Requisitos de acceso a archivos híbridos
En gran medida, las unidades anteriores se centraban en lo que hace la solución de almacenamiento. Esta unidad se centrará en dónde se encuentran los datos. Específicamente, se describirán consideraciones sobre el acceso a archivos híbridos y cómo abordarlas.
Información general sobre el acceso a archivos híbridos
Ha decidido ejecutar una carga de trabajo de HPC en Azure que actualmente se ejecuta en el centro de datos. El entorno de proceso accede a los datos en NAS, que atiende las operaciones de NFSv3 con la carga de trabajo. Ha estado en funcionamiento durante años, pero tal vez su entorno NAS está llegando al final de su ciclo. En lugar de reemplazarlo, está considerando la posibilidad de realizar una migración a largo plazo a la nube.
Después de tomar esta decisión, pero antes de la implementación completa en la nube de la carga de trabajo de HPC, debe determinar la estrategia de Azure y establecer la configuración de la cuenta, la suscripción y la seguridad de línea de base. Ahora viene la parte más difícil: trasladar las cargas de trabajo de HPC.
La construcción del clúster HPC y su plano de administración están fuera del alcance de este módulo. Se supone que ha determinado qué tipos y cantidades de máquinas virtuales desea ejecutar en el clúster.
Por ahora, también supondremos que su objetivo es ejecutar la carga de trabajo tal cual. Es decir, no modificará los métodos de acceso ni la lógica que están implementados de forma local. La implicación es que el código espera que los datos estén en rutas de acceso de directorio en los sistemas de archivos locales de los miembros del clúster.
El primer objetivo es comprender qué datos se necesitan y de dónde proceden. Es posible que los datos estén en un único directorio de un único entorno NAS o que estén distribuidos por varios entornos.
El siguiente objetivo consiste en determinar cuántos datos se necesitan para ejecutar la carga de trabajo. ¿Los datos de origen son un par de gigabytes o cientos de terabytes?
Por último, tendrá que determinar cómo se presentan los datos en el proceso de Azure. ¿Se sirven de forma local para cada máquina del clúster de HPC o los comparte una solución de NAS basada en la nube?
Consideraciones sobre el acceso a datos remotos
Tiene una carga de trabajo genómica que quiere ejecutar en Azure. Los datos se generan mediante secuenciadores de genes locales y se envían a un entorno local de NAS. Los investigadores en el entorno local consumen los datos para varios usos. Es posible que los investigadores también deseen consumir los resultados de la carga de trabajo de HPC que desea ejecutar en Azure. Pero algunas de ellos usan estaciones de trabajo locales para hacerlo. Supongamos también que se generan datos de genoma actualizados con regularidad. Así que tiene un intervalo limitado para ejecutar la carga de trabajo actual antes de que los datos se deban reemplazar o actualizar.
El reto es presentar los datos a Azure Compute de manera rentable y oportuna, al tiempo que se conserve el acceso local a estos datos.
Estas son algunas de las preguntas principales que debe plantearse a la hora de intentar ejecutar cargas de trabajo de HPC en Azure:
- ¿Los datos de origen se pueden trasladar a Azure sin conservar una copia local?
- ¿Los datos de resultados se pueden guardar en Azure sin conservar una copia local?
- ¿Los usuarios locales necesitan acceso simultáneo a los datos de origen o de resultados?
- En caso afirmativo, ¿pueden operar en los datos de Azure o necesitan que los datos estén almacenados de forma local?
Si los datos se deben mantener en el entorno local, ¿cuántos se deben copiar en Azure para la carga de trabajo? ¿Cuánto tiempo tiene después de procesar los datos y antes de que tenga que procesar un conjunto de datos nuevo? ¿La carga de trabajo se ejecutará en ese período de tiempo?
También debe tener en cuenta la conectividad de red con Azure. ¿Solo tiene acceso a Azure por Internet? Esa limitación podría estar bien en función del tamaño de los datos que se van a copiar o transferir y de la cantidad de tiempo entre actualizaciones. Es posible que tenga una gran cantidad de datos que copiar cada vez. Es posible que necesite una conexión de red de área extensa (WAN) a Azure que use Azure ExpressRoute, que proporcionaría más ancho de banda para copiar o transferir los datos.
