Cómo funciona HDInsight
HDInsight es un sistema de procesamiento de datos distribuido en la nube que tiene una disponibilidad y una seguridad elevadas de forma predeterminada. La piedra angular de este sistema es Apache Hadoop. Apache Hadoop incluye dos componentes principales: Sistema de archivos distribuido de Apache Hadoop (HDFS), que se usa para el almacenamiento, y Yet Another Resource Negotiator (YARN), que proporciona procesamiento. Además, es un modelo de programación de MapReduce simple que permite procesar y analizar datos. Como ventajas del uso de MapReduce, cabe destacar su facilidad de configuración y la posibilidad de controlar los costos mediante la característica de escalado automático.
Storage
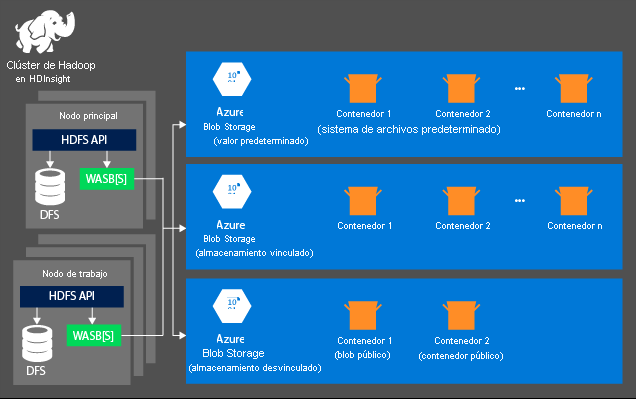
El aspecto del almacenamiento no se crea automáticamente al aprovisionar un clúster de HDInsight. En su lugar, se proporciona mediante un sistema compatible con HDFS, como Azure Storage o Azure Data Lake. Desacoplar el almacenamiento de la capa de procesamiento le permite eliminar de forma segura los clústeres de HDInsight que se usan para el cálculo sin perder datos del usuario. Cuando agregue un clúster de HDInsight, deberá definir un sistema de archivos predeterminado. Puede vincular y desvincular sistemas de archivos según sea necesario para aumentar el tamaño del almacenamiento.
La siguiente información es específica de HDInsight 3.6 y las versiones posteriores. Durante el proceso de creación de clústeres de HDInsight, puede seleccionar Azure Storage o Azure Data Lake Storage Gen2 como sistema de archivos predeterminado (con algunas excepciones). Proporcionar un sistema de archivos predeterminado garantiza que se puedan resolver las referencias relativas de archivo al buscar archivos. Para Azure Storage, debe especificar un contenedor de blobs como sistema de archivos predeterminado.
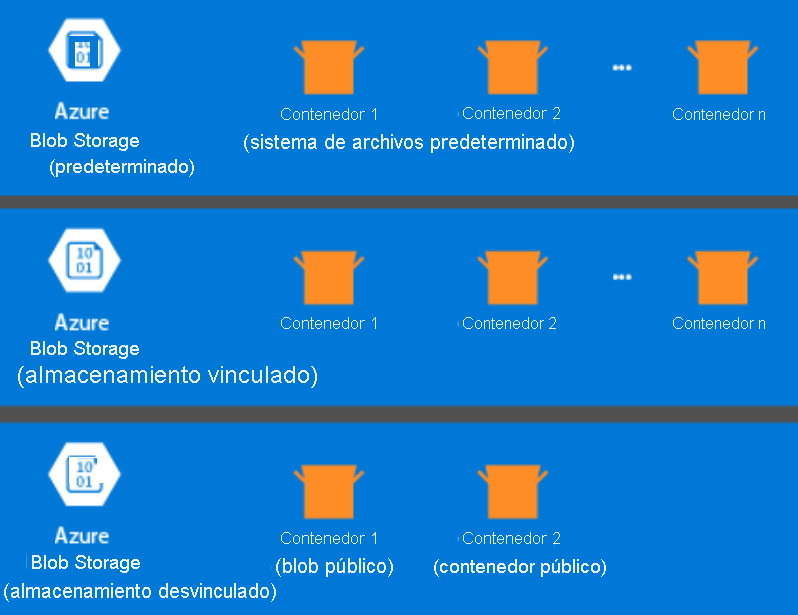
La mayoría de las configuraciones usan Azure Data Lake Storage Gen2. Este tipo de configuración usa las características principales de un sistema de archivos que son compatibles con Hadoop, la integración de Microsoft Entra y las listas de control de acceso (ACL) basadas en POSIX. Puede usar Azure Blob Storage para la compatibilidad con versiones anteriores, pero le recomendamos encarecidamente que use Azure Data Lake Storage Gen2 siempre que sea posible.
Processing
Al procesar los datos, el aspecto del proceso de un clúster de Hadoop en HDInsight se divide en dos áreas lógicas: los nodos principales (maestros) y los nodos de trabajo. El nodo principal (maestro) se encarga de aceptar y administrar las solicitudes de cliente y, a continuación, de pasar la solicitud en cuestión a los nodos de trabajo para que realicen el procesamiento de los datos. Normalmente, hay dos nodos maestros: uno activo que administrará las conexiones de cliente y otro pasivo que actuará de refuerzo en el caso de que el principal se quede sin conexión.
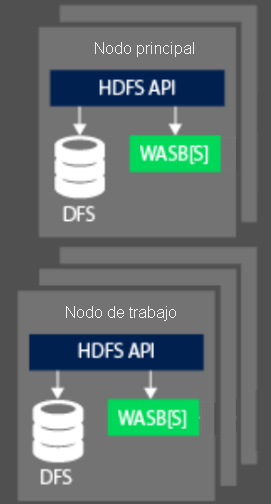
El nodo de trabajo se encarga de procesar los datos que le ha asignado el nodo maestro. Los datos administrados dependerán de cómo el modelo de programación de MapReduce haya definido la forma de trabajar con los datos y de cómo el nodo maestro asigne el trabajo. Tanto el nodo principal como el de trabajo pueden conectarse a un sistema de archivos distribuido conectado localmente (DFS), ya sea directamente o mediante el acceso a los datos que se almacenan en Azure Blob Storage o Azure Data Lake.
Desde la perspectiva del OSS, las funcionalidades de administración de recursos de un clúster de HDInsight se realizan mediante YARN. Este servicio administra los recursos y la programación de trabajos que se lleva a cabo cuando se procesan datos. Se encuentra entre el HDFS y el sistema de cálculo del clúster de HDInsight. El servicio funciona con otras tecnologías de OSS para asegurarse de que los recursos para procesar el trabajo de HDInsight estén disponibles. YARN funciona con el nodo principal para distribuir el trabajo entre los nodos de trabajo del clúster con el fin de asegurarse de que los trabajos de procesamiento de datos se ejecuten en paralelo.
HDFS, YARN y MapReduce son los tres servicios principales necesarios para Hadoop en HDInsight. Es habitual usar tecnologías de OSS adicionales para facilitar la creación de una solución. Por ejemplo, puede usar Hive como capa de abstracción. Se encuentra encima de MapReduce para que pueda escribir construcciones de lenguaje de tipo SQL con el fin de realizar análisis y procesamiento de datos ad hoc. También puede usar Apache Ambari para realizar la supervisión en el clúster de HDInsight.