Descripción de los almacenamientos de datos en Fabric
El almacén de lago de Fabric es una colección de archivos, carpetas, tablas y accesos directos que actúan como una base de datos sobre un lago de datos. Lo usa el motor de Spark y el motor de SQL para el procesamiento de macrodatos y tiene características para las transacciones ACID al usar las tablas con formato Delta de código abierto.
La experiencia de almacenamiento de datos de Fabric permite realizar la transición desde la vista de lago del almacén de lago (que admite la ingeniería de datos y Apache Spark) a las experiencias SQL que proporcionaría un almacenamiento de datos tradicional. El almacén de lago permite leer tablas y usar el punto de conexión de análisis SQL, mientras que el almacenamiento de datos permite manipular los datos.
En la experiencia de almacenamiento de datos, modelará los datos mediante tablas y vistas, ejecutará T-SQL para consultar datos en el almacenamiento de datos y el almacén de lago, usará T-SQL para realizar operaciones DML en datos dentro del almacenamiento de datos y servirá capas de informes como Power BI.
Ahora que comprende los principios arquitectónicos básicos de un esquema de almacenamiento de datos relacional, vamos a explorar cómo crear un almacenamiento de datos.
Descripción de un almacenamiento de datos en Fabric
En la experiencia de almacenamiento de datos de Fabric, puede crear una capa relacional sobre datos físicos en el almacén de lago y exponerla a herramientas de análisis e informes. Puede crear el almacenamiento de datos directamente en Fabric desde el centro de creación o dentro de un área de trabajo. Después de crear un almacén vacío, puede agregar objetos a él.
Una vez creado el almacenamiento, puede crear tablas mediante T-SQL directamente en la interfaz de Fabric.
Ingesta de datos en el almacenamiento de datos
Hay varias maneras de ingerir datos en un almacenamiento de datos de Fabric, como las canalizaciones, los flujos de datos, las consultas entre bases de datos y el comando COPY INTO. Después de la ingesta, los datos están disponibles para que varios grupos empresariales los analicen, que pueden usar características como las consultas entre bases de datos y el uso compartido para acceder a ellos.
Crear tablas.
Para crear una tabla en el almacenamiento de datos, puede usar SQL Server Management Studio (SSMS) u otro cliente SQL para conectarse al almacenamiento de datos y ejecutar una instrucción CREATE TABLE. También puede crear tablas directamente en la UI de Fabric.
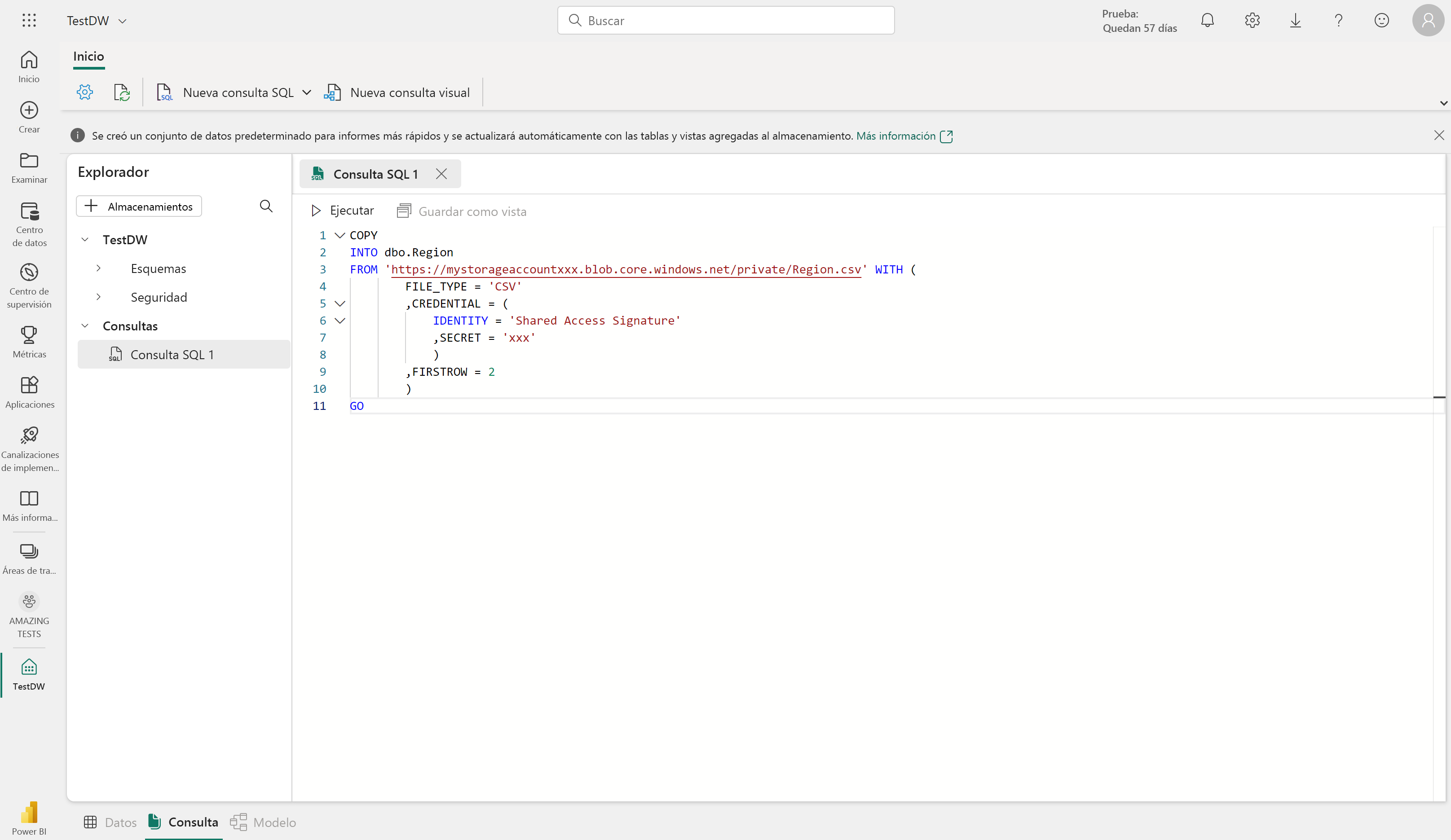
Puede copiar datos desde una ubicación externa en una tabla del almacenamiento de datos mediante la sintaxis COPY INTO. Por ejemplo:
COPY INTO dbo.Region
FROM 'https://mystorageaccountxxx.blob.core.windows.net/private/Region.csv' WITH (
FILE_TYPE = 'CSV'
,CREDENTIAL = (
IDENTITY = 'Shared Access Signature'
, SECRET = 'xxx'
)
,FIRSTROW = 2
)
GO
Esta consulta SQL carga datos de un archivo CSV almacenado en Azure Blob Storage en una tabla denominada "Región" en el almacenamiento de datos de Fabric.
Clonación de tabla
Puede crear clones de tabla de copia cero con costes mínimos de almacenamiento en un almacenamiento de datos. Estos clones son básicamente réplicas de tablas creadas al copiar los metadatos mientras se sigue haciendo referencia a los mismos archivos de datos en OneLake. Esto significa que los datos subyacentes almacenados como archivos de Parquet no están duplicados, lo que ayuda a ahorrar costos de almacenamiento.