Si ya tiene una conexión ExpressRoute a Azure, esta es la siguiente consideración: ¿cuál es la cantidad de conexión disponible para la operación de copia de datos? Si el vínculo está muy saturado, es posible que deba tener en cuenta la hora del día a la que transfiere los datos. O bien puede que quiera configurar una conexión ExpressRoute más grande para dar cabida a grandes transferencias de datos.
Si mueve los datos a Azure, es posible que deba tener en cuenta cómo los protegerá. Por ejemplo, puede tener un entorno NFS local que use un servicio de directorio que le ayude a ampliar los permisos a los usuarios. Si tiene previsto duplicar esta seguridad en Azure, tendrá que decidir si necesita un servicio de directorio como parte de la estructura de Azure. Pero si la carga de trabajo está restringida al clúster de HPC y los resultados se transferirán de nuevo al entorno local, es posible que pueda omitir estos requisitos.
A continuación, tendremos en cuenta los métodos para obtener acceso a los datos: almacenamiento en caché, copia y sincronización.
Diferencias entre almacenamiento en caché, copia y sincronización
Se describirán los enfoques generales que puede usar para agregar datos a Azure. Este debate sobre la transferencia de datos se centra en los datos activos, no en el archivo y la copia de seguridad de los datos.
Supongamos que los datos transferidos en nuestra explicación es el espacio de trabajo de una carga de trabajo de HPC. En un entorno de HPC de ciencias biológicas, es posible que se incluyan datos de origen como datos genómicos sin procesar, archivos binarios usados para procesarlos o datos complementarios como genomas de referencia. Se deben procesar inmediatamente al llegar o poco después. Los datos también se deben almacenar en un medio que tenga el perfil de rendimiento adecuado en cuanto a IOPS, latencia, rendimiento y costo. Por el contrario, los datos de archivo o de copia de seguridad se suelen transferir a la solución de almacenamiento menos costosa, que no está diseñada para el acceso de alto rendimiento.
Los principales métodos de transferencia de datos activos son los de almacenamiento en caché, copia y sincronización. Vamos a analizar las ventajas y desventajas de cada enfoque, empezando por la copia.
La copia de datos es el enfoque más común para mover datos. Los datos se copian de varias maneras, según la herramienta que se use.
Tenga en cuenta estos factores:
- El tamaño de los archivos.
- El número de archivos.
- La cantidad de rendimiento disponible para transferir los datos.
- La cantidad de tiempo necesario para realizar la transferencia.
Lo único que necesita es una herramienta de copia básica como cp si va a transferir una serie de archivos de tamaño razonable a un destino remoto. Probablemente querrá usar scp en lugar de cp si va a transferir datos a través de redes que no son seguras: scp proporciona cifrado a través de una conexión Secure Shell (SSH).
Hay muchos enfoques para optimizar las operaciones de copia, en función de dónde quiera copiar los datos. Si va a copiar archivos directamente en cada máquina de HPC, puede programar operaciones de copia individuales en cada nodo, por ejemplo.
Una consideración que se debe tener en cuenta a la hora de copiar datos a través de vínculos WAN es la cantidad de archivos y carpetas que se van a copiar. Si va a copiar muchos archivos pequeños, querrá combinar el uso de la copia con un archivo como tar para quitar la sobrecarga de metadatos de la conexión WAN. Copie el archivo .tar en Azure y después los datos en las máquinas.
Otro problema con la copia es el riesgo de interrupciones. Por ejemplo, si intenta copiar un archivo grande y hay errores de transmisión, el uso de cp no funcionará porque no puede reiniciar la copia desde donde se haya quedado.
Una preocupación final con la copia de datos es que puede quedar obsoleta. Por ejemplo, puede copiar un conjunto de datos en Azure. Mientras tanto, un usuario local podría haber actualizado uno o varios de los archivos de código fuente. Debe determinar un proceso para asegurarse de que está usando los datos correctos.
