El aprendizaje automático y el ciclo de vida de la ciencia de datos
El aprendizaje automático forma parte de un campo más amplio: la ciencia de datos. Consiste esencialmente en el proceso de creación de conocimiento a partir de datos sin procesar.
Se requiere un esfuerzo considerable para convertir datos sin procesar en conocimiento. Por ejemplo, imagine que tiene una huerta en la que quiere plantar lechugas. Quiere optimizarla para poder cultivar la máxima cantidad de lechugas en el menor período de tiempo. Puede recopilar una gran cantidad de datos que influirán en el modo en que configura el entorno más eficaz para cultivar lechugas.
Como factores, puede considerar la exposición a la luz solar, la temperatura, la humedad del suelo y el aire, el tipo de lechuga y el origen de las semillas, la exposición al aire fresco, el tamaño del macetero y la calidad y la cantidad de tierra. La lista puede ser incluso más extensa, ya que podría haber factores que afecten al crecimiento y que ni siquiera conozca, como el nivel de ruido o el tipo de ruido junto a la huerta.
Ciclo de vida de ciencia de datos
Si entiende el ciclo de vida de la ciencia de datos, podrá orientar mejor sus esfuerzos cuando cree nuevos conocimientos a partir de orígenes de datos.
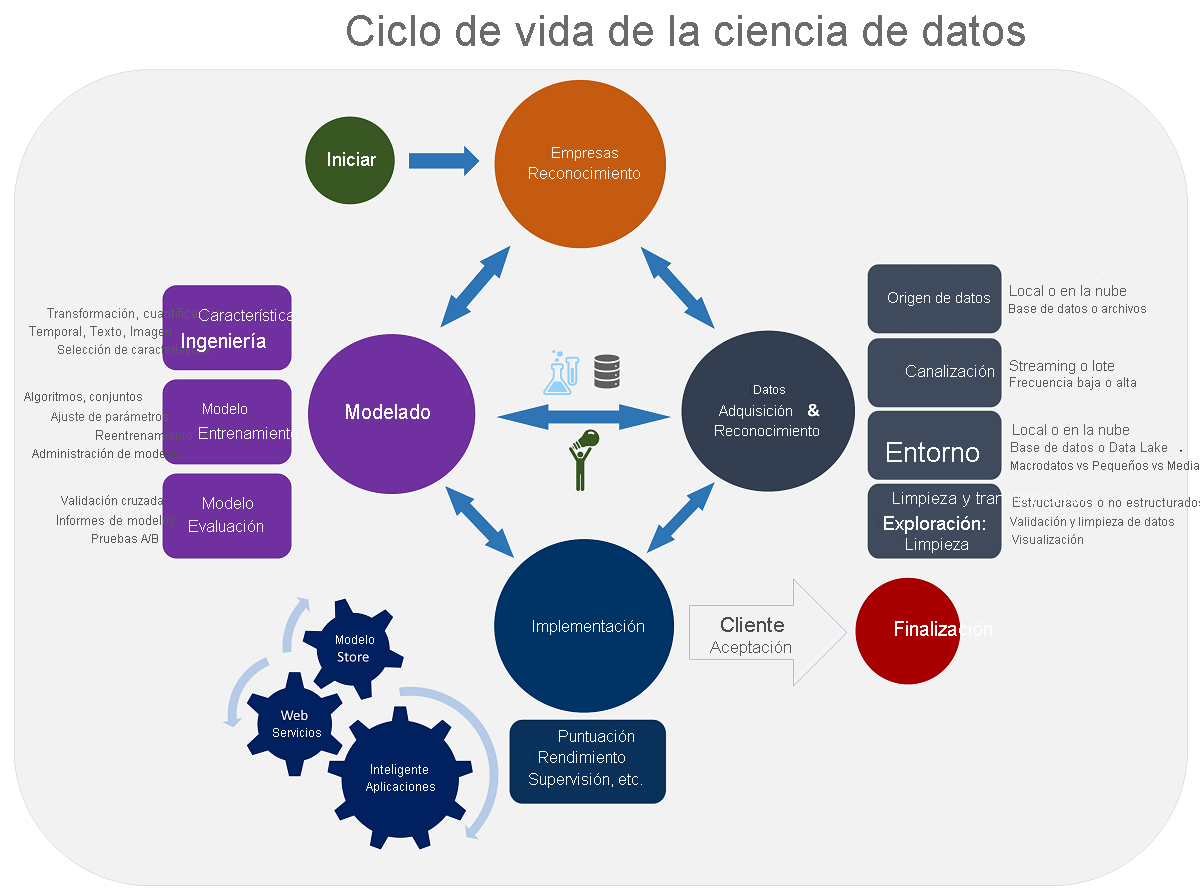
Estos son los cuatro pasos del ciclo de vida de la ciencia de datos:
- Definición de un objetivo empresarial mediante la experiencia en la materia
- Recopilación, limpieza y manipulación de los datos
- Elección de un algoritmo de aprendizaje automático y, después, entrenamiento y prueba del modelo
- Implementación del modelo para usarlo con otras aplicaciones
Siga leyendo para ver con más detalle cada paso del ciclo de vida de la ciencia de datos.