Ajuste de modelos base en Azure Machine Learning
Para ajustar un modelo base del catálogo de modelos de Azure Machine Learning, puede usar la interfaz de usuario proporcionada en Estudio, el SDK de Python o la CLI de Azure.
Preparación de los datos y el proceso
Para poder ajustar un modelo base con el fin de mejorar el rendimiento del modelo, debe preparar los datos de entrenamiento y crear un clúster de proceso de GPU.
Sugerencia
Cuando crea un clúster de proceso de GPU en Azure Machine Learning, se crea automáticamente una máquina virtual optimizada para GPU. Consulte más información sobre los tamaños de máquina virtual con GPU disponibles en Azure.
Los datos de entrenamiento pueden tener el formato JSONL (JSON Lines), CSV o TSV. Los requisitos de los datos varían en función de la tarea específica para la que pretende ajustar el modelo.
| Tarea | Requisitos del conjunto de datos |
|---|---|
| Clasificación de textos | Dos columnas: Sentence (cadena) y Label (entero/cadena) |
| Clasificación de tokens | Dos columnas: Token (cadena) y Tag (cadena) |
| Respuesta a preguntas | Cinco columnas: Question (cadena), Context (cadena), Answers (cadena), Answers_start (entero) y Answers_text (cadena) |
| Resumen | Dos columnas: Document (cadena) y Summary (cadena) |
| Traducción | Dos columnas: Source_language (cadena) y Target_language (cadena) |
Nota:
El conjunto de datos debe tener los requisitos necesarios. No obstante, puede usar nombres de columna diferentes y asignar la columna al requisito adecuado.
Cuando tenga listo el conjunto de datos y el clúster de proceso, puede configurar un trabajo de ajuste en Azure Machine Learning.
Elección de un modelo base
Para explorar todos los modelos base, vaya al catálogo de modelos en Estudio de Azure Machine Learning.
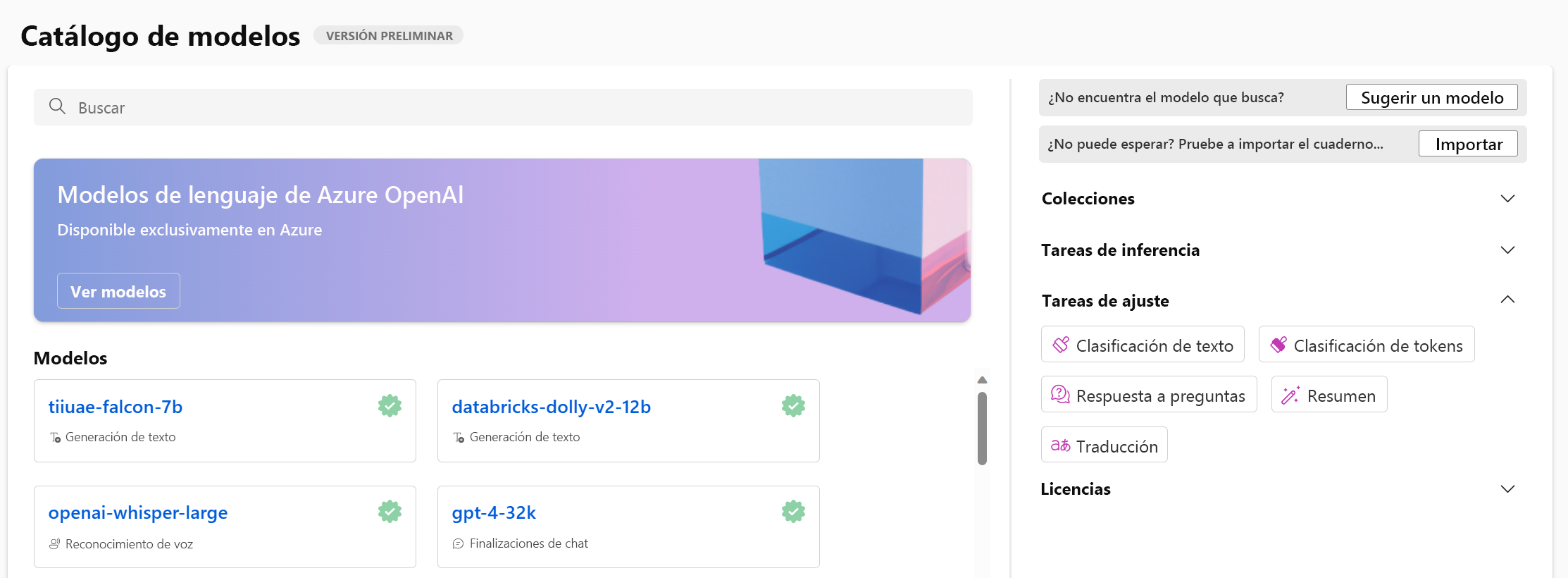
Puede filtrar los modelos disponibles en función de la tarea para la que desea ajustar un modelo. Por tarea, tiene varias opciones de modelos base entre los que elegir. Cuando esté decidiendo entre modelos base para una tarea, puede examinar la descripción del modelo y la tarjeta de modelo a la que se hace referencia.
