Personalización del comportamiento del modelo para la puntuación por lotes
Una vez que haya entrenado un modelo, querrá usarlo para generar nuevas predicciones. Imagine, por ejemplo, que entrenó un modelo de previsión. Cada semana, aplica el modelo a los datos históricos de ventas para generar la previsión de ventas de la semana siguiente.
En Microsoft Fabric, es posible usar un modelo guardado y aplicarlo a los datos para generar y guardar las nuevas predicciones. El modelo toma los nuevos datos como entrada, realiza las transformaciones necesarias y genera las predicciones.
La información sobre las entradas y salidas esperadas del modelo se almacena en los artefactos del modelo que se crean durante el entrenamiento del modelo. Al realizar el seguimiento del modelo con MLflow, es posible cambiar el comportamiento esperado del mismo durante la puntuación por lotes.
Sugerencia
Obtenga más información sobre entrenamiento y seguimiento de modelos de aprendizaje automático con MLflow en Microsoft Fabric.
Personalización del comportamiento del modelo
Para aplicar un modelo entrenado a nuevos datos, el modelo debe saber cuál es la forma de la entrada de datos esperada y cómo generar las predicciones. La información sobre las entradas y salidas esperadas se almacena, junto con otros metadatos, en el archivo MLmodel.
Al realizar un seguimiento de un modelo de Machine Learning con MLflow en Microsoft Fabric, se deducen las entradas y salidas esperadas del modelo. Con el registro automático de MLflow, la carpeta model y el archivo MLmodel se crean automáticamente.
Siempre que quiera cambiar las entradas o salidas esperadas del modelo, cambie cómo se crea el archivo MLmodel al realizar el seguimiento del modelo en el área de trabajo de Microsoft Fabric. El esquema de entrada y salida de datos se define en la firma del modelo.
Creación de la firma del modelo
Después de realizar el seguimiento de un modelo con MLflow durante el entrenamiento del modelo, podrá encontrar el archivo MLmodel en la carpeta model, almacenado con la ejecución del experimento:
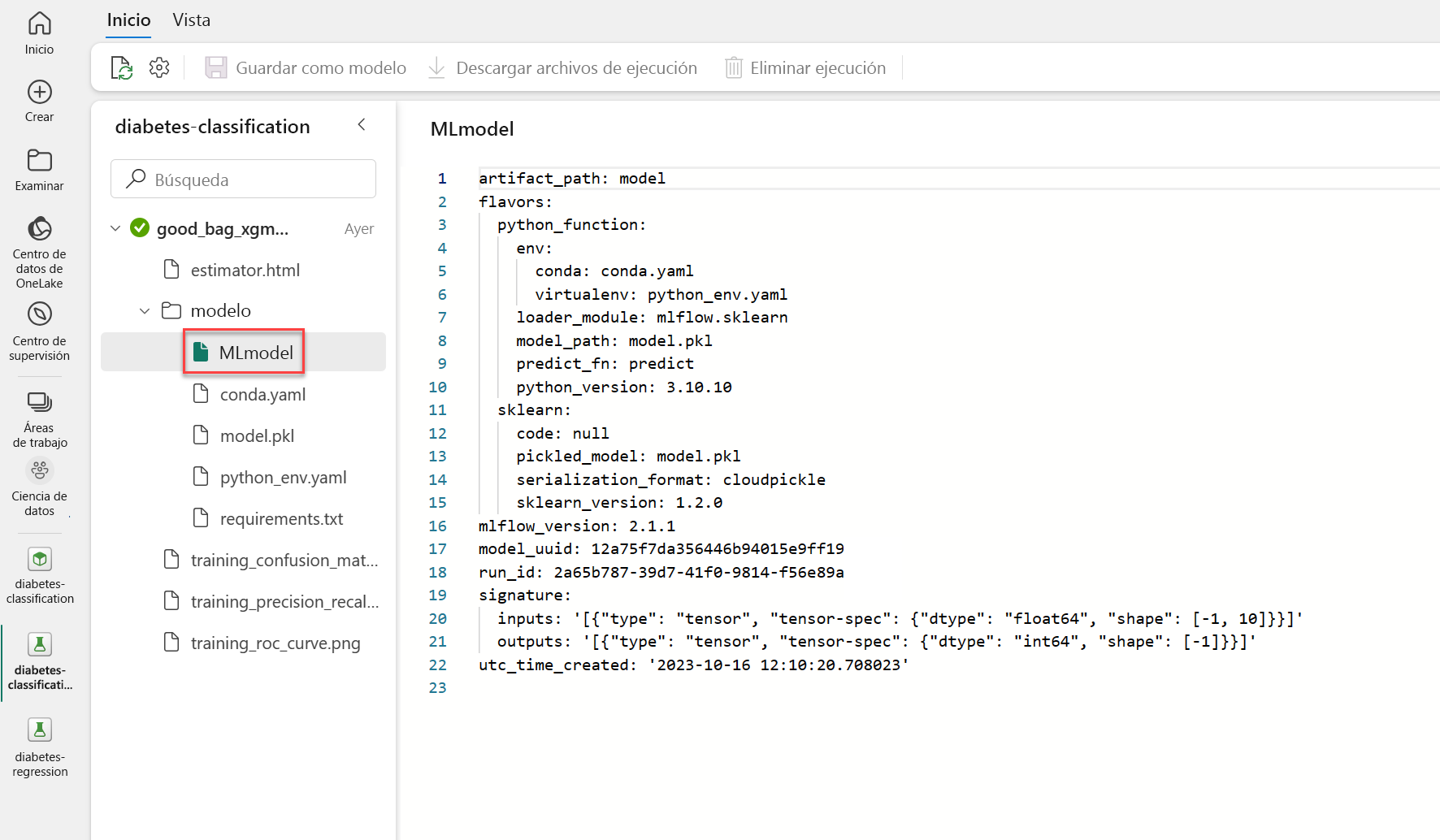
