Autenticación y autorización del sistema de archivos
Una vez que comprenda las características generales de rendimiento y tráfico de la carga de trabajo, deberá tener en cuenta los aspectos de seguridad. Puede que los datos sean confidenciales, como en el caso de imágenes radiológicas de pacientes. Es posible que quiera restringir el acceso a los datos por diversos motivos. Es posible que quiera ofrecer a cada uno de los investigadores un "directorio particular" desde el que puedan cargar datos y realizar análisis y simulaciones de HPC.
Al seleccionar el almacenamiento de HPC en la nube, tenga en cuenta cómo se integra con la posición de seguridad actual. Comprenda los métodos por los que el sistema de archivos autentica y autoriza el acceso a los archivos. Observe si la aplicación es local o remota (o ambas), y de dónde proceden la autenticación y la autorización. Si usa un sistema de archivos compartidos remoto, deberá entender cómo controlar el acceso mediante procedimientos estándar de NAS. Por último, si ofrece espacios de trabajo únicos para los usuarios (directorios particulares), comprenda cómo asignar ese espacio.
En esta unidad, examinamos las consideraciones de seguridad y cómo afectan a la arquitectura de almacenamiento.
Introducción a la autenticación y la autorización
Autenticación: cuando se proporciona acceso a los sistemas de archivos, es necesario autenticar el solicitante mediante el uso de alguna credencial de confianza. Muchas arquitecturas de cliente/servidor emiten desafíos para esas credenciales, como las cuentas de usuario o de equipo. Estas credenciales se comprueban para asegurarse de que son válidas para el entorno. Después de la autenticación, se autoriza al solicitante (el usuario o el equipo o proceso). Los protocolos de acceso necesarios para el entorno pueden limitar la autenticación de la solución. Por ejemplo, si tiene un entorno de Windows, lo más probable es que use Bloque de mensajes del servidor (SMB) como protocolo de acceso a los archivos de red. Los requisitos de autenticación SMB no son los mismos que los de NFS.
Autorización: se puede permitir el acceso de un usuario o un equipo a un entorno, pero ¿qué nivel de acceso? Por ejemplo, el usuario A puede leer archivos en un sistema de archivos y el usuario B puede leer y escribir archivos. La autorización puede profundizar en la lectura y la escritura. Por ejemplo, el usuario C puede modificar archivos pero no crearlos en un directorio determinado.
El nivel de autorización suele expresarse como permisos para un archivo concreto. Entre ellos se incluyen los de lectura, escritura y ejecución.
Usuarios y grupos: conceder acceso a un conjunto de recursos puede resultar complicado si tiene un gran número de usuarios. También resulta complicado si pretende conceder distintos niveles de acceso a varios conjuntos de usuarios. El uso de grupos es necesario. Puede asignar un usuario a un grupo específico o a un conjunto de grupos. Después, puede autorizar el acceso a los recursos en función de la identificación de ese grupo.
En conjunto, la autenticación y la autorización representan el acceso de nivel de usuario, grupo y equipo que quiere conceder a los recursos; en este caso, a los archivos.
El sistema operativo Linux asigna un identificador de usuario (UID) a las cuentas de usuario individuales. El UID es un entero. Es lo que usa el sistema para determinar los recursos del sistema, incluidos los archivos y las carpetas, a los que puede acceder un usuario concreto.
El sistema operativo Linux usa identificadores de grupo (GID) para las asignaciones de grupos. Un usuario se asocia a un único grupo primario. Los usuarios se pueden asociar prácticamente a cualquier número de asignaciones de grupos adicionales, hasta 65 536 en la mayoría de los sistemas Linux modernos.
Autenticación y autorización locales y remotas
La autenticación y la autorización locales hacen referencia al acceso de un sistema de archivos local mediante una cuenta de usuario o equipo que también es local en el equipo. Por ejemplo, se puede crear una cuenta de usuario y después concederle acceso al directorio /data ubicado en el sistema de archivos local. Esa cuenta de usuario es local, como lo es cualquier concesión de acceso al directorio. También puedo usar la asignación de grupos para controlar el acceso. La combinación de autorización de usuario y de grupos concede a los usuarios permisos efectivos sobre un archivo o una carpeta.
