Funcionamiento de Azure HDInsight
Aquí aprenderá cómo funciona Azure HDInsight. Encontrará información acerca de los siguientes componentes y del modo en que encajan para proporcionar control y administración de datos:
- Apache Hadoop
- Almacenamiento de HDInsight
- Procesamiento de HDInsight
¿Qué es Apache Hadoop?
Apache Hadoop es un sistema de procesamiento de datos distribuido en la nube en el núcleo de HDInsight. Tiene tres componentes, que se describen en la tabla siguiente:
| Componente de Apache Hadoop | Descripción |
|---|---|
| HDFS | El Sistema de archivos distribuido de Apache Hadoop (HDFS) proporciona almacenamiento para el sistema de Hadoop. |
| YARN | El componente Yet Another Resource Negotiator (YARN) de Apache Hadoop proporciona procesamiento para el sistema. |
| MapReduce | MapReduce es un modelo de programación que permite procesar y analizar datos. |
¿Cómo interactúan los componentes?
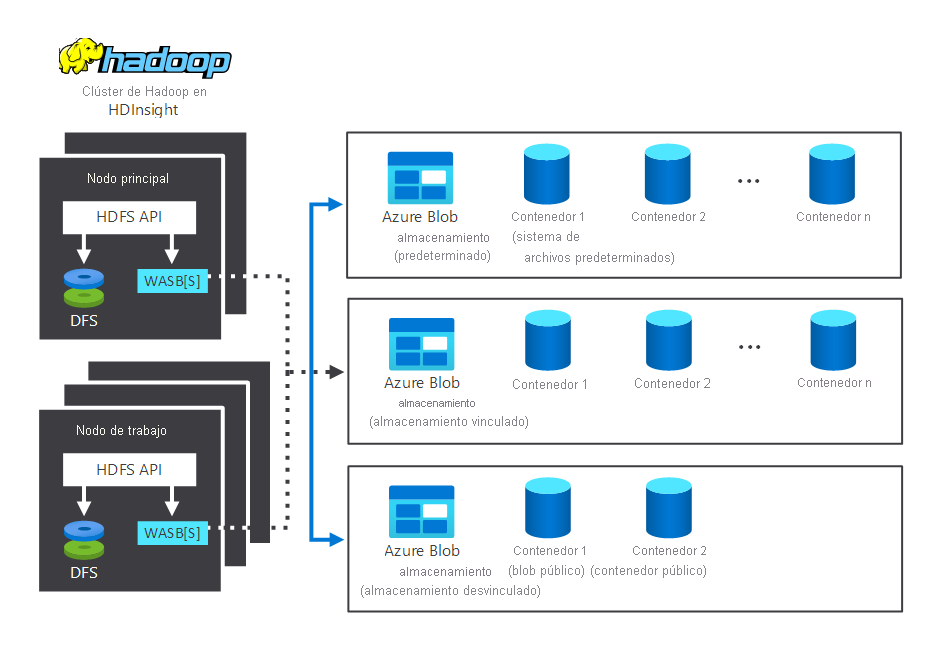
En el diagrama siguiente se muestran los componentes de almacenamiento y procesamiento que interactúan en un clúster de Hadoop de HDInsight típico. Muestra los siguientes componentes:
- El nodo principal y los nodos de trabajo, que llevan a cabo el procesamiento.
- Varios centros de almacenamiento de Windows Azure Storage Blob (WASB) dentro de los nodos. HDFS interactúa con estos contenedores.