A medida que explore el archivo de ejemplo MLmodel, observe que las entradas y salidas esperadas se definen como tensores. Cuando se aplique el modelo a través del asistente, solo se mostrará una columna de entrada, ya que se esperará que los datos de entrada sean una matriz.
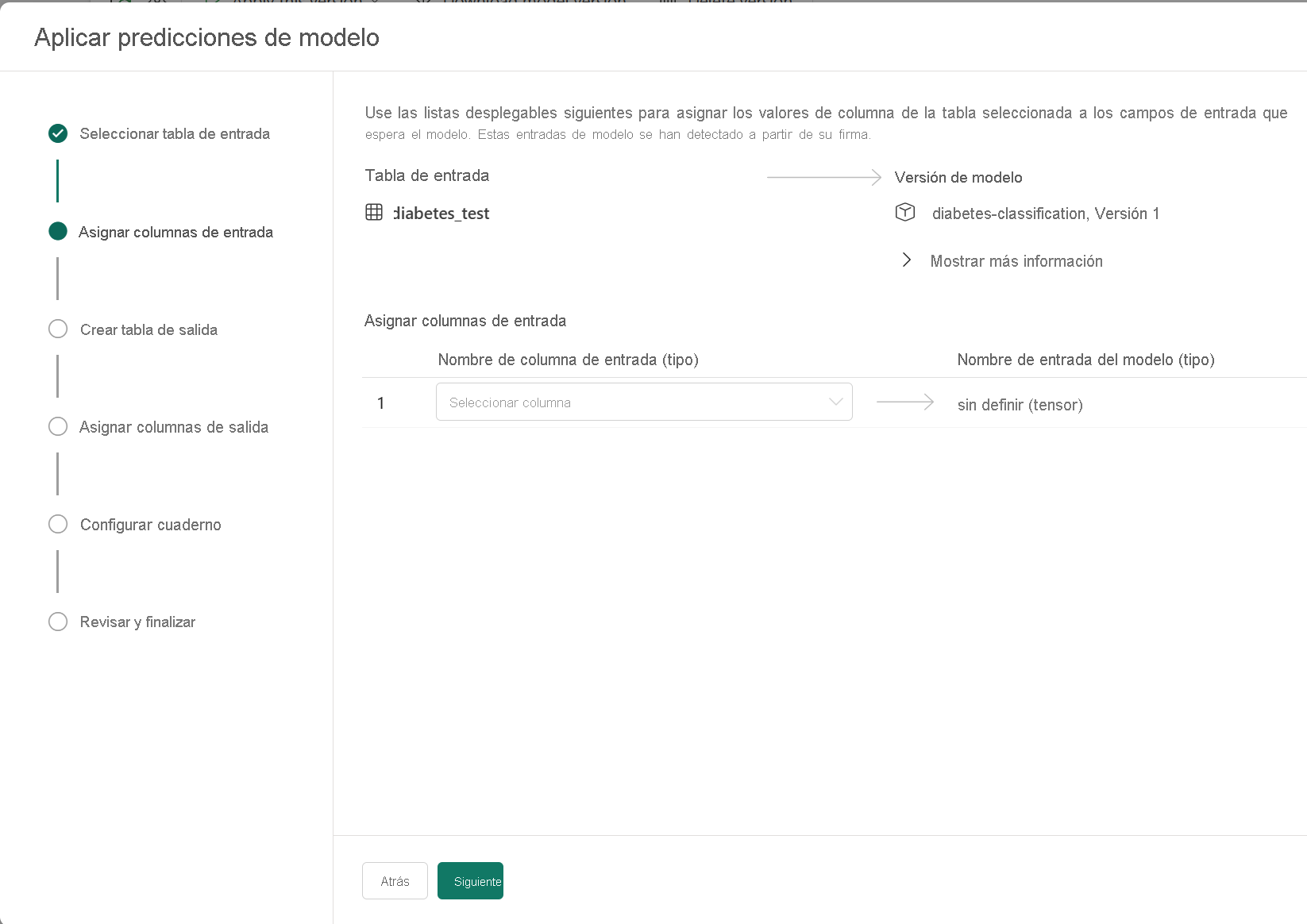
Para cambiar cómo se debería aplicar el modelo, defina las distintas columnas de entrada y salida esperadas.
Exploremos un ejemplo de entrenamiento de un modelo con Scikit-learn y uso del registro automático de MLflow para registrar todos los demás parámetros y métricas. Para registrar manualmente un modelo, establezca log_models=False.
Para definir el esquema de entrada, use la clase Schema de MLflow. Especifique las columnas de entrada esperadas, sus tipos de datos y sus nombres. Del mismo modo, defina el esquema de salida, que normalmente consta de una columna que representa la variable de destino.
Por último, cree el objeto de firma del modelo mediante la clase ModelSignature de MLflow.
from sklearn.tree import DecisionTreeRegressor
from mlflow.models.signature import ModelSignature
from mlflow.types.schema import Schema, ColSpec
with mlflow.start_run():
