Exploración del almacén de lago de Microsoft Fabric
Un lakehouse se presenta como una base de datos y se crea encima de un lago de datos mediante tablas de formato Delta. Los almacenes de lago combinan las funcionalidades analíticas basadas en SQL de un almacenamiento de datos relacional y la flexibilidad y escalabilidad de un lago de datos. Los almacenes de lago almacenan todos los formatos de datos y se pueden usar con diversas herramientas de análisis y lenguajes de programación. Como soluciones basadas en la nube, los almacenes de lago se pueden escalar automáticamente y proporcionar alta disponibilidad y recuperación ante desastres.
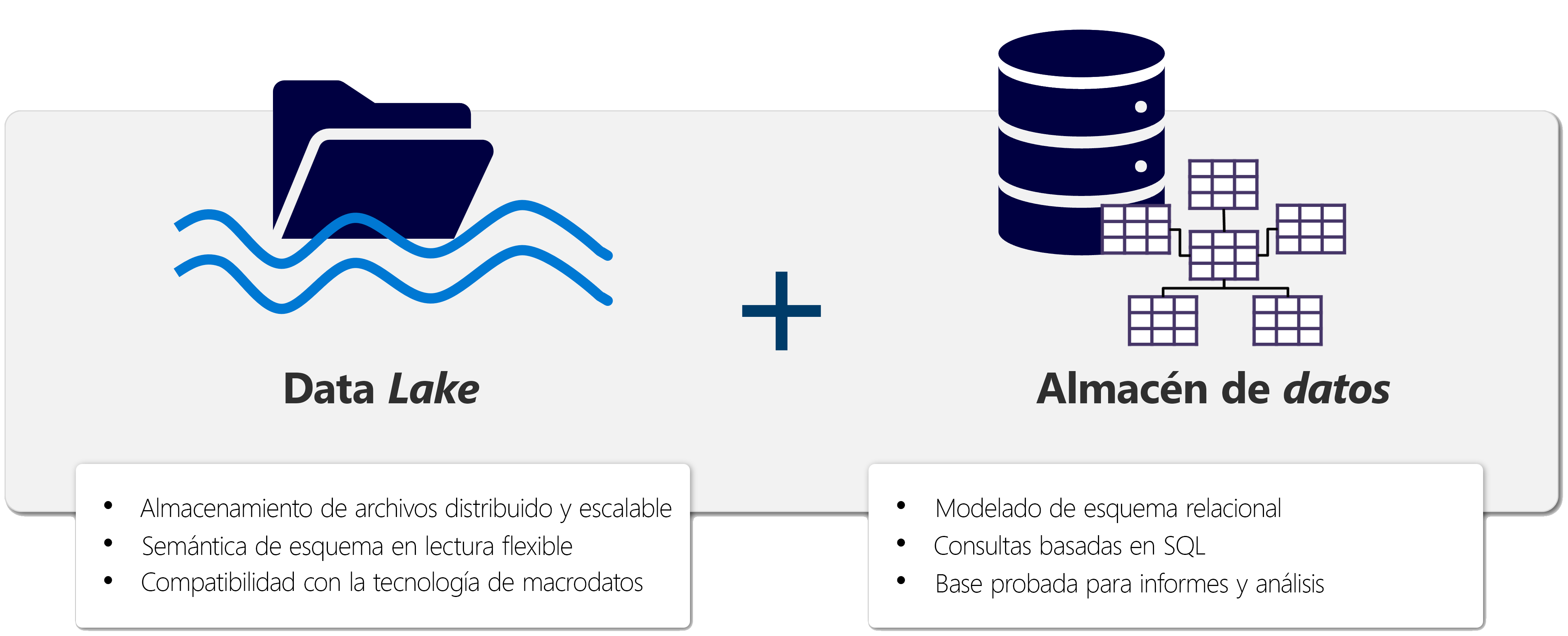
A continuación se indican algunas ventajas de un almacén de lago:
- Los almacenes de lago usan motores Spark y SQL para procesar datos a gran escala y admitir el aprendizaje automático o el análisis de modelado predictivo.
- Los datos de un almacén de lago se organizan en un formato de lectura de esquema, lo que significa que se define el esquema según sea necesario en lugar de tener un esquema predefinido.
- Los almacenes de lago admiten transacciones ACID (Atomicidad, Coherencia, Aislamiento, Durabilidad) a través de tablas con formato de Delta Lake para conseguir coherencia e integridad en los datos.
- Los almacenes de lago son una única ubicación para que los ingenieros de datos, los científicos de datos y los analistas de datos accedan a los datos y los usen.
Una instancia de Lakehouse es una excelente opción si desea una solución de análisis escalable que mantenga la coherencia de los datos. Es importante evaluar sus requisitos específicos para determinar qué solución es la mejor opción.
Carga de datos en una instancia de LakeHouse
Los almacenes de lago de datos de Fabric son un elemento central para la solución de análisis. Puede seguir el proceso de ETL (extracción, transformación, carga) para ingerir y transformar datos antes de cargarlos en el almacén de lago de datos.
Puede ingerir datos en muchos formatos comunes de varios orígenes, incluidos archivos locales, bases de datos o API. También puede crear accesos directos de Fabric a los datos de orígenes externos, como Azure Data Lake Store Gen2 o OneLake. Use el explorador de almacén de lago de datos para examinar archivos, carpetas, accesos directos y tablas y ver su contenido dentro de la plataforma Fabric.
Los datos ingeridos se pueden transformar y cargar mediante Apache Spark con cuadernos o flujos de datos Gen2. Use canalizaciones de Data Factory para organizar las diferentes actividades de ETL y colocar los datos preparados en el almacén de lago de datos.
Nota:
Los flujos de datos Gen2 se basan en Power Query, una herramienta familiar para los analistas de datos que usa Excel o Power BI que proporciona una representación visual de las transformaciones como alternativa a la programación tradicional.
Puede usar su almacén de lago de datos por muchas razones, entre las que se incluyen:
- Análisis mediante SQL.
- Entrenar modelos de Machine Learning.
- Realizar análisis en datos en tiempo real.
- Desarrollar informes en Power BI.
Protección de un almacén de lago de datos
El acceso al almacén de lago de datos se administra a través del área de trabajo o el uso compartido a nivel de elemento. Los roles de áreas de trabajo deben usarse para colaboradores porque estos roles conceden acceso a todos los elementos del área de trabajo. El uso compartido a nivel de elemento se usa mejor para conceder acceso a necesidades de solo lectura, como el análisis o el desarrollo de informes de Power BI.
Los almacenes de lago de datos de Fabric también admiten características de gobernanza de datos, incluidas las etiquetas de confidencialidad, y se puede ampliar mediante Microsoft Purview con el inquilino de Fabric.
Nota:
Para obtener más información, consulte la documentación de Seguridad en Microsoft Fabric.