La sincronización de datos es una forma de copiar, pero más sofisticada. Herramientas como rsync agregan la capacidad de sincronizar los datos entre el origen y el destino, además de copiarlos del origen. rsync se asegura de que los archivos estén actualizados en función del tamaño de archivo y de las fechas de modificación. La sincronización le permite minimizar la posibilidad de usar archivos obsoletos.
rsync tiene capacidad de recuperación. Por ejemplo, si va a copiar un archivo grande y tiene problemas de transmisión, rsync puede reanudar la operación desde donde se quedó.
rsync es gratis y fácil de implementar. Tiene funcionalidades más allá de las que se describen aquí. Permite establecer un sistema de archivos sincronizado en Azure, en función de los datos locales.
rsync también tiene limitaciones que debemos mencionar. En primer lugar, la herramienta tiene un único subproceso. Solo puede ejecutar una operación a la vez y no puede paralelizar el acceso a los datos. La utilidad de copia cp también tiene un único subproceso. Por tanto, estas herramientas no están optimizadas para operaciones de copia y sincronización a gran escala que impliquen grandes cantidades de datos y un breve periodo de tiempo. Además, debe ejecutar la herramienta para sincronizar los datos. La ejecución de la herramienta agrega complejidad a su entorno, ya que debe asegurarse de que se está ejecutando según los requisitos de tiempo. Es posible que desee programar un script que incluya rsync, por ejemplo. En este enfoque debe agregar el registro del script, en caso de que haya problemas. También significa que debe vigilar los problemas. El nivel de complejidad puede aumentar rápidamente.
Si va a ejecutar una solución NAS comercial, se pueden comprar herramientas de sincronización de nivel de servidor más sofisticadas y ofrecer un rendimiento multiproceso. Después de haberlas habilitado y configurado, estas herramientas siempre funcionan y sincronizan los datos entre uno o varios orígenes y destinos.
Las operaciones de copia y sincronización transmiten copias completas de los datos de origen. La transmisión completa de archivos puede estar bien para conjuntos de datos o archivos de menor tamaño. Puede comportar retrasos significativos si los datos de origen constan de muchos archivos grandes. Cuantos más datos se transfieran, más tiempo tardará la transferencia. La sincronización garantizará que solo se agreguen archivos nuevos a la nube. Pero esos archivos deben transmitirse en su totalidad. En algunos casos, la carga de trabajo HPC podría no necesitar todo un conjunto de archivos determinado. Podría necesitar únicamente el acceso a determinadas áreas de archivos.
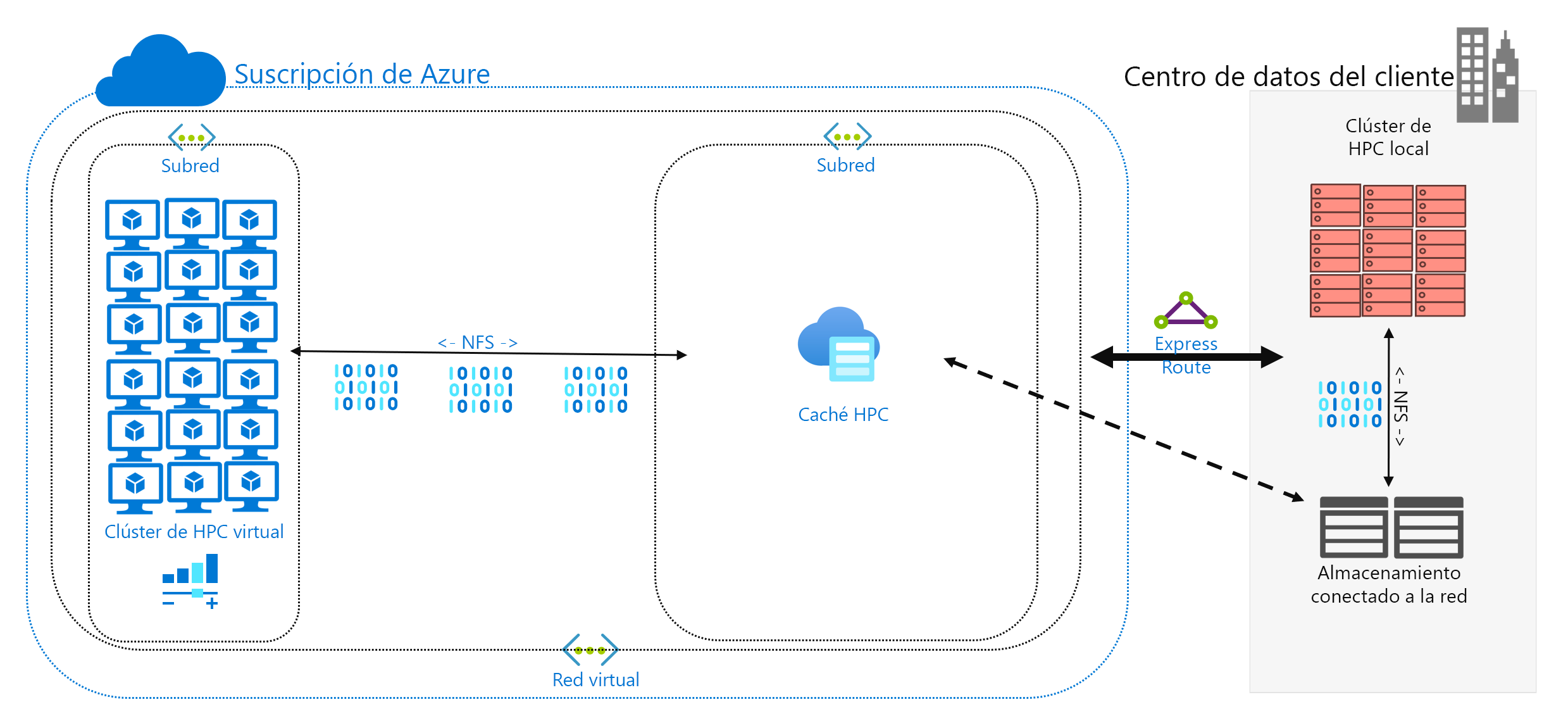
