Funcionamiento de Azure Data Factory
Aquí aprenderá sobre los componentes y sistemas interconectados de Azure Data Factory y cómo funcionan. Estos conocimientos deberían ayudarle a determinar la mejor manera de utilizar Azure Data Factory para satisfacer las necesidades de su organización.
Azure Data Factory es una colección de sistemas interconectados que se combinan para proporcionar una plataforma de análisis de datos de un extremo a otro. En esta unidad, aprenderá sobre las siguientes funciones de Azure Data Factory:
- Conectar y recopilar
- Transformar y enriquecer
- Integración continua y entrega continua (CI/CD), y publicación
- Supervisión
También aprenderá sobre estos componentes clave de Azure Data Factory:
- Pipelines
- Actividades
- Conjuntos de datos
- Servicios vinculados
- Flujos de datos
- Entornos de ejecución de integración
Funciones de Azure Data Factory
Azure Data Factory consta de varias funciones que se combinan para proporcionar a los ingenieros de datos una plataforma de análisis de datos completa.
Conectar y recopilar
La primera parte del proceso consiste en recopilar los datos necesarios de los orígenes de datos adecuados. Estas fuentes pueden estar ubicadas en diferentes lugares, incluidas las fuentes locales y en la nube. Los datos pueden ser:
- Estructurados
- Datos no estructurados
- Semiestructurados
Además, es posible que estos datos dispares lleguen a velocidades e intervalos diferentes. Con Azure Data Factory, puede usar la actividad de copia para mover datos de varios orígenes a un único almacén de datos centralizado en la nube. Una vez copiados los datos, se utilizan otros sistemas para transformarlos y analizarlos.
La actividad de copia realiza los siguientes pasos generales:
Leer datos del almacén de datos de origen.
Realizar las tareas siguientes en los datos:
- Serialización y deserialización
- Compresión y descompresión
- Asignación de columnas
Nota:
Es posible que haya tareas adicionales.
Escribir datos en el almacén de datos de destino (conocido como receptor).
Este proceso se resume en el diagrama siguiente:

Transformar y enriquecer
Una vez copiados correctamente los datos en una ubicación central basada en la nube, puede procesarlos y transformarlos según sea necesario utilizando los flujos de datos de asignación de Azure Data Factory. Los flujos de datos permiten crear gráficos de transformación de datos que se ejecutan en Spark. Pero no es necesario comprender los clústeres ni la programación de Spark.
Sugerencia
Aunque no sea necesario, es posible que prefiera programar las transformaciones de forma manual. En ese caso, Azure Data Factory admite actividades externas para ejecutar las transformaciones.
CI/CD y publicación
La compatibilidad con CI/CD le permite desarrollar y entregar sus procesos de extracción, transformación y carga (ETL) de forma incremental antes de publicarlos. Azure Data Factory proporciona CI/CD de las canalizaciones de datos mediante lo siguiente:
- Azure DevOps
- GitHub
Nota
La integración continua significa probar cada cambio realizado en el código base automáticamente tan pronto como sea posible. La entrega continua sigue estas pruebas e inserta los cambios en un sistema de almacenamiento provisional o producción.
