¿Qué es Azure HDInsight?
Vamos a revisar las características y los usos de HDInsight. Esta información general le ayudará a evaluar si HDInsight aborda los requisitos de su organización.
¿Qué son grandes volúmenes de datos?
El término macrodatos describe los grandes volúmenes de datos estructurados y no estructurados que recopilan las organizaciones. Estos datos pueden ser muy útiles para las organizaciones. En concreto, si una organización puede analizar los datos para obtener información, estará mejor capacitada para tomar decisiones. El resultado es que estas decisiones pueden ayudar a una organización a tener más éxito. Por ejemplo, el análisis de los macrodatos podría permitir que una organización comercial reconociese los hábitos de los clientes, lo que podría provocar un aumento de las ventas.
Definición de Azure HDInsight
Azure HDInsight es un servicio de análisis de código abierto, basado en la nube y totalmente administrado para empresas. HDInsight le permite controlar y administrar los macrodatos. HDInsight:
Es una distribución de nube de componentes de Hadoop.
Hace que sea más fácil, rápido y rentable procesar grandes volúmenes de datos.
Admite el uso de marcos de código abierto, como:
- Hadoop
- Spark de Apache
- Apache Hive
- Apache Kafka
Nota:
Con estas plataformas puede habilitar una amplia gama de escenarios, como la extracción, transformación y carga (ETL), el almacenamiento de datos, el aprendizaje automático e IoT.
HDInsight proporciona varias ventajas para las organizaciones que trabajan con macrodatos. Es:
De código abierto: permite crear clústeres optimizados para varios marcos de código abierto.
De confianza: proporciona un Acuerdo de Nivel de Servicio de un extremo a otro para todas las cargas de trabajo de producción.
Escalable: permite escalar las cargas de trabajo para responder a los cambios de demanda.
Sugerencia
Al crear clústeres a petición, puede reducir los costos. Solo se paga lo que se usa.
Seguro: permite proteger los recursos de datos empresariales mediante la integración con:
- Azure Virtual Network
- Tecnologías de cifrado de Azure
- Microsoft Entra ID
Cumplimiento: cumple los estándares de cumplimiento populares del sector y de la administración.
Supervisado: se integra con los registros de Azure Monitor para proporcionar una sola interfaz. Supervise todos los clústeres mediante la interfaz única.
Procedimiento para que HDInsight le ayude a trabajar con macrodatos
Puede usar HDInsight para muchos escenarios mediante el procesamiento de macrodatos. Los datos pueden ser:
- Datos históricos: estos datos ya se han recopilado y almacenado.
- Datos en tiempo real: estos datos se transmiten directamente desde el origen.
En las categorías siguientes se resumen los escenarios de procesamiento de estos datos:
- Procesamiento por lotes
- Almacenamiento de datos
- IoT
- Ciencia de datos
- Híbrido
Vamos a examinar estas categorías más de cerca.
Procesamiento por lotes
Las organizaciones usan trabajos de procesamiento por lotes para preparar los macrodatos para su posterior análisis. Normalmente, este proceso implica tres fases:
- Lectura de archivos de datos de origen de orígenes de datos heterogéneos.
- Procesamiento de los datos.
- Escritura de los datos en un almacenamiento escalable.
Nota:
Este proceso se conoce a menudo como ETL.
Los datos transformados se pueden usar para almacenamiento de datos o ciencia de datos.
Sugerencia
Un requisito importante para ETL es el escalado horizontal de proceso. Esto permite el procesamiento de grandes volúmenes de datos.
Almacenamiento de datos
Un almacenamiento de datos proporciona a una organización un lugar donde almacenar los macrodatos mientras espera a analizarlos. El almacenamiento de datos le permite:
- Almacenar los datos.
- Preparar los datos para el análisis.
- Proporcionar los datos preparados en un formato estructurado. A continuación, puede consultar los datos mediante herramientas de análisis.
En el diagrama siguiente se muestra cómo Apache Hadoop en HDInsight recopila y almacena datos de varios orígenes. Apache Spark y Apache Hive preparan y analizan los datos. Por último, los datos se modelan para su uso con herramientas de inteligencia empresarial (BI). Power BI se usa para la visualización de los datos.