Si examina la salida típica de un comando del directorio ls -al, verá algo parecido a esto:
drwxr-xr-x 4 root root 4096 Dec 31 19:43.
drwxr-xr-x 13 root root 4096 Dec 11 05:53 ..
drwxr-xr-x 6 root root 4096 Dec 31 19:43 microsoft
drwxr-xr-x 8 root root 4096 Dec 31 19:43 omi
-rw-r--r-- 1 root root 0 Jan 21 15:10 test.txt
Los caracteres drwxr-xr-x representan el nivel de acceso autorizado que tienen los usuarios y grupos al archivo o directorio. La d indica que la entrada es un directorio (si el primer valor es -, la entrada es una entrada de archivo). Los caracteres restantes representan la autorización del grupo de permisos de lectura (r), escritura (w) y ejecución (x). Los tres primeros valores indican el "propietario" del archivo o directorio. Los tres valores siguientes indican los permisos de grupo asignados al archivo o directorio. Los tres últimos valores indican los permisos permitidos para los demás usuarios del sistema.
Este es un ejemplo:
-rw-r--r-- 1 root root 0 Jan 21 15:10 test.txt
-indica que este recurso es un archivo.rw-indica que el propietario tiene permisos de lectura y escritura.r--indica que el grupo asignado solo tiene permisos de lectura.r--indica que los usuarios restantes solo tienen permisos de lectura.- Observe también que el usuario propietario y el grupo asignado se representan por las dos columnas
root.
Un UID y los GID principales y complementarios representan un usuario autenticado en un equipo local. Estos valores son locales para el equipo. ¿Qué ocurre si tiene 5 o 50 equipos? Tendrá que replicar las asignaciones de UID y GID en cada uno de esos equipos. El nivel de complejidad de la administración de usuarios aumenta, al igual que la posibilidad de conceder acceso a archivos o carpetas al usuario equivocado.
Acceso remoto a archivos mediante NFS
La asignación de UID y GID local funciona correctamente si se ejecuta todo como una única asignación de usuario o grupo. ¿Qué ocurre si varias partes interesadas consumen el clúster HPC que está ejecutando, y cada parte interesada tiene datos confidenciales y varios consumidores de los datos?
La búsqueda de datos en un servidor de archivos o en un entorno NAS permite el acceso remoto de los datos. Este enfoque ayuda a reducir el costo del disco local, garantiza que los datos estén actualizados para todos los usuarios y reduce la administración general de usuarios y grupos.
