregan datos de eventos a medida que llegan y escriben los resultados en un receptor de salida. Uno de estos receptores es Azure Data Lake Storage Gen2, desde donde se pueden analizar y visualizar los datos capturados en tiempo real.
Ciencia de datos y aprendizaje automático

La ciencia de datos implica el análisis estadístico de grandes volúmenes de datos, a menudo mediante herramientas como Apache Spark y lenguajes de scripting, como Python. Azure Data Lake Storage Gen 2 proporciona un almacén de datos basado en la nube altamente escalable para los volúmenes de datos necesarios en las cargas de trabajo de ciencia de datos.
El aprendizaje automático es una subárea de la ciencia de datos que se ocupa del entrenamiento de modelos predictivos. El entrenamiento de modelos requiere grandes cantidades de datos y la capacidad de procesar esos datos de forma eficaz. Azure Machine Learning es un servicio en la nube en el que los científicos de datos pueden ejecutar código de Python en cuadernos usando recursos de proceso distribuidos asignados dinámicamente. Los recursos de proceso procesan los datos de los contenedores de Azure Data Lake Storage Gen2 para entrenar modelos, que luego se pueden implementar como servicios web de producción para admitir cargas de trabajo de análisis predictivo.