Opciones de configuración de HDInsight
HDInsight tiene una amplia gama de tecnologías de OSS integradas que se pueden usar para abordar escenarios de datos de transmisión y por lotes, que son términos que se definen en las arquitecturas Lambda. En este modelo de arquitectura, hay una ruta de los datos activa y otra inactiva. La ruta de los datos activa la generan en tiempo real los dispositivos, los sensores o las aplicaciones y el análisis de los datos se realiza casi en tiempo real. Esto suele conocerse como "datos de transmisión". Una ruta de datos inactiva es la que se produce cuando los datos se mueven por lotes, normalmente desde otros almacenes de datos. Son los denominados "datos por lotes".
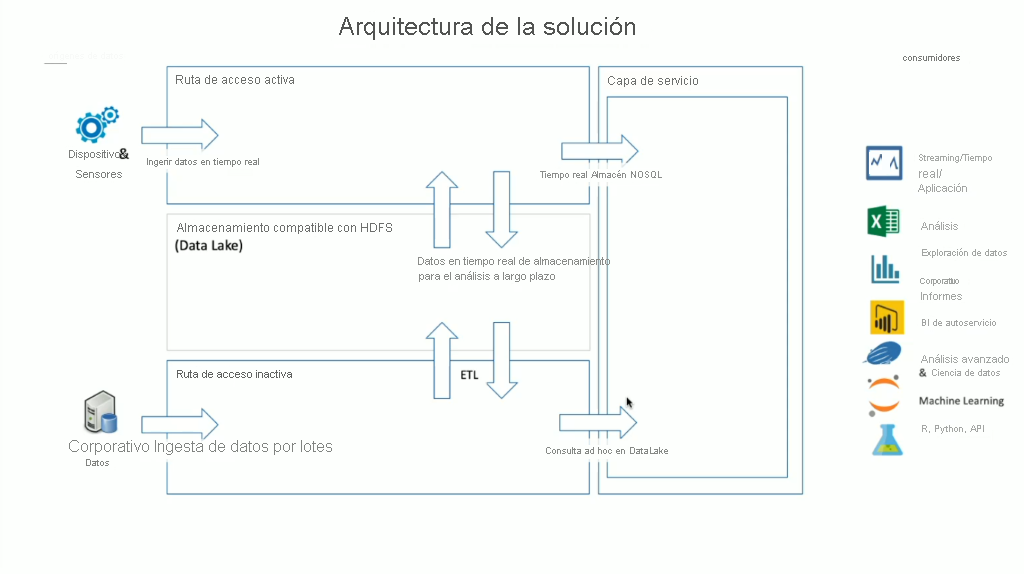
Al implementar HDInsight, el almacenamiento de datos se mantiene dentro de una Sistema de archivos distribuido de Hadoop (HDFS) admitido. En Azure, se suele usar Data Lake Gen2 como almacén de datos, ya que es compatible con HDFS. Los datos de la ruta activa e inactiva después del procesamiento se almacenan en un almacén de datos centralizado llamado lago de datos. El propio lago de datos se puede compartimentar para almacenar los datos en diferentes compartimientos, que se pueden definir según el estado de los datos (zona de aterrizaje, zona de transformación, etc.), los requisitos de acceso (activo, semiactivo e inactivo) y los grupos de negocios. La capa de servicio es el compartimiento final del lago de datos que contiene los datos en un formato listo para el consumo por parte de varios tipos de consumidores.
Es importante tener en cuenta que el aspecto de proceso de HDInsight se encarga del procesamiento de datos de transmisión o por lotes, y que puede variar en función del tipo de clúster que se seleccione al aprovisionar un clúster de HDInsight. HDInsight ofrece los servicios en opciones de clúster individuales, como se muestra en la tabla siguiente.
| Tipo de clúster | Descripción |
|---|---|
| Apache Hadoop | Un marco que usa HDFS y un modelo de programación de MapReduce simple para procesar y analizar datos por lotes. |
| Spark de Apache | plataforma de procesamiento paralelo de código abierto que admite el procesamiento en memoria para mejorar el rendimiento de las aplicaciones de análisis de macrodatos. |
| HBase | base de datos NoSQL en Hadoop que proporciona acceso aleatorio y coherencia fuerte para grandes cantidades de datos no estructurados y semiestructurados; potencialmente miles de millones de filas multiplicadas por millones de columnas. |
| Consulta interactiva de Apache | almacenamiento en caché en memoria para realizar consultas de Hive interactivas y más rápidas. |
| Apache Kafka | una plataforma de código abierto que se usa para crear canalizaciones y aplicaciones de datos de streaming. Kafka también proporciona funcionalidad de cola de mensajes que le permite publicar flujos de datos y suscribirse a ellos. |
Por lo tanto, es importante seleccionar el tipo de clúster correcto que se adapte al caso empresarial que intenta resolver. Independientemente del tipo de clúster seleccionado, también se agregan otros componentes de código abierto en el clúster para proporcionar funcionalidades adicionales, entre las que se incluyen las siguientes:
Administración de Hadoop
HCatalog: una capa de administración de almacenamiento y tablas para Hadoop
Apache Ambari: facilita la administración y la supervisión de un clúster de Apache Hadoop
Apache Oozie: un sistema de programación de flujos de trabajo para administrar trabajos de Apache Hadoop
Apache Hadoop YARN: se ocupa de la administración de los recursos y de la programación y la supervisión de los trabajos
Apache ZooKeeper: un servicio centralizado para mantener la información de configuración, asignar nombres, proporcionar sincronización distribuida y ofrecer servicios de grupo.
Procesamiento de datos
Apache Hadoop MapReduce: un marco para escribir fácilmente aplicaciones que procesan grandes cantidades de datos
Apache Tez: un marco de aplicación para procesar datos
Apache Hive: facilita la administración de grandes conjuntos de datos que residen en el almacenamiento distribuido mediante SQL
Análisis de datos
Apache Pig: proporciona una capa de abstracción sobre MapReduce para analizar grandes conjuntos de datos
Apache Phoenix: habilita el análisis operativo y de OLTP en Hadoop
Apache Mahout: un marco de álgebra con el que puede crear algoritmos propios
Nota:
En el momento de escribir este documento, Azure Data Lake Gen1 y Azure Blob Storage son capas de almacenamiento de datos admitidas para HDInsight. Debería migrar estos datos a Azure Data Lake Gen2, ya que es la plataforma de almacenamiento recomendada para Spark y Hadoop, así como la opción predeterminada para HBase.