El almacenamiento en caché de los datos es un tercer enfoque para agregar datos a Azure. El almacenamiento en caché hace referencia a la recuperación y presentación de datos de archivos mediante una caché. La caché se puede ubicar en clientes locales individuales o bien puede ser una caché distribuida que atienda a todas las máquinas de HPC. Las cachés se usan normalmente para minimizar la latencia, por lo que la colocación de una caché en un límite de latencia es un enfoque óptimo para proporcionar datos. Por ejemplo, puede almacenar en caché las solicitudes de datos mediante una conexión WAN, y colocar una caché distribuida en Azure Compute que se conecta al almacenamiento local por medio de esa conexión.
En este módulo nos referimos específicamente al almacenamiento en caché de archivos, donde la propia memoria caché almacena las solicitudes de las máquinas. Recupera los datos de un entorno de almacenamiento de back-end (como un entorno NAS de NFS) y los presenta a los clientes.
La eficacia del almacenamiento en caché es doble. En primer lugar, las memorias caché no recuperan archivos completos. Una memoria caché recupera un subconjunto solicitado (o intervalo de bytes) de archivos, en lugar de recuperar archivos completos. La recuperación se basa en las solicitudes de cliente para esos intervalos de bytes. Este enfoque de recuperación minimiza las penalizaciones de rendimiento para recuperar la totalidad de un archivo grande cuando solo se necesita una pequeña sección del archivo.
En segundo lugar, las cachés optimizan el acceso reiterado de los datos solicitados con frecuencia. Una vez que un rango de bytes está en la memoria caché, las solicitudes posteriores de esos datos son rápidas. La única recuperación lenta es la primera. Puede obtener ventajas significativas a la hora de ejecutar un gran número de subprocesos o clientes de HPC que acceden a un conjunto común de archivos.
El almacenamiento en caché ofrece otra ventaja para los escenarios híbridos. Los datos se almacenan en Azure (en la memoria caché) solo de forma transitoria. Y solo se almacenan durante el funcionamiento de la carga de trabajo de HPC. Por lo tanto, puede reducir la sobrecarga logística que conlleva el movimiento de datos más concreto a Azure. Puede aislar aspectos relacionados con la seguridad y la privacidad de los datos en la caché y en las propias máquinas de HPC.
Por último, algunas soluciones de almacenamiento en caché ofrecen lo que se denomina comprobación de atributos. Como en la sincronización, la caché comprueba periódicamente los atributos del archivo que se encuentra en el origen y recupera los rangos de bytes cuando la modificación del archivo es mayor en el origen. Esta arquitectura garantiza que el entorno de HPC funcione siempre con los datos más recientes.