Trabajar con almacenes de lago de Microsoft Fabric
Ahora que comprende las funcionalidades principales de un almacén de lago de Microsoft Fabric, vamos a explorar cómo trabajar con uno.
Creación y exploración de un almacén de lago
Al crear un nuevo almacén de lago, tiene tres elementos de datos diferentes creados automáticamente en el área de trabajo.
- El almacén de lago contiene accesos directos, carpetas, archivos y tablas.
- El Modelo semántico (valor predeterminado) proporciona un origen de datos sencillo para los desarrolladores de informes de Power BI.
- El punto de conexión de SQL Analytics permite el acceso de solo lectura a los datos de consulta con SQL.
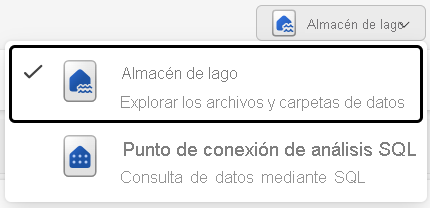
Puede trabajar con los datos del almacén de lago en dos modos:
- El almacén de lago le permite agregar e interactuar con tablas, archivos y carpetas en el almacén de lago.
- El punto de conexión de análisis SQL permite usar SQL para consultar las tablas del almacén de lago y administrar su modelo semántico relacional.
Ingesta de datos en un Lakehouse
La ingesta de datos en Lakehouse es el primer paso del proceso de ETL. Usa cualquiera de los métodos siguientes para incorporar datos a Lakehouse.
- Carga: carga archivos locales.
- Flujos de datos Gen2: Importación y transformación de datos mediante Power Query.
- Cuadernos: usa Apache Spark para ingerir, transformar y cargar datos.
- Canalizaciones de fábrica de datos: usa la actividad Copiar datos.
Estos datos se pueden cargar directamente en archivos o tablas. Considera el patrón de carga de datos al ingerir datos para determinar si debes cargar todos los datos sin procesar como archivos antes de procesar o usar tablas de almacenamiento provisional.
Las definiciones de trabajos de Spark también se pueden usar para enviar trabajos por lotes/streaming a clústeres de Spark. Al cargar los archivos binarios de la salida de compilación de diferentes lenguajes (por ejemplo, .jar de Java), puede aplicar diferentes lógicas de transformación a los datos alojados en un lago. Además del archivo binario, puede personalizar aún más el comportamiento del trabajo cargando bibliotecas adicionales y argumentos de línea de comandos.
Nota:
Para más información, consulte la documentación Creación de una definición de trabajo de Apache Spark.
Acceso a datos mediante accesos directos
Otra manera de acceder y usar datos en Fabric es usar accesos directos. Los accesos directos permiten integrar datos en el almacén de lago mientras se mantienen almacenados en el almacenamiento externo.
Los accesos directos son útiles cuando se necesitan datos de origen que se encuentran en una cuenta de almacenamiento diferente o incluso en un proveedor de nube diferente. Dentro de Lakehouse, puedes crear accesos directos que apunten a diferentes cuentas de almacenamiento y otros elementos de Fabric, como almacenes de datos, bases de datos KQL y otras instancias de Lakehouse.
OneLake administra todos los permisos y credenciales de los datos de origen. Al acceder a los datos a través de un acceso directo a otra ubicación de OneLake, la identidad del usuario que realiza la llamada se usará para autorizar el acceso a los datos en la ruta de acceso de destino del acceso directo. Este usuario debe tener permisos en la ubicación de destino para leer los datos.
Los accesos directos se pueden crear en las bases de datos de almacén de lago y KQL, y aparecen como una carpeta en el lago. Esto permite que Spark, SQL, Inteligencia en tiempo real y Analysis Services usen accesos directos al consultar datos.
Nota:
Para obtener más información sobre cómo usar accesos directos, consulte la documentación de accesos directos de OneLake en la documentación de Microsoft Fabric.