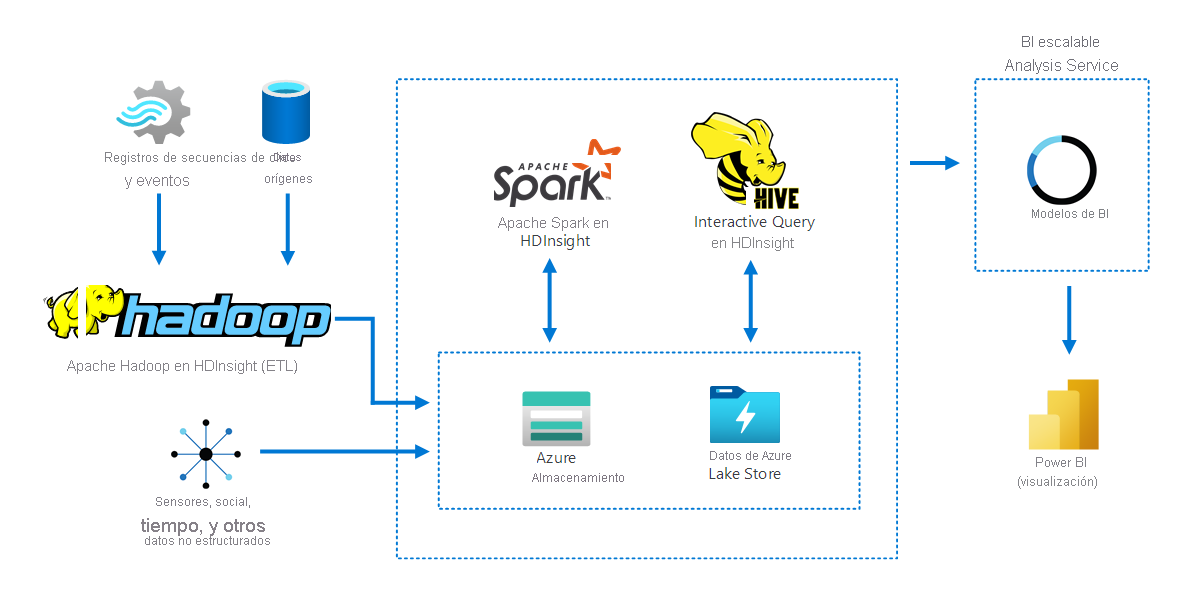
Los componentes de este escenario son:
- Apache Spark es un marco de procesamiento paralelo. Admite el procesamiento en memoria, que ayuda a aumentar el rendimiento de las aplicaciones de análisis de los macrodatos.
- Apache Hive en HDInsight es un sistema de almacenamiento de datos para Apache Hadoop. Hive habilita el resumen, las consultas y el análisis de los datos. Puede usar estos componentes para realizar consultas a escalas de petabytes sobre datos estructurados o no estructurados en cualquier formato.
Sugerencia
Las consultas de Hive se escriben en HiveQL, un lenguaje de consulta similar a SQL.
Internet de las cosas
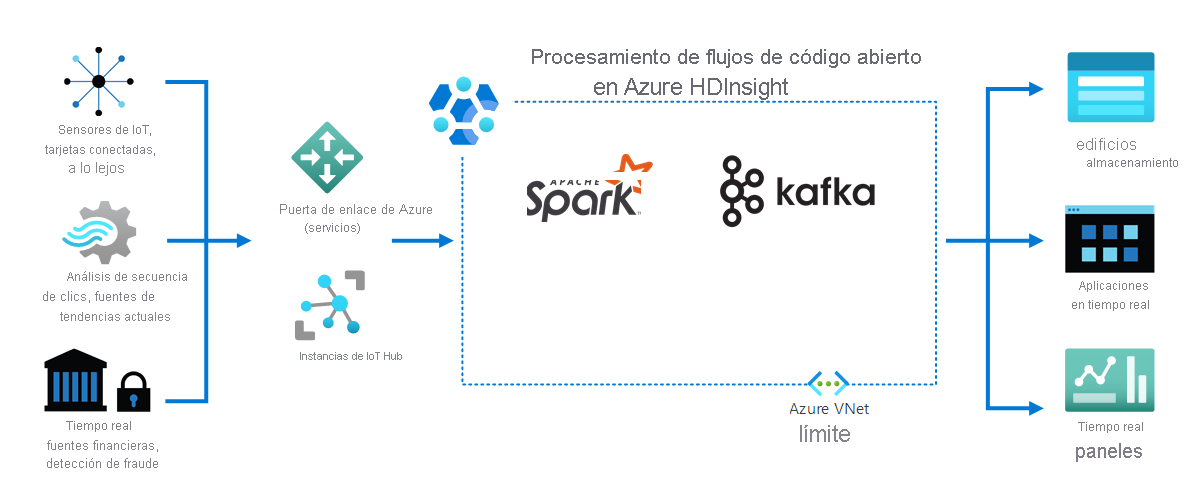
Como se muestra en el diagrama siguiente, HDInsight procesa los datos de streaming recibidos en tiempo real de diferentes dispositivos y sensores. En este ejemplo, varios marcos de código abierto proporcionan procesamiento de flujos, entre los que se incluyen Apache Spark y Apache Kafka.
Los servicios de puerta de enlace de Azure y los centros de IoT dirigen los datos de varios orígenes a estos marcos. A continuación, los marcos procesan los datos y pasan a:
- Almacenamiento a largo plazo.
- Aplicaciones en tiempo real.
- Paneles en tiempo real.
Ciencia de datos
Puede usar HDInsight para completar tareas comunes de ciencia de datos, como:
- Ingesta de datos.
- Diseño de características.
- Modelado.
- Evaluación del modelo.