Los siguientes son algunos aspectos que puede tener en cuenta a la hora de decidirse por un modelo base antes de ajustarlo:
- Funcionalidad del modelo: evalúe la funcionalidad del modelo base y hasta qué punto está en consonancia con la tarea. Por ejemplo, un modelo como BERT es mejor para el reconocimiento de textos cortos.
- Datos del entrenamiento previo: tenga en cuenta el conjunto de datos que se ha usado para entrenar previamente el modelo base. Por ejemplo, GPT-2 se entrena con contenido de Internet sin filtrar que puede dar lugar a sesgos.
- Limitaciones y sesgos: tenga en cuenta las limitaciones o sesgos que pueda haber en el modelo base.
- Compatibilidad con idiomas: explore qué modelos ofrecen compatibilidad con idiomas específicos o funcionalidad multilingüe que necesite para su caso de uso.
Sugerencia
Aunque Estudio de Azure Machine Learning proporciona descripciones para cada modelo base del catálogo de modelos, también puede encontrar más información sobre cada modelo a través de la tarjeta de modelo correspondiente. A las tarjetas de modelo se hace referencia en la información general de cada modelo y se hospedan en el sitio web de Hugging Face.
Configuración de un trabajo de ajuste
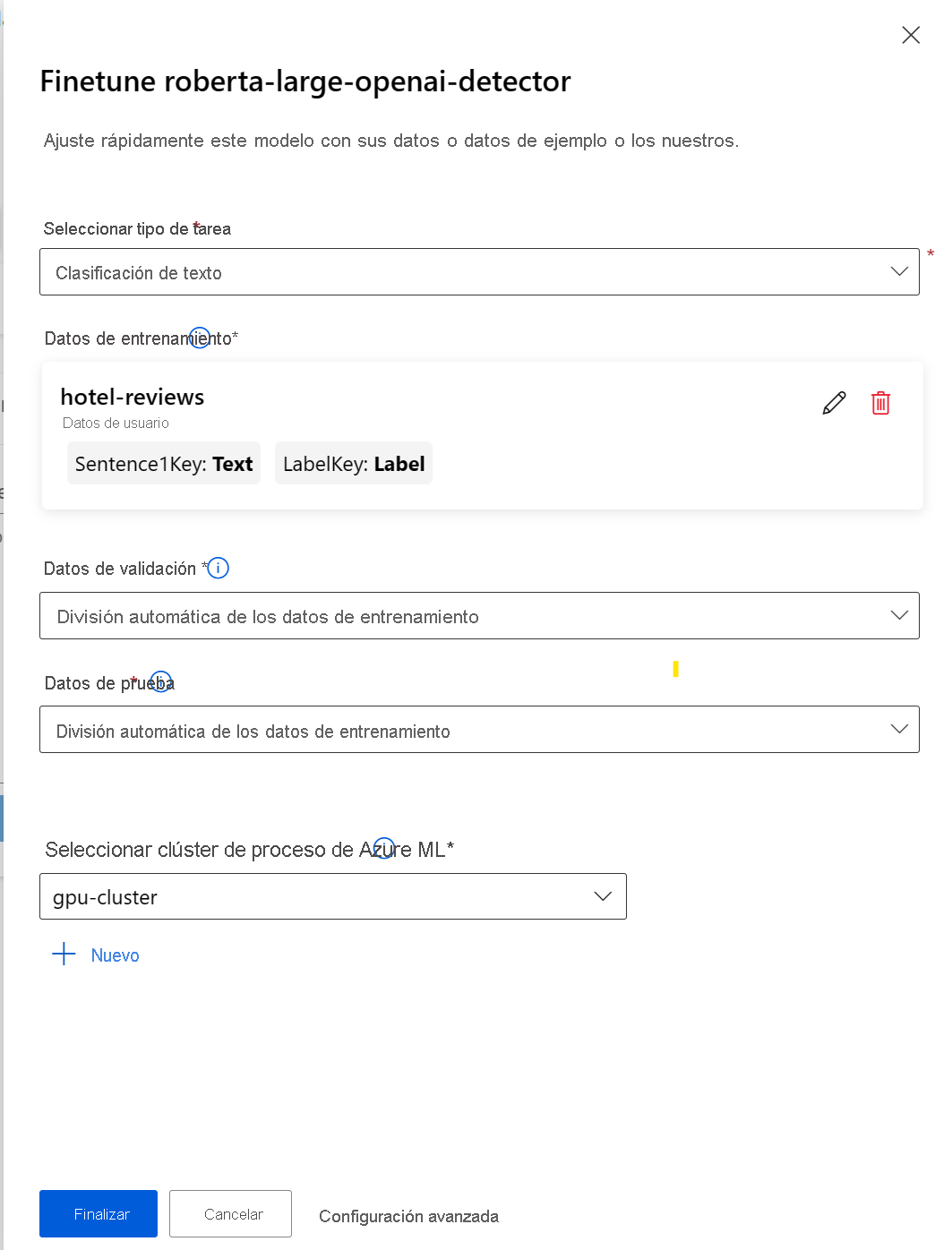
Para configurar un trabajo de ajuste con Estudio de Azure Machine Learning, siga estos pasos:
- Elija un modelo base.
