Exploración y procesamiento de datos con Microsoft Fabric
Los datos son la piedra angular de la ciencia de datos, especialmente cuando el objetivo es entrenar un modelo de Machine Learning para lograr la inteligencia artificial. Normalmente, los modelos presentan un rendimiento mejorado a medida que aumenta el tamaño del conjunto de datos de entrenamiento. Además de la cantidad de datos, su calidad es igualmente crucial.
Para garantizar la calidad y la cantidad de los datos, merece la pena usar los motores sólidos de procesamiento y ingesta de datos de Microsoft Fabric. Tiene la flexibilidad de optar por un enfoque de poco código u orientado al código al establecer las canalizaciones de ingesta, exploración y transformación de datos esenciales.
Ingesta de los datos en Microsoft Fabric
Para trabajar con datos en Microsoft Fabric, primero debe realizar su ingesta. Puede realizar la ingesta de datos desde varios orígenes, tanto locales como en la nube. Por ejemplo, puede ingerir datos desde un archivo CSV almacenado en el equipo local o en una instancia de Azure Data Lake Storage (Gen2).
Sugerencia
Obtenga más información sobre cómo ingerir y organizar datos de varios orígenes con Microsoft Fabric.
Después de conectarse a un origen de datos, puede guardar los datos en un lago de datos de Microsoft Fabric. Puede usar lagos de datos como ubicación central para almacenar cualquier archivo estructurado, semiestructurado y no estructurado. Después, puede conectarse fácilmente al lago de datos siempre que quiera acceder a los datos para su exploración o transformación.
Exploración y transformación de los datos
Como científico de datos, es posible que esté más familiarizado con la escritura y ejecución de código en cuadernos. Microsoft Fabric ofrece una experiencia de cuaderno conocida, con tecnología de proceso de Spark.
Apache Spark es un marco de procesamiento paralelo de código abierto para el procesamiento y el análisis de datos a gran escala.
Los cuadernos se adjuntan automáticamente al proceso de Spark. Al ejecutar una celda en un cuaderno por primera vez, se inicia una nueva sesión de Spark. La sesión persiste al ejecutar celdas posteriores. La sesión de Spark se detendrá automáticamente después de algún tiempo de inactividad para ahorrar costos. También puede detener la sesión manualmente.
Al trabajar en un cuaderno, puede elegir el lenguaje que quiere usar. En el caso de las cargas de trabajo de ciencia de datos, es probable que trabaje con PySpark (Python) o SparkR (R).
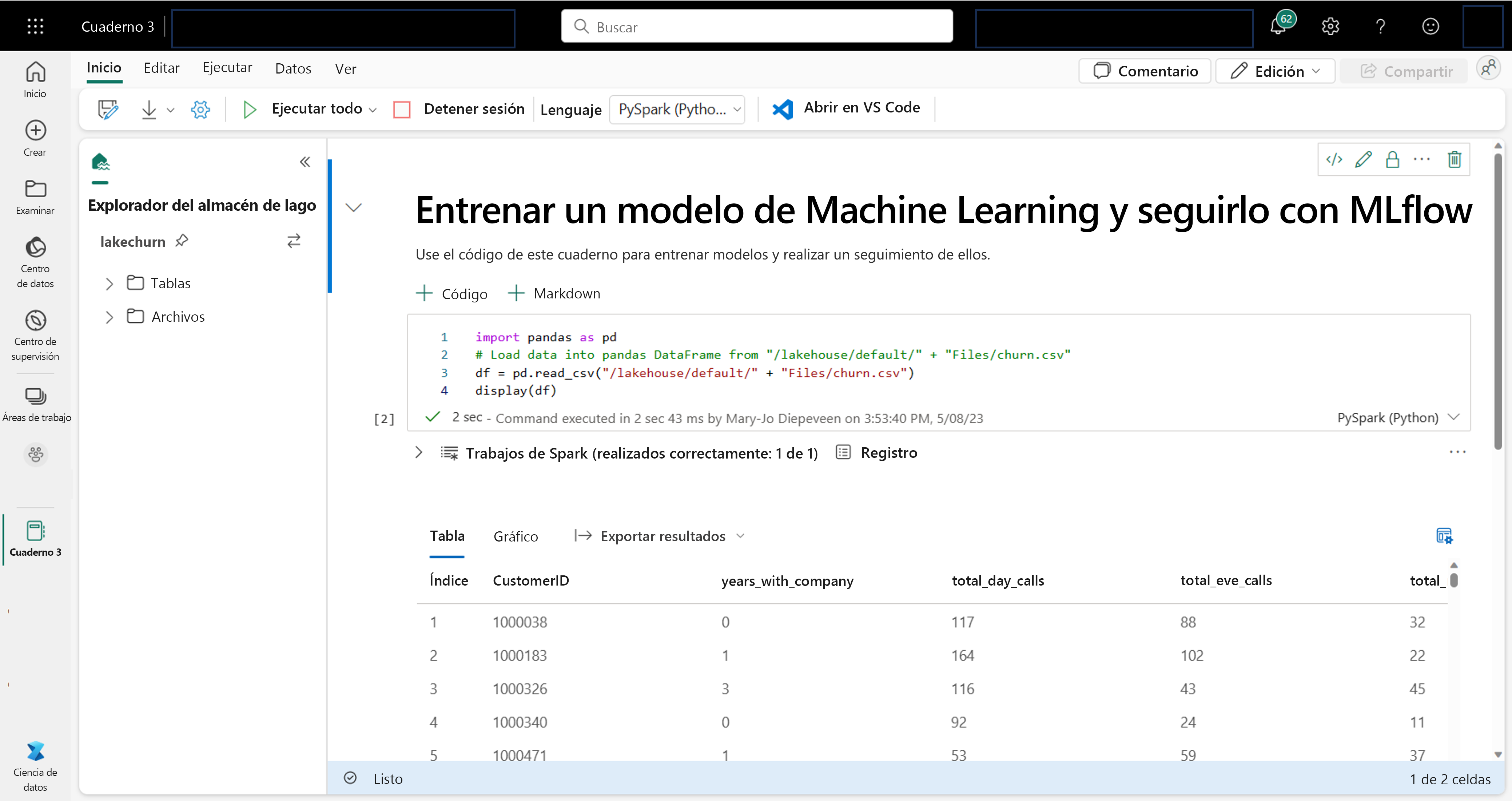
En el cuaderno, puede explorar los datos mediante la biblioteca que prefiera, o bien con cualquiera de las opciones de visualización integradas. Si es necesario, puede transformar los datos y guardar los datos procesados si los vuelve a escribir en el almacén de lago.
Preparación de los datos con Data Wrangler
Para ayudarle a explorar y transformar los datos más rápidamente, Microsoft Fabric ofrece Data Wrangler, fácil de usar.
Después de iniciar Data Wrangler, obtendrá una introducción general de los datos con los que trabaja. Puede ver las estadísticas de resumen de los datos para buscar cualquier problema, como valores que faltan.
Para limpiar los datos, puede elegir cualquiera de las operaciones integradas de limpieza de datos. Al seleccionar una operación, se genera automáticamente una vista previa del resultado y el código asociado. Cuando haya seleccionado todas las operaciones necesarias, puede exportar las transformaciones al código y ejecutarlo en los datos.