# Use autologging for all other parameters and metrics
mlflow.autolog(log_models=False)
model = DecisionTreeRegressor(max_depth=5)
# When you fit the model, all other information will be logged
model.fit(X_train, y_train)
# Create the signature manually
input_schema = Schema([
ColSpec("integer", "AGE"),
ColSpec("integer", "SEX"),
ColSpec("double", "BMI"),
ColSpec("double", "BP"),
ColSpec("integer", "S1"),
ColSpec("double", "S2"),
ColSpec("double", "S3"),
ColSpec("double", "S4"),
ColSpec("double", "S5"),
ColSpec("integer", "S6"),
])
output_schema = Schema([ColSpec("integer")])
# Create the signature object
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# Manually log the model
mlflow.sklearn.log_model(model, "model", signature=signature)
Como resultado, el archivo MLmodel almacenado en la carpeta model de salida tendrá el siguiente aspecto:
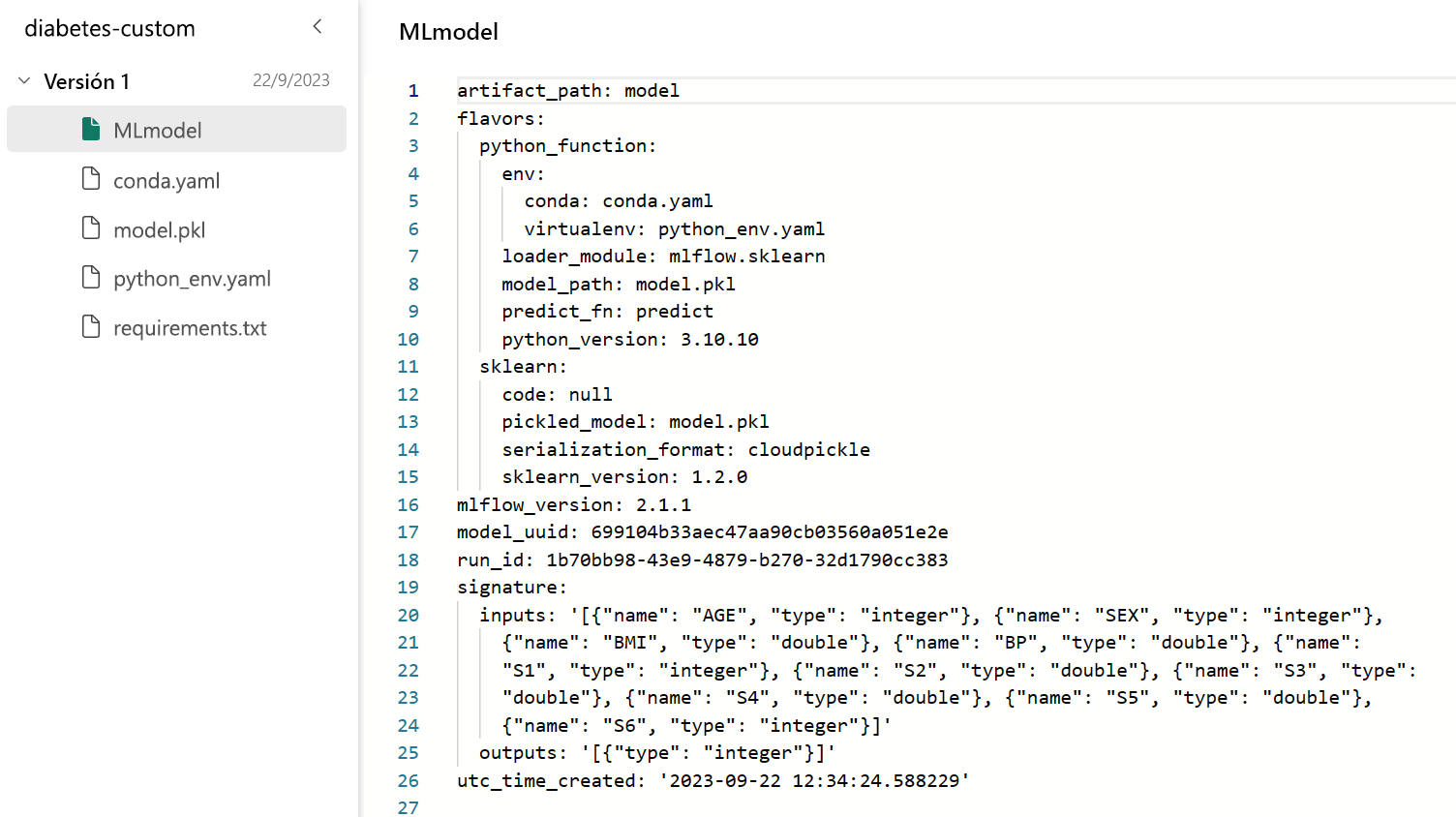
Al aplicar el modelo a través del asistente, se puede apreciar que las columnas de entrada se definen claramente y son más fáciles de alinear con el conjunto de datos para el que desea generar predicciones.