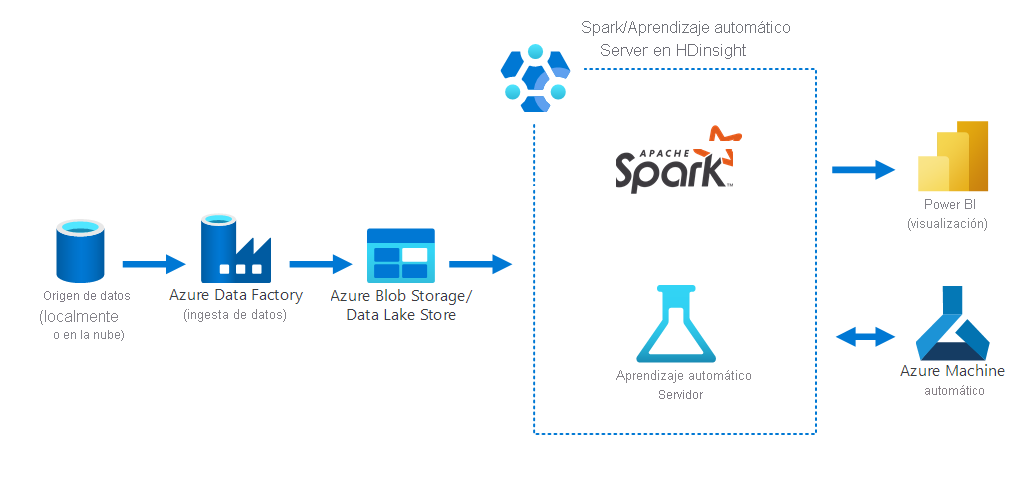
En el diagrama siguiente se muestra un escenario de ciencia de datos, en el que:
- Los datos se recopilan de un origen de datos local mediante Azure Data Factory.
- A continuación, los datos ingeridos se almacenan en Azure Storage (ya sea Azure Blob Storage o Data Lake Store).
- Azure Spark en HDInsight procesa y prepara los datos para Azure Machine Learning. Los datos también se visualizan mediante Power BI.
Híbrido
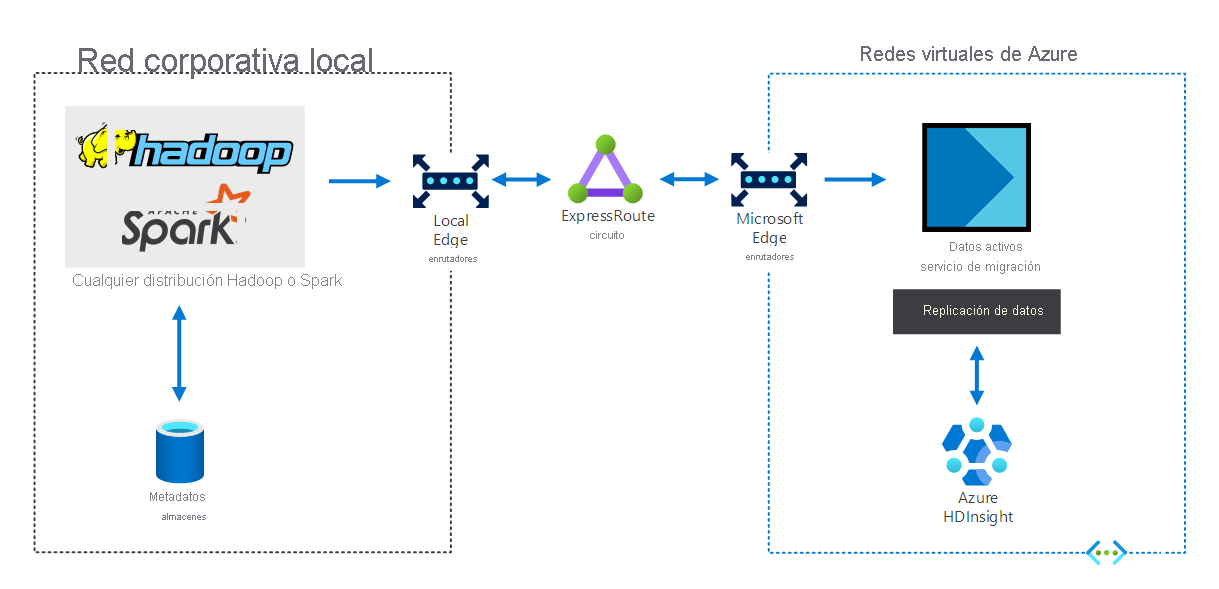
Las organizaciones que tienen una infraestructura de macrodatos local pueden usar HDInsight para extenderse a Azure. Esto le proporciona las ventajas de las funcionalidades de análisis avanzado de la nube de Azure. En el diagrama siguiente se muestra el escenario híbrido, en el que:
- La infraestructura de macrodatos local consta de almacenes de metadatos y una distribución de Hadoop o Spark en máquinas virtuales locales.
- Un circuito de Azure ExpressRoute conecta el entorno de red corporativa local a redes virtuales de Azure.
- Un migrador de datos dinámicos para Azure replica los datos recibidos del entorno local a HDInsight.