Los clones de tabla son especialmente útiles en varios escenarios.
- Desarrollo y pruebas: Los clones permiten a los desarrolladores y evaluadores crear copias de tablas en entornos inferiores, lo que facilita el desarrollo, la depuración, las pruebas y los procesos de validación.
- Recuperación de datos: En caso de que se produzcan errores en la versión o daños en los datos, los clones de tabla pueden conservar el estado anterior de los datos, lo que permite la recuperación de datos.
- Informes históricos: Ayudan a crear informes históricos que reflejan el estado de los datos en momentos específicos y conservan los datos en hitos empresariales específicos.
Puede crear un clon de tabla mediante el comando CREATE TABLE AS CLONE OF T-SQL.
Para más información sobre los clones de tabla, consulte Tutorial: Clonar una tabla mediante T-SQL en Microsoft Fabric.
Consideraciones sobre las tablas
Después de crear tablas en un almacenamiento de datos, es importante tener en cuenta el proceso de carga de datos en esas tablas. Un enfoque común consiste en usar tablas de almacenamiento provisional. En Fabric, puede usar comandos de T-SQL para cargar datos de archivos en tablas de almacenamiento provisional en el almacenamiento de datos.
Las tablas de almacenamiento provisional son tablas temporales que se pueden usar para realizar la limpieza de datos, las transformaciones de datos y la validación de datos. También puede usar tablas de almacenamiento provisional para cargar datos desde varios orígenes en una sola tabla de destino.
Normalmente, la carga de datos se realiza como un proceso por lotes periódico en el que se coordinan las inserciones y actualizaciones en el almacenamiento de datos a intervalos regulares (por ejemplo, diaria, semanal o mensualmente).
Generalmente, debe implementar un proceso de carga de almacenamiento de datos que realice las tareas en el orden siguiente:
- Ingerir los nuevos datos que se van a cargar en un lago de datos, aplicando la limpieza previa a la carga o las transformaciones según sea necesario.
- Cargar los datos de los archivos en tablas de almacenamiento provisional en el almacenamiento de datos relacional.
- Cargar las tablas de dimensiones de los datos de dimensión de las tablas de almacenamiento provisional, actualizando las filas existentes o insertando nuevas filas y generando valores de clave suplente según sea necesario.
- Cargar las tablas de hechos a partir de los datos de hechos de las tablas de almacenamiento provisional, buscando las claves suplentes adecuadas para las dimensiones relacionadas.
- Realizar la optimización posterior a la carga mediante la actualización de los índices y las estadísticas de distribución de tablas.
Si tiene tablas en almacenes de lago y quiere poder consultarla en el almacenamiento, pero no realizar cambios, con un almacenamiento de datos de Fabric, no tiene que copiar datos desde el almacén de lago al almacenamiento de datos. Puede consultar datos del almacén de lago directamente desde el almacenamiento de datos mediante consultas entre bases de datos.
Importante
Actualmente, trabajar con tablas en el almacenamiento de datos de Fabric tiene algunas limitaciones. Consulte Tablas en el almacenamiento de datos en Microsoft Fabric para obtener más información.