¿Qué es el aprendizaje automático?
El aprendizaje automático tiene sus orígenes en las estadísticas y el modelado matemático de los datos. La idea fundamental del aprendizaje automático es usar datos de observaciones anteriores para predecir resultados o valores desconocidos. Por ejemplo:
- El propietario de una tienda de helados podría usar una aplicación que combina las ventas históricas y los registros meteorológicos para predecir cuántos helados es probable que vendan en un día determinado, en función de la previsión meteorológica.
- Un médico podría usar datos clínicos de pacientes anteriores para ejecutar pruebas automatizadas que predicen si un nuevo paciente está en riesgo de diabetes en función de factores como el peso, el nivel de glucosa en sangre y otras medidas.
- Un investigador en la Antártica podría utilizar observaciones pasadas automatizar la identificación de diferentes especies de pingüinos (como Adelia, juanito o barbijo ) basándose en las medidas de las aletas, el pico y otros atributos físicos del ave.
Aprendizaje automático como una función
Dado que el aprendizaje automático se basa en matemáticas y estadísticas, es habitual pensar en modelos de aprendizaje automático en términos matemáticos. Fundamentalmente, un modelo de aprendizaje automático es una aplicación de software que encapsula una función para calcular un valor de salida basado en uno o varios valores de entrada. El proceso de definición de esa función se conoce como entrenamiento. Una vez definida la función, puede usarla para predecir nuevos valores en un proceso denominado inferencia.
Vamos a explorar los pasos implicados en el entrenamiento y la inferencia.
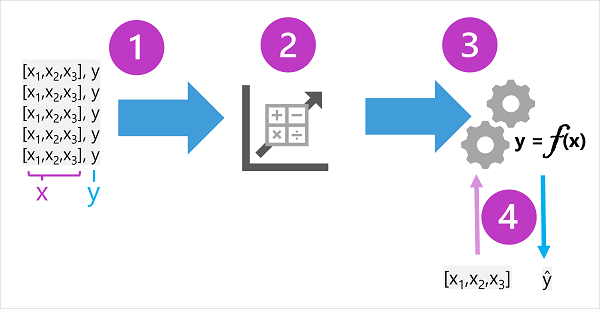
Los datos de entrenamiento constan de observaciones pasadas. En la mayoría de los casos, las observaciones incluyen los atributos observados o características de la cosa observada, y el valor conocido de la cosa para la que se quiere entrenar un modelo de predicción (conocido como la etiqueta).
En términos matemáticos, a menudo verá que se hace referencia a las características usando el nombre abreviado de variable x, y que se hace referencia al etiquetado como y. Normalmente, una observación consta de múltiples valores de características, por lo que x es en realidad un vector (una matriz con múltiples valores), como esto [x1,x2,x3,...].
Para que esto quede más claro, veamos los ejemplos descritos anteriormente:
- En el escenario de ventas de helados, nuestro objetivo es entrenar un modelo que pueda predecir el número de ventas de helados en función del tiempo. Las medidas meteorológicas del día (temperatura, lluvia, velocidad del viento, etc.) serían las características (x) y el número de helados vendidos en cada día sería la etiqueta (y).
- En el escenario médico, el objetivo es predecir si un paciente está o no en riesgo de diabetes en función de sus mediciones clínicas. Las medidas del paciente (peso, nivel de glucosa en sangre, etc.) son las características (x) y la probabilidad de diabetes (por ejemplo, 1 para riesgo, 0 para no riesgo) es la etiqueta (y).
- En el escenario de la investigación en la Antártida, queremos predecir la especie de un pingüino basándonos en sus atributos físicos. Las medidas clave del pingüino (longitud de sus aletas, anchura de su pico, etc.) son las características (x), y la especie (por ejemplo, 0 para Adelia, 1 para juanito, o 2 para barbijo) es la etiqueta (y).
Se aplica un algoritmo a los datos para intentar determinar una relación entre las características y el etiquetado, y generalizar esa relación como un cálculo que puede realizarse sobre x para calcular y. El algoritmo específico utilizado depende del tipo de problema de predicción que esté intentando resolver (más sobre esto más adelante), pero el principio básico es intentar ajustar una función a los datos, en los que los valores de las características puedan usarse para calcular la etiqueta.
El resultado del algoritmo es un modelo que encapsula el cálculo derivado por el algoritmo como una función, llamémosla f. En notación matemática:
y = f(x)
Ahora que se ha completado la fase de entrenamiento, se puede usar el modelo entrenado para la inferencia. El modelo es básicamente un programa de software que encapsula la función generada por el proceso de entrenamiento. Puede introducir un conjunto de valores de características y recibir como salida una predicción de la etiqueta correspondiente. Dado que la salida del modelo es una predicción calculada por la función y no un valor observado, a menudo verá la salida de la función que se muestra como ŷ.