Una vez que Azure Data Factory refina los datos sin procesar, puede cargarlos en cualquier motor de análisis al que sus usuarios empresariales puedan acceder desde sus herramientas de inteligencia empresarial, incluidos:
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Monitor
Una vez creada e implementada con éxito la canalización de integración de datos, es importante que pueda supervisar las actividades y canalizaciones programadas. La supervisión le permite realizar un seguimiento de los índices de éxito y fracaso. Azure Data Factory ofrece soporte para la supervisión de canalizaciones mediante uno de los siguientes métodos:
- Azure Monitor
- API
- PowerShell
- Registros de Azure Monitor
- Paneles de estado en Azure Portal
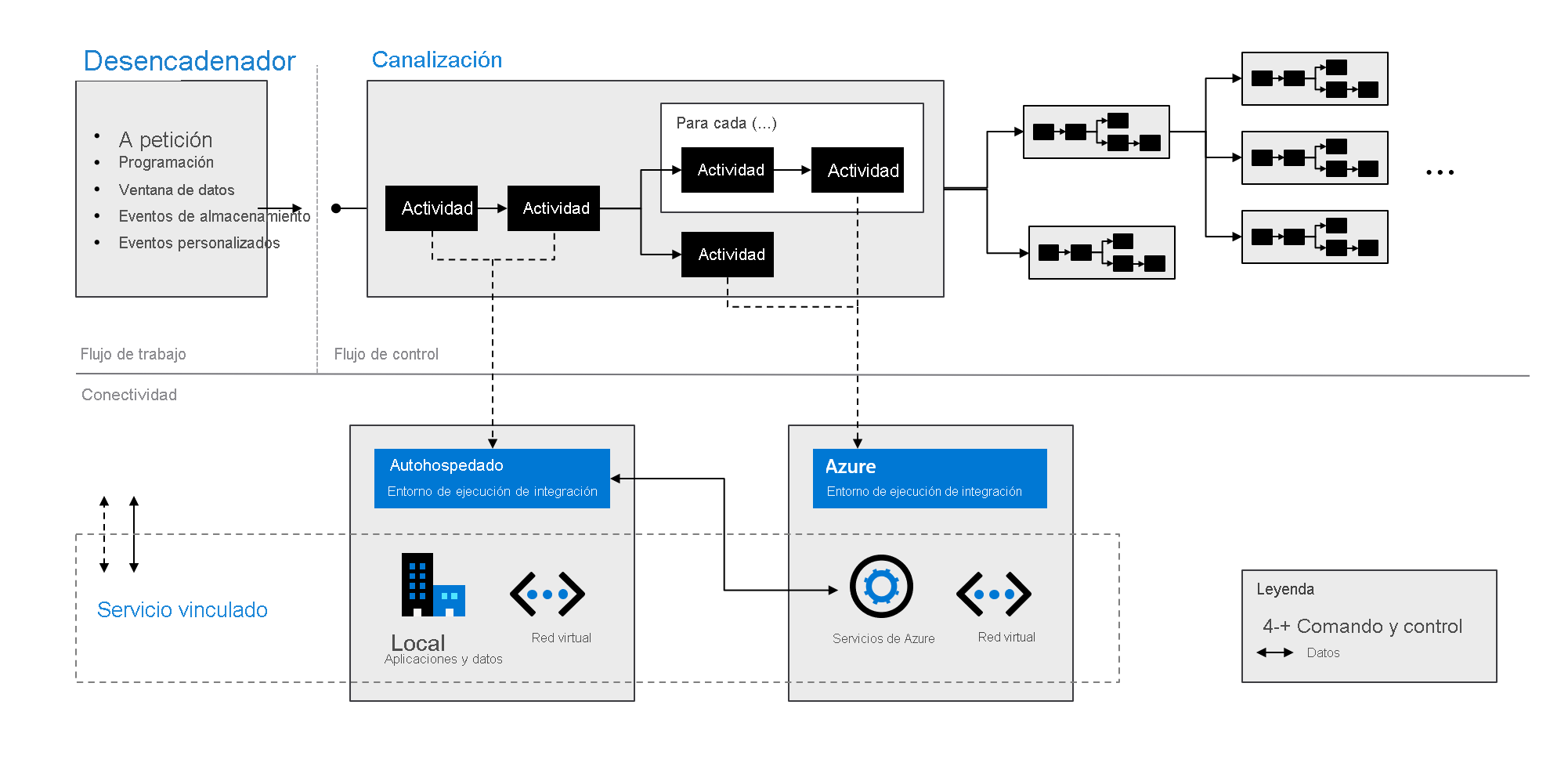
Componentes de Azure Data Factory
Azure Data Factory consta de los componentes descritos en la tabla siguiente:
| Componente | Descripción |
|---|---|
| Procesos | Agrupación lógica de actividades que realizan una unidad de trabajo específica. Estas actividades realizan una tarea de forma conjunta. La ventaja de usar una canalización es que puede administrar más fácilmente las actividades como un conjunto, en lugar de como elementos individuales. |
| Actividades | Un único paso de procesamiento en una canalización. Data Factory admite tres tipos de actividades: de movimiento de datos, de transformación de datos y de control. |
| Conjuntos de datos | Representan estructuras de datos dentro de los almacenes de datos. Los conjuntos de datos apuntan (o hacen referencia) a los datos que desea utilizar en sus actividades como entradas o salidas. |
| Servicios vinculados | Definen la información de conexión necesaria para que Azure Data Factory se conecte a recursos externos, como un origen de datos. Azure Data Factory utiliza servicios vinculados con dos fines: representar un almacén de datos o un recurso informático. |
| Flujos de datos | Permiten que los ingenieros de datos desarrollen lógica de transformación de datos sin necesidad de escribir código. Los flujos de datos se ejecutan como actividades en las canalizaciones de Azure Data Factory que usan clústeres de Apache Spark con escalabilidad horizontal. |
| Entornos de ejecución de integración | Azure Data Factory utiliza la infraestructura informática para proporcionar las siguientes capacidades de integración de datos en diferentes entornos de red: flujo de datos, movimiento de datos, envío de actividades y ejecución de paquetes de SQL Server Integration Services (SSIS). En Azure Data Factory, un entorno de ejecución de integración proporciona el puente entre la actividad y los servicios vinculados. |
Como se indica en el gráfico siguiente, estos componentes funcionan conjuntamente para proporcionar una plataforma completa de un extremo a otro para los ingenieros de datos. Con Azure Data Factory puede hacer lo siguiente:
- Establecer desencadenadores a petición y programar el procesamiento de los datos en función de las necesidades.
- Asociar una canalización a un desencadenador, o bien iniciarla manualmente cuando sea necesario.
- Conectarse a servicios vinculados, como aplicaciones y datos locales, o a servicios de Azure mediante entornos de ejecución de integración.
- Supervisar todas las ejecuciones de canalización de forma nativa en la experiencia del usuario de Azure Data Factory o mediante Azure Monitor.