- Seleccione Ajustar para abrir un elemento emergente que le ayude a configurar el trabajo.
- Seleccione el tipo de tarea.
- Seleccione los datos de entrenamiento y asigne las columnas de los datos de entrenamiento a los requisitos del conjunto de datos.
- Permita que Azure Machine Learning divida automáticamente los datos de entrenamiento para crear un conjunto de datos de validación y prueba, o bien proporcione los suyos propios.
- Seleccione un clúster de proceso de GPU administrado por Azure Machine Learning.
- Seleccione Finalizar para enviar el trabajo de ajuste.
Sugerencia
Opcionalmente, puede explorar la configuración avanzada para cambiar datos como el nombre del trabajo de ajuste y los parámetros de la tarea (por ejemplo, la velocidad de aprendizaje).
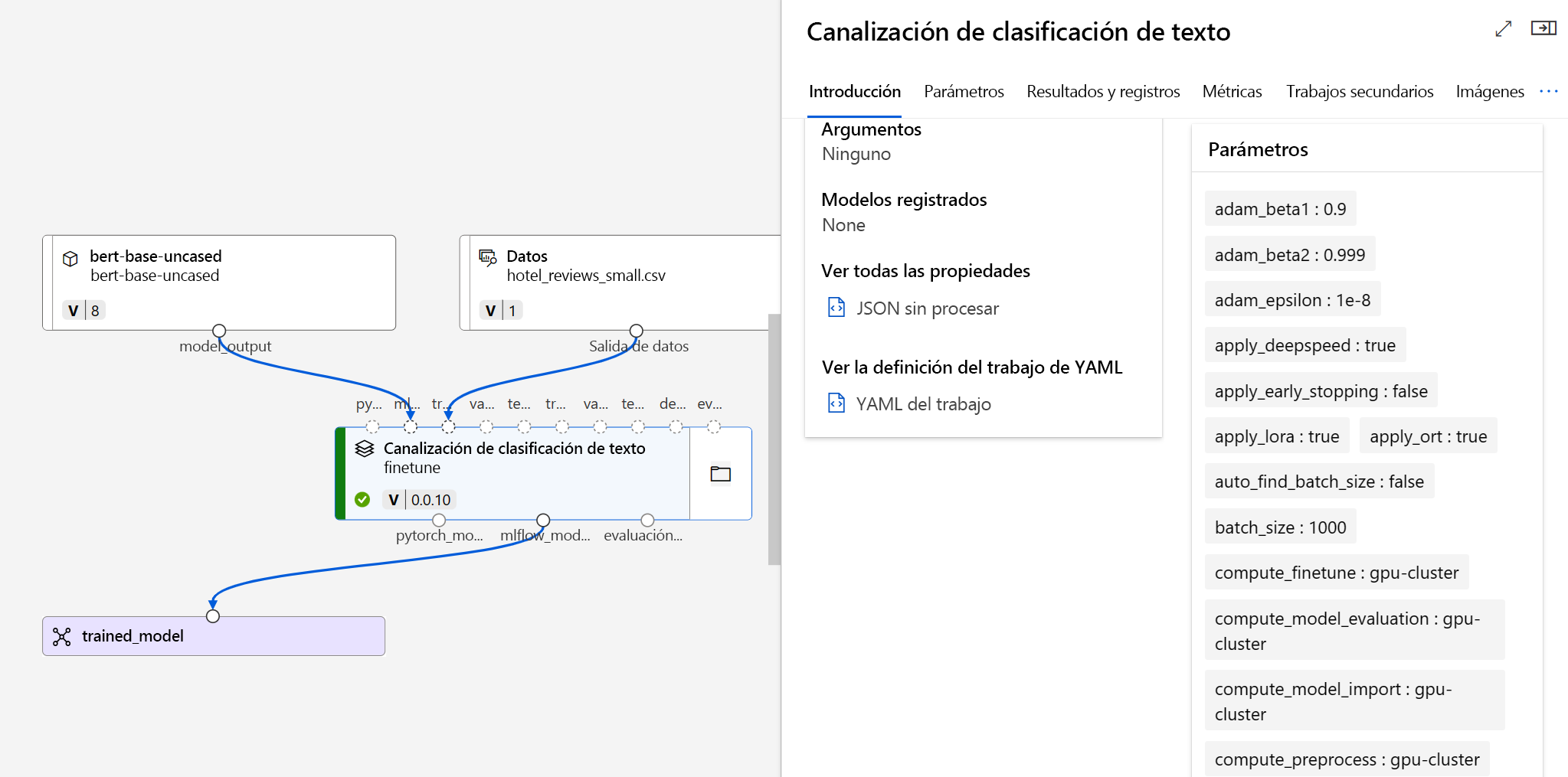
Después de enviar el trabajo de ajuste, se crea un trabajo de canalización para entrenar el modelo. Puede revisar todas las entradas y recopilar el modelo a partir de las salidas del trabajo.