Tipos de aprendizaje automático
Hay varios tipos de aprendizaje automático y debe aplicar el tipo adecuado en función de lo que esté intentando predecir. En el diagrama siguiente se muestra un desglose de los tipos comunes de aprendizaje automático.
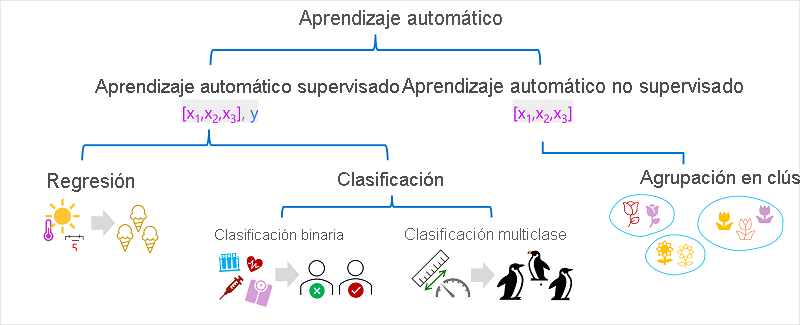
Aprendizaje automático supervisado
El aprendizaje automático supervisado es un término general para los algoritmos de aprendizaje automático en los que los datos de entrenamiento incluyen valores de características y valores de etiqueta conocidos. El aprendizaje automático supervisado se utiliza para entrenar modelos determinando una relación entre las características y las etiquetas en observaciones pasadas, de modo que puedan predecirse etiquetas desconocidas para las características en casos futuros.
Regresión
La regresión es una forma de aprendizaje automático supervisado en la que la etiqueta predicha por el modelo es un valor numérico. Por ejemplo:
- El número de helados vendidos en un día determinado, en función de la temperatura, la precipitación y la velocidad del viento.
- El precio de venta de una propiedad en función de su tamaño en metros cuadrados, el número de habitaciones que contiene y los parámetros socioeconómicos de su ubicación.
- La eficiencia de combustible (en millas por galón) de un coche en función del tamaño de su motor, peso, anchura, altura y longitud.
Clasificación
La clasificación es una forma de aprendizaje automático supervisado en el que la etiqueta representa una categorización o clase. Hay dos escenarios de clasificación comunes.
Clasificación binaria
En la clasificación binaria, la etiqueta determina si el elemento observado es (o no) una instancia de una clase específica. O bien, los modelos de clasificación binaria predicen uno de dos resultados mutuamente excluyentes. Por ejemplo:
- Si un paciente corre riesgo de padecer diabetes en función de parámetros clínicos como el peso, la edad, el nivel de glucosa en sangre, etc.
- Si un cliente bancario dejará de pagar un préstamo en función de sus ingresos, historial crediticio, edad y otros factores.
- Si un cliente de la lista de distribución de correo responderá positivamente a una oferta de marketing en función de los atributos demográficos y las compras anteriores.
En todos estos ejemplos, el modelo predice de forma binaria verdadero/falso o positivo/negativo para una única clase posible.
Clasificación multiclase
La clasificación multiclase amplía la clasificación binaria para predecir una etiqueta que representa una de varias clases posibles. Por ejemplo,
- Las especies de pingüino (Adelie, Gentoo o Chinstrap) se basan en sus mediciones físicas.
- El género de una película (comedia, terror, romance, aventura o ciencia ficción) en función de su reparto, director y presupuesto.
En la mayoría de los escenarios que implican un conjunto conocido de varias clases, la clasificación multiclase se usa para predecir etiquetas mutuamente excluyentes. Por ejemplo, un pingüino no puede ser a la vez Gentoo y Adelie. Sin embargo, también hay algunos algoritmos que puede usar para entrenar modelos de clasificación multietiqueta, en los que puede haber más de una etiqueta válida para una sola observación. Por ejemplo, una película podría clasificarse como ciencia ficción y comedia.
Aprendizaje automático no supervisado
El aprendizaje automático no supervisado implica entrenar modelos mediante datos que solo constan de valores de características sin etiquetas conocidas. Los algoritmos de aprendizaje automático no supervisado determinan las relaciones entre las características de las observaciones de los datos de entrenamiento.
Clustering
La forma más común de aprendizaje automático no supervisado es la agrupación en clústeres. Un algoritmo de agrupación en clústeres identifica similitudes entre observaciones en función de sus características y las agrupa en clústeres discretos. Por ejemplo:
- Agrupa flores similares en función de su tamaño, número de hojas y número de pétalos.
- Identificar grupos de clientes similares en función de los atributos demográficos y el comportamiento de compra.
En cierto modo, la agrupación en clústeres es similar a la clasificación multiclase, ya que clasifica las observaciones en grupos discretos. La diferencia es que cuando se utiliza la clasificación, ya se conocen las clases a las que pertenecen las observaciones de los datos de entrenamiento; por lo tanto, el algoritmo funciona determinando la relación entre las características y la etiqueta de clasificación conocida. En la agrupación en clústeres, no hay una etiqueta de clúster previamente conocida y el algoritmo agrupa las observaciones de datos basándose exclusivamente en la similitud de las características.
En algunos casos, la agrupación en clústeres se usa para determinar el conjunto de clases que existen antes de entrenar un modelo de clasificación. Por ejemplo, puede usar la agrupación en clústeres para segmentar a sus clientes en grupos y, a continuación, analizar esos grupos para identificar y clasificar las diferentes clases de clientes (alto valor: bajo volumen, pequeño comprador frecuente, etc.). A continuación, podría utilizar sus categorizaciones para etiquetar las observaciones en sus resultados de agrupación en clústeres y utilizar los datos etiquetados para entrenar un modelo de clasificación que prediga a qué categoría de cliente podría pertenecer un nuevo cliente.