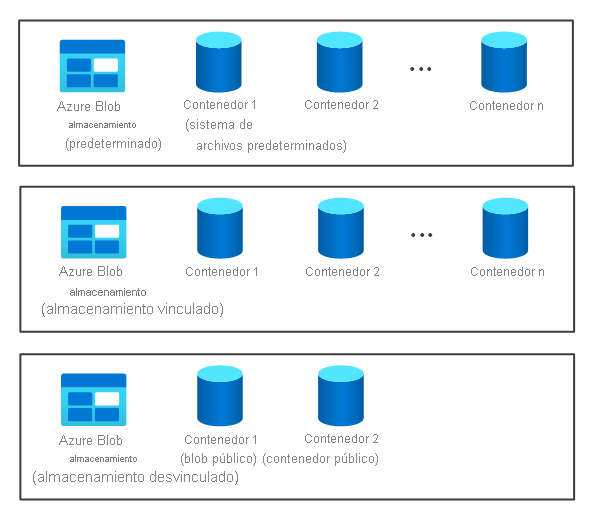
- Varios contenedores de almacenamiento predeterminados, vinculados y desvinculados. Están disponibles para los dos nodos.
Ahora se examinará cómo funcionan el almacenamiento y el procesamiento.
¿Cómo funciona el almacenamiento?
El componente de almacenamiento de un clúster no se crea automáticamente al aprovisionar un clúster de HDInsight. En su lugar, se proporciona mediante un sistema compatible con HDFS, como Azure Storage o Azure Data Lake.
Hay ciertas ventajas al separar el componente de almacenamiento de un clúster del componente de procesamiento. Por ejemplo, puede eliminar de forma segura los clústeres de HDInsight usados solo para el cálculo sin preocuparse por la pérdida de datos. Cuando agregue un clúster de HDInsight, deberá definir un sistema de archivos predeterminado.
Importante
Para Azure Storage, deberá especificar un contenedor de blobs como sistema de archivos predeterminado.
Proporcionar un sistema de archivos predeterminado garantiza que HDInsight pueda resolver las referencias relativas de archivo al buscar archivos.
Sugerencia
Si quiere aumentar el almacenamiento disponible, puede vincular y desvincular sistemas de archivos adicionales según sea necesario.
¿Cómo funciona el procesamiento?
Al procesar datos, el componente de proceso de un clúster de Hadoop en HDInsight se divide en dos áreas lógicas. En la tabla siguiente se describen estas dos áreas:
| Componente | Descripción |
|---|---|
| Nodo principal | El nodo principal acepta y administra las solicitudes de cliente y las pasa a los nodos de trabajo. |
| Nodo de trabajo | Los nodos de trabajo procesan los datos. |
Nota:
El nodo principal se conoce a veces como nodo maestro.
La mayoría de los clústeres contienen dos nodos principales, incluidos:
- Un nodo principal activo, que administra las conexiones de cliente.
- Un nodo principal pasivo, que proporciona resistencia si el nodo activo se desconecta.
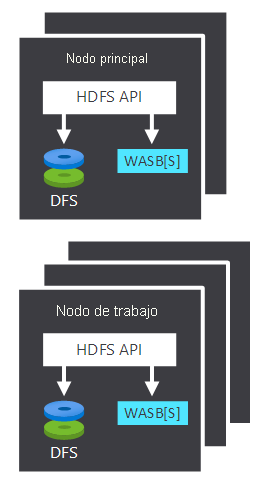
Tanto el nodo principal como el de trabajo pueden conectarse directamente a un HDFS conectado localmente o acceder a los datos que se almacenan en Azure Blob o Azure Data Lake. Los datos que se administran dependen de dos factores:
- Cómo ha definido el modelo de programación de MapReduce la manera de trabajar con los datos.
- Cómo asigna el nodo principal el trabajo.
¿Qué hace YARN?
YARN ejecuta la administración de recursos dentro de un clúster de HDInsight. Al procesar datos, este servicio administra los recursos y la programación de trabajos.
YARN se encuentra entre el HDFS y el sistema de cálculo del clúster de HDInsight. Funciona con el nodo principal para ayudar a distribuir un trabajo entre los nodos de trabajo del clúster. Esto ayuda a garantizar que los trabajos de procesamiento de datos se produzcan en paralelo.