Carga de datos para la exploración
La carga y exploración de datos son los primeros pasos de cualquier proyecto de ciencia de datos. Implican comprender la estructura, el contenido y el origen de los datos, que son fundamentales para el análisis posterior.
Después de conectarse a un origen de datos, puede guardar los datos en un lago de datos de Microsoft Fabric. Puede usar lagos de datos como ubicación central para almacenar cualquier archivo estructurado, semiestructurado y no estructurado. Después, puede conectarse fácilmente al lago de datos siempre que quiera acceder a los datos para su exploración o transformación.
Carga de datos mediante cuadernos
Los cuadernos de Microsoft Fabric facilitan el proceso de control de los recursos de datos. Una vez que los recursos de datos se encuentran en el almacén de lago, puede generar fácilmente código en el cuaderno para ingerir estos recursos.
Considere un escenario en el que un ingeniero de datos ya ha transformado los datos de los clientes y los ha almacenado en el almacén de lago. Un científico de datos puede cargar fácilmente los datos mediante cuadernos para una exploración adicional para crear un modelo de aprendizaje automático. Esto permite que el trabajo se inicie inmediatamente, independientemente de si esto implica manipulaciones de datos adicionales, análisis de datos exploratorios o desarrollo de modelos.
Vamos a crear un archivo parquet de ejemplo para ilustrar la operación de carga. El código de PySpark siguiente crea un marco de datos de los datos del cliente y la escribe en un archivo Parquet en el almacén de lago.
Apache Parquet es un formato de almacenamiento de datos orientado a columnas de código abierto. Está diseñado para una recuperación y almacenamiento de datos eficientes, y se conoce por su alto rendimiento y compatibilidad con muchos marcos de procesamiento de datos.
from pyspark.sql import Row
Customer = Row("firstName", "lastName", "email", "loyaltyPoints")
customer_1 = Customer('John', 'Smith', 'john.smith@contoso.com', 15)
customer_2 = Customer('Anna', 'Miller', 'anna.miller@contoso.com', 65)
customer_3 = Customer('Sam', 'Walters', 'sam@contoso.com', 6)
customer_4 = Customer('Mark', 'Duffy', 'mark@contoso.com', 78)
customers = [customer_1, customer_2, customer_3, customer_4]
df = spark.createDataFrame(customers)
df.write.parquet("<path>/customers")
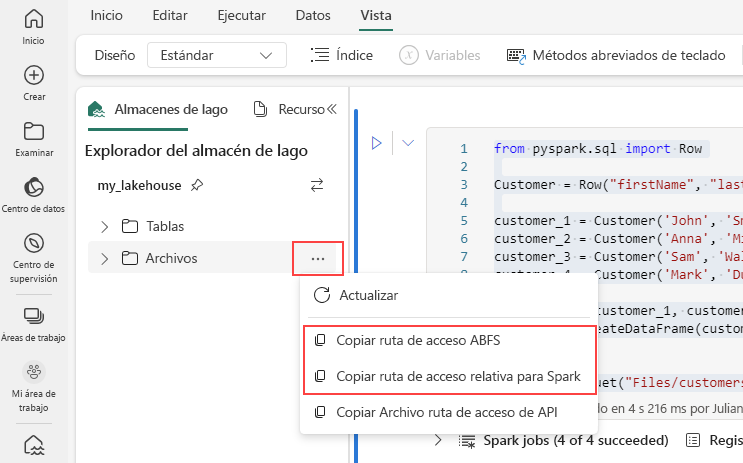
Para generar la ruta de acceso para el archivo Parquet, seleccione los puntos suspensivos en el explorador del almacén de lago y, a continuación, elija Copiar la ruta de acceso de ABFS o Copiar la ruta de acceso relativa para Spark. Si escribe código de Python, puede usar la opción Copiar API de archivo o Copiar la ruta de acceso de ABFS.
El código siguiente carga el archivo parquet en un DataFrame.
df = spark.read.parquet("<path>/customers")
display(df)
Como alternativa, también puede generar el código para cargar los datos en el cuaderno automáticamente. Elija el archivo de datos y, a continuación, seleccione Cargar datos. Después, deberá elegir la API que desea usar.
Aunque el archivo parquet del ejemplo anterior se almacena en el lago de datos, también es posible cargar datos de orígenes externos como Azure Blob Storage.
account_name = "<account_name>"
container_name = "<container_name>"
relative_path = "<relative_path>"
sas_token = "<sas_token>"
wasbs = f'wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}?{blob_sas_token}'
df = spark.read.parquet(wasbs)
df.show()
Puede seguir pasos similares para cargar otros tipos de archivo como los archivos .csv, .jsony .txt. Simplemente reemplace el método .parquet por el método adecuado para el tipo de archivo, por ejemplo:
# For CSV files
df_csv = spark.read.csv('<path>')
# For JSON files
df_json = spark.read.json('<path>')
# For text files
df_text = spark.read.text('<path>')
Sugerencia
Obtenga más información sobre cómo ingerir y organizar datos de varios orígenes con Microsoft Fabric.