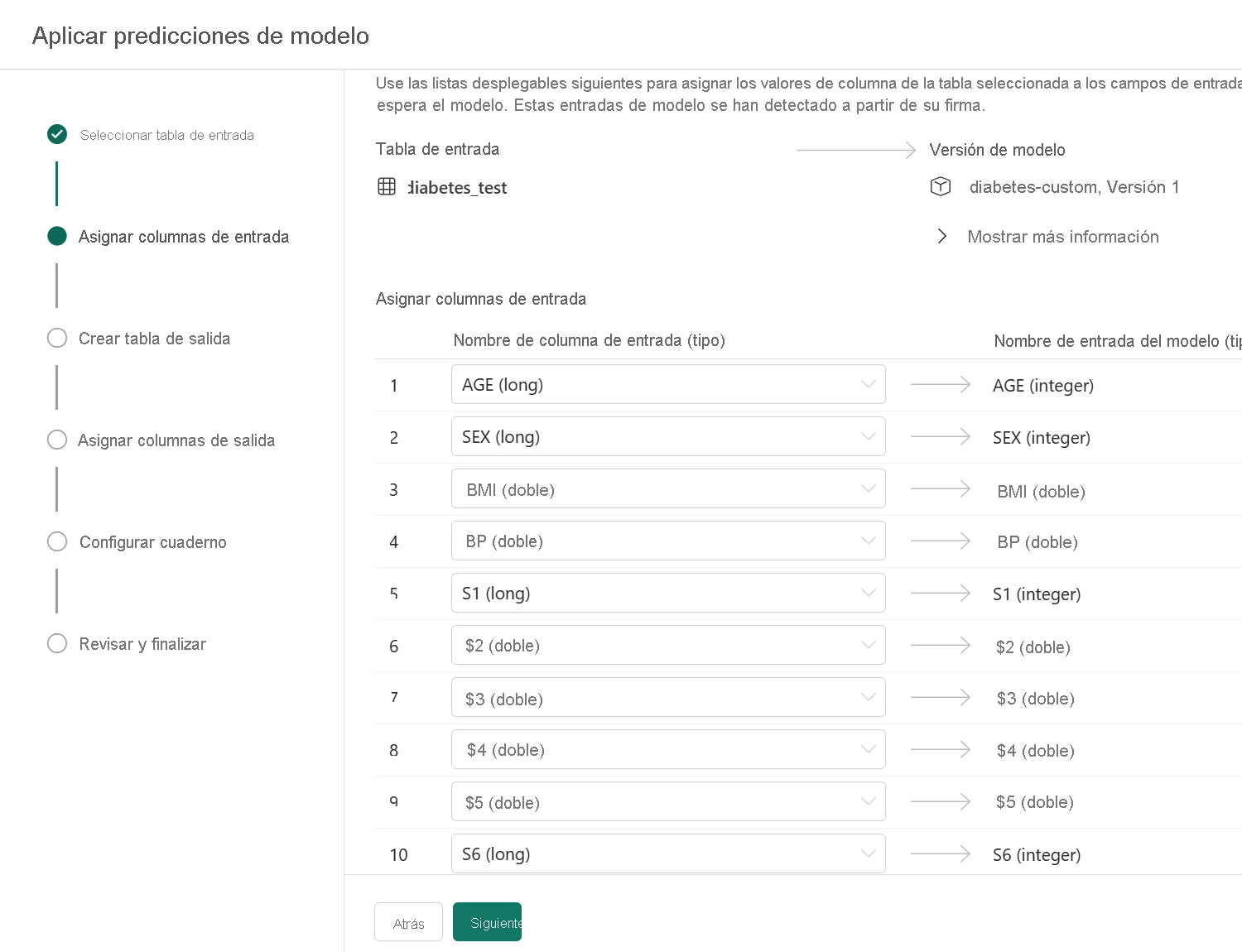
Guardar el modelo en el área de trabajo de Microsoft Fabric
Después de entrenar y realizar un seguimiento de un modelo de Machine Learning con MLflow en Microsoft Fabric, inspeccione el contenido de la carpeta de salida model en la ejecución del experimento. Al explorar específicamente el archivo MLmodel, decida si el modelo se comportará según lo previsto durante la puntuación por lotes.
Para usar un modelo de seguimiento para generar predicciones por lotes, deberá guardarlo. Al guardar un modelo en Microsoft Fabric, es posible hacer lo siguiente:
- Creación de un nuevo modelo
- Agregar una nueva versión a un modelo existente.
Para guardar un modelo, debe especificar la carpeta de salida model, ya que esa carpeta contendrá toda la información necesaria sobre cómo debería comportarse el modelo durante la puntuación por lotes y los propios artefactos del modelo. Normalmente, el modelo entrenado se almacena como un archivo pickle en la misma carpeta.
Para guardar fácilmente un modelo, vaya a la ejecución del experimento correspondiente en la interfaz de usuario.
Como alternativa, se puede guardar un modelo mediante código:
# Get the experiment by name
exp = mlflow.get_experiment_by_name(experiment_name)
# List the last experiment run
last_run = mlflow.search_runs(exp.experiment_id, order_by=["start_time DESC"], max_results=1)
# Retrieve the run ID of the last experiment run
last_run_id = last_run.iloc[0]["run_id"]
# Create a path to the model output folder of the last experiment run
model_uri = "runs:/{}/model".format(last_run_id)
# Register or save the model by specifying the model folder and model name
mv = mlflow.register_model(model_uri, "diabetes-model")