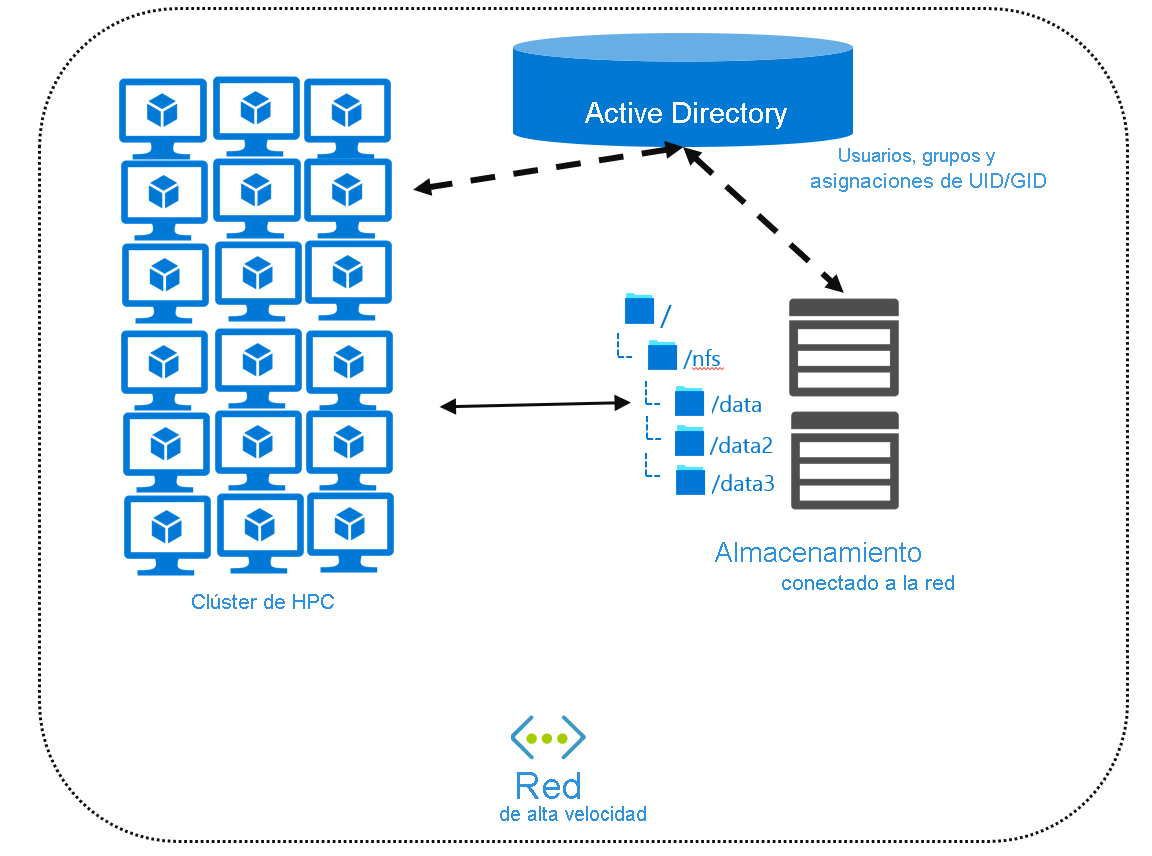
Si localiza los archivos de forma centralizada, es posible que necesite un servicio de directorio que contenga la configuración de usuario y de grupo. Los servicios de directorio, como Active Directory o el Protocolo ligero de acceso a directorios (LDAP), permiten crear una asignación de usuario o grupo que después podrán usar todos los sistemas remotos. Configure los equipos remotos y el entorno de NAS como clientes del servicio de directorio. También puede usar asignaciones de Active Directory entre las cuentas de usuario de Windows y una combinación específica de UID y GID.
El método típico para acceder a los archivos de forma remota consiste en usar un sistema de archivos de red como NFS o SMB, o bien un sistema de archivos en paralelo como Lustre. Estos protocolos definen la API de cliente y servidor para acceder a los datos. En la unidad "Consideraciones sobre el rendimiento del sistema de archivos" se han analizado las operaciones de NFS. En la siguiente unidad hablaremos ampliamente del uso de NFS.
Nota:
Un servicio de directorio no es necesario cuando se usa NFS. Pero si no usa ninguno, la administración de UID y GID seguirá siendo difícil si tiene un gran número de usuarios y sistemas.
Directorios principales
Imagine que tiene un entorno de HPC que usan varios investigadores, pero sus datos únicos deben mantenerse separados. Digamos que esos investigadores modifican y agregan continuamente sus propios datos. Proporcionar a los investigadores sus propios directorios de origen es una manera eficaz de separar sus datos.
Cada investigador administraría los permisos que hay dentro del directorio principal, por lo que podrían colaborar si lo desearan.
Uno de los principales desafíos de este entorno es el espacio de almacenamiento. Imagine que tiene un entorno NAS de 500 TB. ¿Qué impide que un investigador lo use todo?
Puede asignar una cuota a un directorio concreto. La cuota refleja la cantidad máxima de datos permitidos. Una vez alcanzada la cuota, puede rechazar más datos o advertir a los administradores de que el investigador ha superado el límite. Por ejemplo, si tiene un sistema NAS, puede asignar una cuota a cada investigador. Y si aísla el acceso de los investigadores al directorio personal, resulta fácil configurar y supervisar su uso.